mirror of
https://github.com/kamranahmedse/developer-roadmap.git
synced 2026-03-13 02:01:57 +08:00
Compare commits
33 Commits
feat/stop-
...
feat/proje
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6a7fc4ca76 | ||
|
|
56e7aa5687 | ||
|
|
b92abb127d | ||
|
|
a9b9077d07 | ||
|
|
65f51d9243 | ||
|
|
824c796029 | ||
|
|
e58c30f74f | ||
|
|
36a66fa901 | ||
|
|
fbf124aedf | ||
|
|
7e100434f7 | ||
|
|
7adbdc3fb1 | ||
|
|
e79bfca074 | ||
|
|
989f7ad5c1 | ||
|
|
dd5232f2f8 | ||
|
|
851a0381b6 | ||
|
|
88d783680b | ||
|
|
a1aba2e026 | ||
|
|
01eb7b2f0f | ||
|
|
94ce774586 | ||
|
|
bbcd7e18e5 | ||
|
|
298b137a7d | ||
|
|
ae58fa2a2a | ||
|
|
bcc85dcebe | ||
|
|
44a7a01e3c | ||
|
|
e3b6bacbc4 | ||
|
|
8c615084d3 | ||
|
|
9f446764bc | ||
|
|
bf80d3f052 | ||
|
|
09b63442dc | ||
|
|
af4b04a510 | ||
|
|
839d92db29 | ||
|
|
2193565071 | ||
|
|
1121993c15 |
@@ -412,8 +412,14 @@
|
||||
},
|
||||
"Bz-BkfzsDHAbAw3HD7WCd": {
|
||||
"title": "MVI",
|
||||
"description": "",
|
||||
"links": []
|
||||
"description": "The **MVI** `Model-View-Intent` pattern is a reactive architectural pattern, similar to **MVVM** and **MVP**, focusing on immutability and handling states in unidirectional cycles. The data flow is unidirectional: Intents update the Model's state through the `ViewModel`, and then the View reacts to the new state. This ensures a clear and predictable cycle between logic and the interface.\n\n* Model: Represents the UI state. It is immutable and contains all the necessary information to represent a screen.\n* View: Displays the UI state and receives the user's intentions.\n* Intent: The user's intentions trigger state updates, managed by the `ViewModel`.\n\nVisit the following resources to learn more:",
|
||||
"links": [
|
||||
{
|
||||
"title": "MVI with Kotlin",
|
||||
"url": "https://proandroiddev.com/mvi-architecture-with-kotlin-flows-and-channels-d36820b2028d",
|
||||
"type": "article"
|
||||
}
|
||||
]
|
||||
},
|
||||
"pSU-NZtjBh-u0WKTYfjk_": {
|
||||
"title": "MVVM",
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1428,8 +1428,19 @@
|
||||
},
|
||||
"PUgPgpKio4Npzs86qEXa7": {
|
||||
"title": "Perimiter vs DMZ vs Segmentation",
|
||||
"description": "Perimeter and DMZ (Demilitarized Zone) segmentation is a crucial aspect of network security that helps protect internal networks by isolating them from external threats. In this section, we will discuss the concepts of perimeter and DMZ segmentation, and how they can be used to enhance the security of your organization.\n\nPerimeter Segmentation\n----------------------\n\nPerimeter segmentation is a network security technique that involves isolating an organization's internal networks from the external, untrusted network (typically the internet). The goal is to create a protective barrier to limit the access of external attackers to the internal network, and minimize the risk of data breaches and other security threats.\n\nTo achieve this, perimeter segmentation typically involves the use of network security appliances such as firewalls, intrusion detection systems (IDS), and intrusion prevention systems (IPS). These devices act as gatekeepers, enforcing security policies and filtering network traffic to protect the internal network from malicious activity.\n\nDMZ Segmentation\n----------------\n\nThe DMZ is a specially isolated part of the network situated between the internal network and the untrusted external network. DMZ segmentation involves creating a separate, secure area for hosting public-facing services (such as web servers, mail servers, and application servers) that need to be accessible to external users.\n\nThe primary purpose of the DMZ is to provide an additional layer of protection for internal networks. By keeping public-facing services in the DMZ and isolated from the internal network, you can prevent external threats from directly targeting your organization's most sensitive assets.\n\nTo implement a DMZ in your network, you can use devices such as firewalls, routers, or dedicated network security appliances. Properly configured security policies and access controls help ensure that only authorized traffic flows between the DMZ and the internal network, while still allowing necessary external access to the DMZ services.\n\nKey Takeaways\n-------------\n\n* Perimeter and DMZ segmentation are crucial security techniques that help protect internal networks from external threats.\n* Perimeter segmentation involves isolating an organization's internal networks from the untrusted external network, typically using security appliances such as firewalls, IDS, and IPS.\n* DMZ segmentation involves creating a separate, secure area within the network for hosting public-facing services that need to be accessible to external users while maintaining additional security for internal assets.\n* Implementing proper network segmentation and security policies can significantly reduce the risk of data breaches and other security threats.",
|
||||
"links": []
|
||||
"description": "Perimeter and DMZ (Demilitarized Zone) segmentation is a crucial aspect of network security that helps protect internal networks by isolating them from external threats. In this section, we will discuss the concepts of perimeter and DMZ segmentation, and how they can be used to enhance the security of your organization.\n\nPerimeter Segmentation\n----------------------\n\nPerimeter segmentation is a network security technique that involves isolating an organization's internal networks from the external, untrusted network (typically the internet). The goal is to create a protective barrier to limit the access of external attackers to the internal network, and minimize the risk of data breaches and other security threats.\n\nTo achieve this, perimeter segmentation typically involves the use of network security appliances such as firewalls, intrusion detection systems (IDS), and intrusion prevention systems (IPS). These devices act as gatekeepers, enforcing security policies and filtering network traffic to protect the internal network from malicious activity.\n\nDMZ Segmentation\n----------------\n\nThe DMZ is a specially isolated part of the network situated between the internal network and the untrusted external network. DMZ segmentation involves creating a separate, secure area for hosting public-facing services (such as web servers, mail servers, and application servers) that need to be accessible to external users.\n\nThe primary purpose of the DMZ is to provide an additional layer of protection for internal networks. By keeping public-facing services in the DMZ and isolated from the internal network, you can prevent external threats from directly targeting your organization's most sensitive assets.\n\nTo implement a DMZ in your network, you can use devices such as firewalls, routers, or dedicated network security appliances. Properly configured security policies and access controls help ensure that only authorized traffic flows between the DMZ and the internal network, while still allowing necessary external access to the DMZ services.\n\nKey Takeaways\n-------------\n\n* Perimeter and DMZ segmentation are crucial security techniques that help protect internal networks from external threats.\n* Perimeter segmentation involves isolating an organization's internal networks from the untrusted external network, typically using security appliances such as firewalls, IDS, and IPS.\n* DMZ segmentation involves creating a separate, secure area within the network for hosting public-facing services that need to be accessible to external users while maintaining additional security for internal assets.\n* Implementing proper network segmentation and security policies can significantly reduce the risk of data breaches and other security threats.\n\nLearn more from the following resources:",
|
||||
"links": [
|
||||
{
|
||||
"title": "Best practice for network segmentation",
|
||||
"url": "https://github.com/sergiomarotco/Network-segmentation-cheat-sheet",
|
||||
"type": "opensource"
|
||||
},
|
||||
{
|
||||
"title": "OWASP Network segmentation Cheat Sheet",
|
||||
"url": "https://github.com/OWASP/CheatSheetSeries/blob/master/cheatsheets/Network_Segmentation_Cheat_Sheet.md#network-segmentation-cheat-sheet",
|
||||
"type": "opensource"
|
||||
}
|
||||
]
|
||||
},
|
||||
"HavEL0u65ZxHt92TfbLzk": {
|
||||
"title": "Core Concepts of Zero Trust",
|
||||
|
||||
@@ -378,12 +378,17 @@
|
||||
"links": []
|
||||
},
|
||||
"AaRZiItRcn8fYb5R62vfT": {
|
||||
"title": "Assembly",
|
||||
"description": "**Assembly** is a low-level programming language, often used for direct hardware manipulation, real-time systems, and to write performance-critical code. It provides a strong correspondence between its instructions and the architecture's machine-code instructions, since it directly represents the specific commands of the computer's CPU structure. However, it's closer to machine language (binary code) than to human language, which makes it difficult to read and understand. The syntax varies greatly, which depends upon the CPU architecture for which it's designed, thus Assembly language written for one type of processor can't be used on another. Despite its complexity, time-intensive coding process and machine-specific nature, Assembly language is still utilized for speed optimization and hardware manipulation where high-level languages may not be sufficient.",
|
||||
"title": "GDScript",
|
||||
"description": "GDScript is a high-level, dynamically-typed programming language designed specifically for the Godot Engine, an open-source game development platform. It is tailored for ease of use and rapid development of game logic and functionality. GDScript features a syntax similar to Python, which simplifies learning and coding for developers familiar with Python, while providing direct access to Godot's rich set of built-in functions and game-specific APIs. The language integrates closely with Godot's scene system and scripting environment, enabling developers to create and manipulate game objects, handle input, and control game behavior efficiently.\n\nLearn more from the following resources:",
|
||||
"links": [
|
||||
{
|
||||
"title": "Code walkthrough of a game written in x64 assembly",
|
||||
"url": "https://www.youtube.com/watch?v=WUoqlp30M78",
|
||||
"title": "GDScript Website",
|
||||
"url": "https://gdscript.com/",
|
||||
"type": "article"
|
||||
},
|
||||
{
|
||||
"title": "How to program in Godot - GDScript Tutorial",
|
||||
"url": "https://www.youtube.com/watch?v=e1zJS31tr88",
|
||||
"type": "video"
|
||||
}
|
||||
]
|
||||
|
||||
@@ -336,11 +336,6 @@
|
||||
"url": "https://www.programiz.com/dsa",
|
||||
"type": "article"
|
||||
},
|
||||
{
|
||||
"title": "DSA Course by Google",
|
||||
"url": "https://www.udacity.com/course/data-structures-and-algorithms-in-python--ud513",
|
||||
"type": "article"
|
||||
},
|
||||
{
|
||||
"title": "Explore top posts about Algorithms",
|
||||
"url": "https://app.daily.dev/tags/algorithms?ref=roadmapsh",
|
||||
|
||||
@@ -449,8 +449,14 @@
|
||||
},
|
||||
"fm8oUyNvfdGWTgLsYANUr": {
|
||||
"title": "Environment Variables",
|
||||
"description": "",
|
||||
"links": []
|
||||
"description": "Environment variables can be used to customize various aspects of Terraform. You can set these variables to change the default behaviour of terraform such as increase verbosity, update log file path, set workspace, etc. Envrionment variables are optional and terraform does not need them by default.\n\nLearn more from the following resources:",
|
||||
"links": [
|
||||
{
|
||||
"title": "Environment Variables",
|
||||
"url": "https://developer.hashicorp.com/terraform/cli/config/environment-variables",
|
||||
"type": "article"
|
||||
}
|
||||
]
|
||||
},
|
||||
"rdphcVd-Vq972y4H8CxIj": {
|
||||
"title": "Variable Definition File",
|
||||
@@ -470,13 +476,30 @@
|
||||
},
|
||||
"U2n2BtyUrOFLnw9SZYV_w": {
|
||||
"title": "Validation Rules",
|
||||
"description": "",
|
||||
"links": []
|
||||
"description": "Validation rules can be used to specify custom validations to a variable. The motive of adding validation rules is to make the variable comply with the rules. The validation rules can be added using a `validation` block.\n\nLearn more from the following resources:",
|
||||
"links": [
|
||||
{
|
||||
"title": "Custom Validation Rules",
|
||||
"url": "https://developer.hashicorp.com/terraform/language/values/variables#custom-validation-rules",
|
||||
"type": "article"
|
||||
}
|
||||
]
|
||||
},
|
||||
"1mFih8uFs3Lc-1PLgwiAU": {
|
||||
"title": "Local Values",
|
||||
"description": "",
|
||||
"links": []
|
||||
"description": "Local values can be understood as a name assigned to any expression to use it multiple times directly by the name in your terraform module. Local values are referred to as locals and can be declared using the `locals` block. Local values can be a literal constants, resource attributes, variables, or other local values. Local values are helpful to define expressions or values that you need to use multiple times in the module as it allows the value to be updated easily just by updating the local value. A local value can be accessed using the `local` argument like `local.<value_name>`.\n\nLearn more from the following resources:",
|
||||
"links": [
|
||||
{
|
||||
"title": "Local Values",
|
||||
"url": "https://developer.hashicorp.com/terraform/language/values/locals",
|
||||
"type": "article"
|
||||
},
|
||||
{
|
||||
"title": "@Article@Terraform Locals",
|
||||
"url": "https://spacelift.io/blog/terraform-locals",
|
||||
"type": "article"
|
||||
}
|
||||
]
|
||||
},
|
||||
"7GK4fQf1FRKrZgZkxNahj": {
|
||||
"title": "Outputs",
|
||||
|
||||
@@ -53,7 +53,7 @@
|
||||
},
|
||||
"2NlgbLeLBYwZX2u2rKkIO": {
|
||||
"title": "BJ Fogg's Behavior Model",
|
||||
"description": "B.J. Fogg, a renowned psychologist, and researcher at Stanford University, proposed the [Fogg Behavior Model (FBM)](https://www.behaviormodel.org/). This insightful model helps UX designers understand and influence user behavior by focusing on three core elements. These key factors are motivation, ability, and triggers.\n\n* **Motivation**: This element emphasizes the user's desire to perform a certain action or attain specific outcomes. Motivation can be linked to three core elements specified as sensation (pleasure/pain), anticipation (hope/fear), and social cohesion (belonging/rejection).\n \n* **Ability**: Ability refers to the user's capacity, both physical and mental, to perform desired actions. To enhance the ability of users, UX designers should follow the principle of simplicity. The easier it is to perform an action, the more likely users will engage with the product. Some factors to consider are time, financial resources, physical efforts, and cognitive load.\n \n* **Triggers**: Triggers are the cues, notifications, or prompts that signal users to take an action. For an action to occur, triggers should be presented at the right time when the user has adequate motivation and ability.\n \n\nUX designers should strive to find the balance between these three factors to facilitate the desired user behavior. By understanding your audience and their needs, implementing clear and concise triggers, and minimizing the effort required for action, the FBM can be an effective tool for designing user-centered products.",
|
||||
"description": "B.J. Fogg, a renowned psychologist, and researcher at Stanford University, proposed the [Fogg Behavior Model (FBM)](https://www.behaviormodel.org/). This insightful model helps UX designers understand and influence user behavior by focusing on three core elements. These key factors are motivation, ability, and prompts.\n\n* **Motivation**: This element emphasizes the user's desire to perform a certain action or attain specific outcomes. Motivation can be linked to three core elements specified as sensation (pleasure/pain), anticipation (hope/fear), and social cohesion (belonging/rejection).\n \n* **Ability**: Ability refers to the user's capacity, both physical and mental, to perform desired actions. To enhance the ability of users, UX designers should follow the principle of simplicity. The easier it is to perform an action, the more likely users will engage with the product. Some factors to consider are time, financial resources, physical efforts, and cognitive load.\n \n* **Prompts**: Prompts are the cues, notifications, or triggers that signal users to take an action. For an action to occur, prompts should be presented at the right time when the user has adequate motivation and ability.\n \n\nUX designers should strive to find the balance between these three factors to facilitate the desired user behavior. By understanding your audience and their needs, implementing clear and concise prompts, and minimizing the effort required for action, the FBM can be an effective tool for designing user-centered products.",
|
||||
"links": [
|
||||
{
|
||||
"title": "meaning of BJ fogg's behavior model",
|
||||
|
||||
31
src/api/leaderboard.ts
Normal file
31
src/api/leaderboard.ts
Normal file
@@ -0,0 +1,31 @@
|
||||
import { type APIContext } from 'astro';
|
||||
import { api } from './api.ts';
|
||||
|
||||
export type LeadeboardUserDetails = {
|
||||
id: string;
|
||||
name: string;
|
||||
avatar?: string;
|
||||
count: number;
|
||||
};
|
||||
|
||||
export type ListLeaderboardStatsResponse = {
|
||||
streaks: {
|
||||
active: LeadeboardUserDetails[];
|
||||
lifetime: LeadeboardUserDetails[];
|
||||
};
|
||||
projectSubmissions: {
|
||||
currentMonth: LeadeboardUserDetails[];
|
||||
lifetime: LeadeboardUserDetails[];
|
||||
};
|
||||
};
|
||||
|
||||
export function leaderboardApi(context: APIContext) {
|
||||
return {
|
||||
listLeaderboardStats: async function () {
|
||||
return api(context).get<ListLeaderboardStatsResponse>(
|
||||
`${import.meta.env.PUBLIC_API_URL}/v1-list-leaderboard-stats`,
|
||||
{},
|
||||
);
|
||||
},
|
||||
};
|
||||
}
|
||||
@@ -182,7 +182,12 @@ export function AccountStreak(props: AccountStreakProps) {
|
||||
</div>
|
||||
|
||||
<p className="-mt-[0px] mb-[1.75px] text-center text-xs tracking-wide text-slate-600">
|
||||
Visit every day to keep your streak alive!
|
||||
Visit every day to keep your streak going!
|
||||
</p>
|
||||
<p className='text-xs mt-1.5 text-center'>
|
||||
<a href="/leaderboard" className="text-purple-400 hover:underline underline-offset-2">
|
||||
See how you compare to others
|
||||
</a>
|
||||
</p>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
@@ -47,7 +47,7 @@ export function DashboardAiRoadmaps(props: DashboardAiRoadmapsProps) {
|
||||
<>
|
||||
{roadmaps.map((roadmap) => (
|
||||
<a
|
||||
href={`/r/${roadmap.slug}`}
|
||||
href={`/ai/${roadmap.slug}`}
|
||||
className="relative rounded-md border bg-white p-2.5 text-left text-sm shadow-sm truncate hover:border-gray-400 hover:bg-gray-50"
|
||||
>
|
||||
{roadmap.title}
|
||||
|
||||
@@ -27,10 +27,10 @@ export function DashboardBookmarkCard(props: DashboardBookmarkCardProps) {
|
||||
<a
|
||||
href={url}
|
||||
key={resourceId}
|
||||
className="group relative flex w-full items-center gap-2 text-left text-sm hover:text-black hover:underline"
|
||||
className="group relative flex flex-row items-center gap-2 rounded-md border border-gray-300 bg-white px-1.5 py-2 text-left text-sm transition-all hover:border-gray-400"
|
||||
>
|
||||
<Bookmark className="size-4 fill-current text-gray-400" />
|
||||
<h4 className="truncate font-medium text-gray-900">{resourceTitle}</h4>
|
||||
<Bookmark className="size-4 fill-current text-gray-300" />
|
||||
<h4 className="truncate text-gray-900">{resourceTitle}</h4>
|
||||
</a>
|
||||
);
|
||||
}
|
||||
|
||||
@@ -54,7 +54,7 @@ export function DashboardPage(props: DashboardPageProps) {
|
||||
return (
|
||||
<div className="min-h-screen bg-gray-50 pb-20 pt-8">
|
||||
<div className="container">
|
||||
<div className="mb-8 flex flex-wrap items-center gap-1.5">
|
||||
<div className="mb-6 sm:mb-8 flex flex-wrap items-center gap-1.5">
|
||||
<DashboardTab
|
||||
label="Personal"
|
||||
isActive={!selectedTeamId}
|
||||
|
||||
32
src/components/Dashboard/EmptyStackMessage.tsx
Normal file
32
src/components/Dashboard/EmptyStackMessage.tsx
Normal file
@@ -0,0 +1,32 @@
|
||||
type EmptyStackMessageProps = {
|
||||
number: number;
|
||||
title: string;
|
||||
description: string;
|
||||
buttonText: string;
|
||||
buttonLink: string;
|
||||
};
|
||||
|
||||
export function EmptyStackMessage(props: EmptyStackMessageProps) {
|
||||
const { number, title, description, buttonText, buttonLink } = props;
|
||||
|
||||
return (
|
||||
<div className="absolute inset-0 flex items-center justify-center rounded-md bg-black/50">
|
||||
<div className="flex max-w-[200px] flex-col items-center justify-center rounded-md bg-white p-4 shadow-sm">
|
||||
<span className="flex h-8 w-8 items-center justify-center rounded-full bg-gray-300 text-white">
|
||||
{number}
|
||||
</span>
|
||||
<div className="my-3 text-center">
|
||||
<h3 className="text-sm font-medium text-black">{title}</h3>
|
||||
<p className="text-center text-xs text-gray-500">{description}</p>
|
||||
</div>
|
||||
|
||||
<a
|
||||
href={buttonLink}
|
||||
className="rounded-md bg-black px-3 py-1 text-xs text-white transition-transform hover:scale-105 hover:bg-gray-900"
|
||||
>
|
||||
{buttonText}
|
||||
</a>
|
||||
</div>
|
||||
</div>
|
||||
);
|
||||
}
|
||||
@@ -169,12 +169,14 @@ export function PersonalDashboard(props: PersonalDashboardProps) {
|
||||
];
|
||||
|
||||
const relatedRoadmapIds = allRoadmapsAndBestPractices
|
||||
// take the ones that user is learning
|
||||
.filter((roadmap) =>
|
||||
learningRoadmapsToShow?.some(
|
||||
(learningRoadmap) => learningRoadmap.resourceId === roadmap.id,
|
||||
),
|
||||
)
|
||||
.flatMap((roadmap) => roadmap.relatedRoadmapIds)
|
||||
// remove the ones that user is already learning or has bookmarked
|
||||
.filter(
|
||||
(roadmapId) =>
|
||||
!learningRoadmapsToShow.some((lr) => lr.resourceId === roadmapId),
|
||||
@@ -225,9 +227,17 @@ export function PersonalDashboard(props: PersonalDashboardProps) {
|
||||
{isLoading ? (
|
||||
<div className="h-7 w-1/4 animate-pulse rounded-lg bg-gray-200"></div>
|
||||
) : (
|
||||
<h2 className="text-lg font-medium">
|
||||
Hi {name}, good {getCurrentPeriod()}!
|
||||
</h2>
|
||||
<div className="flex items-start sm:items-center justify-between flex-col sm:flex-row gap-1">
|
||||
<h2 className="text-lg font-medium">
|
||||
Hi {name}, good {getCurrentPeriod()}!
|
||||
</h2>
|
||||
<a
|
||||
href="/home"
|
||||
className="text-xs text-purple-600 underline underline-offset-2 hover:text-purple-700"
|
||||
>
|
||||
Looking for old homepage? Click here
|
||||
</a>
|
||||
</div>
|
||||
)}
|
||||
|
||||
<div className="mt-4 grid grid-cols-1 gap-2 sm:grid-cols-2 md:grid-cols-4">
|
||||
@@ -258,7 +268,7 @@ export function PersonalDashboard(props: PersonalDashboardProps) {
|
||||
icon={ConstructionEmoji}
|
||||
title="Build Projects"
|
||||
description="Practice what you learn"
|
||||
href="/backend/projects"
|
||||
href="/projects"
|
||||
/>
|
||||
<DashboardCard
|
||||
icon={CheckEmoji}
|
||||
|
||||
@@ -14,6 +14,7 @@ import { cn } from '../../lib/classname';
|
||||
import { DashboardProgressCard } from './DashboardProgressCard';
|
||||
import { useStore } from '@nanostores/react';
|
||||
import { $accountStreak, type StreakResponse } from '../../stores/streak';
|
||||
import { EmptyStackMessage } from './EmptyStackMessage.tsx';
|
||||
|
||||
type ProgressStackProps = {
|
||||
progresses: UserProgress[];
|
||||
@@ -26,8 +27,8 @@ type ProgressStackProps = {
|
||||
};
|
||||
|
||||
const MAX_PROGRESS_TO_SHOW = 5;
|
||||
const MAX_BOOKMARKS_TO_SHOW = 5;
|
||||
const MAX_PROJECTS_TO_SHOW = 8;
|
||||
const MAX_BOOKMARKS_TO_SHOW = 8;
|
||||
|
||||
type ProgressLaneProps = {
|
||||
title: string;
|
||||
@@ -74,7 +75,7 @@ function ProgressLane(props: ProgressLaneProps) {
|
||||
{linkText && linkHref && (
|
||||
<a
|
||||
href={linkHref}
|
||||
className="flex items-center gap-1 text-xs text-gray-500"
|
||||
className="flex items-center gap-1 text-xs text-gray-500 hover:text-black"
|
||||
>
|
||||
<ArrowUpRight size={12} />
|
||||
{linkText}
|
||||
@@ -83,7 +84,7 @@ function ProgressLane(props: ProgressLaneProps) {
|
||||
</div>
|
||||
)}
|
||||
|
||||
<div className="mt-4 flex flex-grow flex-col gap-2">
|
||||
<div className="mt-4 flex flex-grow flex-col gap-1.5">
|
||||
{isLoading && (
|
||||
<>
|
||||
{Array.from({ length: loadingSkeletonCount }).map((_, index) => (
|
||||
@@ -166,98 +167,139 @@ export function ProgressStack(props: ProgressStackProps) {
|
||||
</div>
|
||||
|
||||
<div className="mt-2 grid min-h-[330px] grid-cols-1 gap-2 sm:grid-cols-2 md:grid-cols-3">
|
||||
<ProgressLane
|
||||
title={'Your Progress'}
|
||||
isLoading={isLoading}
|
||||
loadingSkeletonCount={5}
|
||||
isEmpty={userProgressesToShow.length === 0}
|
||||
emptyMessage={'Update your Progress'}
|
||||
emptyIcon={Map}
|
||||
emptyLinkText={'Explore Roadmaps'}
|
||||
>
|
||||
{userProgressesToShow.length > 0 && (
|
||||
<>
|
||||
{userProgressesToShow.map((progress) => {
|
||||
return (
|
||||
<DashboardProgressCard
|
||||
key={progress.resourceId}
|
||||
progress={progress}
|
||||
/>
|
||||
);
|
||||
})}
|
||||
</>
|
||||
)}
|
||||
|
||||
{userProgresses.length > MAX_PROGRESS_TO_SHOW && (
|
||||
<ShowAllButton
|
||||
showAll={showAllProgresses}
|
||||
setShowAll={setShowAllProgresses}
|
||||
count={userProgresses.length}
|
||||
maxCount={MAX_PROGRESS_TO_SHOW}
|
||||
className="mb-0.5 mt-3"
|
||||
<div className="relative">
|
||||
{!isLoading && bookmarksToShow.length === 0 && (
|
||||
<EmptyStackMessage
|
||||
number={1}
|
||||
title={'Bookmark Roadmaps'}
|
||||
description={'Bookmark some roadmaps to access them quickly'}
|
||||
buttonText={'Explore Roadmaps'}
|
||||
buttonLink={'/roadmaps'}
|
||||
/>
|
||||
)}
|
||||
</ProgressLane>
|
||||
|
||||
<ProgressLane
|
||||
title={'Projects'}
|
||||
isLoading={isLoading}
|
||||
loadingSkeletonClassName={'h-5'}
|
||||
loadingSkeletonCount={8}
|
||||
isEmpty={projectsToShow.length === 0}
|
||||
emptyMessage={'No projects started'}
|
||||
emptyIcon={FolderKanban}
|
||||
emptyLinkText={'Explore Projects'}
|
||||
emptyLinkHref={'/backend/projects'}
|
||||
>
|
||||
{projectsToShow.map((project) => {
|
||||
return (
|
||||
<DashboardProjectCard key={project.projectId} project={project} />
|
||||
);
|
||||
})}
|
||||
|
||||
{projects.length > MAX_PROJECTS_TO_SHOW && (
|
||||
<ShowAllButton
|
||||
showAll={showAllProjects}
|
||||
setShowAll={setShowAllProjects}
|
||||
count={projects.length}
|
||||
maxCount={MAX_PROJECTS_TO_SHOW}
|
||||
className="mb-0.5 mt-3"
|
||||
/>
|
||||
)}
|
||||
</ProgressLane>
|
||||
|
||||
<ProgressLane
|
||||
title={'Bookmarks'}
|
||||
isLoading={isLoading}
|
||||
loadingSkeletonClassName={'h-5'}
|
||||
loadingSkeletonCount={8}
|
||||
linkHref={'/roadmaps'}
|
||||
linkText={'Explore'}
|
||||
isEmpty={bookmarksToShow.length === 0}
|
||||
emptyIcon={Bookmark}
|
||||
emptyMessage={'No bookmarks to show'}
|
||||
emptyLinkHref={'/roadmaps'}
|
||||
emptyLinkText={'Explore Roadmaps'}
|
||||
>
|
||||
{bookmarksToShow.map((progress) => {
|
||||
return (
|
||||
<DashboardBookmarkCard
|
||||
key={progress.resourceId}
|
||||
bookmark={progress}
|
||||
<ProgressLane
|
||||
title={'Bookmarks'}
|
||||
isLoading={isLoading}
|
||||
loadingSkeletonCount={5}
|
||||
linkHref={'/roadmaps'}
|
||||
linkText={'Roadmaps'}
|
||||
isEmpty={bookmarksToShow.length === 0}
|
||||
emptyIcon={Bookmark}
|
||||
emptyMessage={'No bookmarks to show'}
|
||||
emptyLinkHref={'/roadmaps'}
|
||||
emptyLinkText={'Explore Roadmaps'}
|
||||
>
|
||||
{bookmarksToShow.map((progress) => {
|
||||
return (
|
||||
<DashboardBookmarkCard
|
||||
key={progress.resourceId}
|
||||
bookmark={progress}
|
||||
/>
|
||||
);
|
||||
})}
|
||||
{bookmarkedProgresses.length > MAX_BOOKMARKS_TO_SHOW && (
|
||||
<ShowAllButton
|
||||
showAll={showAllBookmarks}
|
||||
setShowAll={setShowAllBookmarks}
|
||||
count={bookmarkedProgresses.length}
|
||||
maxCount={MAX_BOOKMARKS_TO_SHOW}
|
||||
className="mb-0.5 mt-3"
|
||||
/>
|
||||
);
|
||||
})}
|
||||
{bookmarkedProgresses.length > MAX_BOOKMARKS_TO_SHOW && (
|
||||
<ShowAllButton
|
||||
showAll={showAllBookmarks}
|
||||
setShowAll={setShowAllBookmarks}
|
||||
count={bookmarkedProgresses.length}
|
||||
maxCount={MAX_BOOKMARKS_TO_SHOW}
|
||||
className="mb-0.5 mt-3"
|
||||
)}
|
||||
</ProgressLane>
|
||||
</div>
|
||||
|
||||
<div className="relative">
|
||||
{!isLoading && userProgressesToShow.length === 0 && (
|
||||
<EmptyStackMessage
|
||||
number={2}
|
||||
title={'Track Progress'}
|
||||
description={'Pick your first roadmap and start learning'}
|
||||
buttonText={'Explore roadmaps'}
|
||||
buttonLink={'/roadmaps'}
|
||||
/>
|
||||
)}
|
||||
</ProgressLane>
|
||||
<ProgressLane
|
||||
title={'Progress'}
|
||||
linkHref={'/roadmaps'}
|
||||
linkText={'Roadmaps'}
|
||||
isLoading={isLoading}
|
||||
loadingSkeletonCount={5}
|
||||
isEmpty={userProgressesToShow.length === 0}
|
||||
emptyMessage={'Update your Progress'}
|
||||
emptyIcon={Map}
|
||||
emptyLinkText={'Explore Roadmaps'}
|
||||
>
|
||||
{userProgressesToShow.length > 0 && (
|
||||
<>
|
||||
{userProgressesToShow.map((progress) => {
|
||||
return (
|
||||
<DashboardProgressCard
|
||||
key={progress.resourceId}
|
||||
progress={progress}
|
||||
/>
|
||||
);
|
||||
})}
|
||||
</>
|
||||
)}
|
||||
|
||||
{userProgresses.length > MAX_PROGRESS_TO_SHOW && (
|
||||
<ShowAllButton
|
||||
showAll={showAllProgresses}
|
||||
setShowAll={setShowAllProgresses}
|
||||
count={userProgresses.length}
|
||||
maxCount={MAX_PROGRESS_TO_SHOW}
|
||||
className="mb-0.5 mt-3"
|
||||
/>
|
||||
)}
|
||||
</ProgressLane>
|
||||
</div>
|
||||
|
||||
<div className="relative">
|
||||
<ProgressLane
|
||||
title={'Projects'}
|
||||
linkHref={'/projects'}
|
||||
linkText={'Projects'}
|
||||
isLoading={isLoading}
|
||||
loadingSkeletonClassName={'h-5'}
|
||||
loadingSkeletonCount={8}
|
||||
isEmpty={projectsToShow.length === 0}
|
||||
emptyMessage={'No projects started'}
|
||||
emptyIcon={FolderKanban}
|
||||
emptyLinkText={'Explore Projects'}
|
||||
emptyLinkHref={'/projects'}
|
||||
>
|
||||
{!isLoading && projectsToShow.length === 0 && (
|
||||
<EmptyStackMessage
|
||||
number={3}
|
||||
title={'Build your first project'}
|
||||
description={'Pick a project to practice and start building'}
|
||||
buttonText={'Explore Projects'}
|
||||
buttonLink={'/projects'}
|
||||
/>
|
||||
)}
|
||||
|
||||
{projectsToShow.map((project) => {
|
||||
return (
|
||||
<DashboardProjectCard
|
||||
key={project.projectId}
|
||||
project={project}
|
||||
/>
|
||||
);
|
||||
})}
|
||||
|
||||
{projects.length > MAX_PROJECTS_TO_SHOW && (
|
||||
<ShowAllButton
|
||||
showAll={showAllProjects}
|
||||
setShowAll={setShowAllProjects}
|
||||
count={projects.length}
|
||||
maxCount={MAX_PROJECTS_TO_SHOW}
|
||||
className="mb-0.5 mt-3"
|
||||
/>
|
||||
)}
|
||||
</ProgressLane>
|
||||
</div>
|
||||
</div>
|
||||
</>
|
||||
);
|
||||
|
||||
@@ -68,6 +68,6 @@ export function RecommendedRoadmapCard(props: RecommendedRoadmapCardProps) {
|
||||
|
||||
function RecommendedCardSkeleton() {
|
||||
return (
|
||||
<div className="h-[42px] w-full animate-pulse rounded-md bg-gray-200" />
|
||||
<div className="h-[38px] w-full animate-pulse rounded-md bg-gray-200" />
|
||||
);
|
||||
}
|
||||
|
||||
@@ -23,7 +23,7 @@ export function FeatureAnnouncement(props: FeatureAnnouncementProps) {
|
||||
</span>
|
||||
Projects are live on the{' '}
|
||||
<a
|
||||
href={'/backend/projects'}
|
||||
href={'/projects'}
|
||||
className="font-medium text-blue-500 underline underline-offset-2"
|
||||
>
|
||||
backend roadmap
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
---
|
||||
import { FavoriteRoadmaps } from './FavoriteRoadmaps';
|
||||
import { FeatureAnnouncement } from "../FeatureAnnouncement";
|
||||
---
|
||||
|
||||
@@ -31,5 +30,4 @@ import { FeatureAnnouncement } from "../FeatureAnnouncement";
|
||||
their career.
|
||||
</p>
|
||||
</div>
|
||||
<FavoriteRoadmaps client:only='react' />
|
||||
</div>
|
||||
|
||||
26
src/components/Leaderboard/ErrorPage.tsx
Normal file
26
src/components/Leaderboard/ErrorPage.tsx
Normal file
@@ -0,0 +1,26 @@
|
||||
import type { AppError } from '../../api/api';
|
||||
import { ErrorIcon } from '../ReactIcons/ErrorIcon';
|
||||
|
||||
type ErrorPageProps = {
|
||||
error: AppError;
|
||||
};
|
||||
|
||||
export function ErrorPage(props: ErrorPageProps) {
|
||||
const { error } = props;
|
||||
|
||||
return (
|
||||
<div className="min-h-screen bg-gray-50">
|
||||
<div className="container py-10">
|
||||
<div className="flex min-h-[250px] flex-col items-center justify-center px-5 py-3 sm:px-0 sm:py-20">
|
||||
<ErrorIcon additionalClasses="mb-4 h-8 w-8 sm:h-14 sm:w-14" />
|
||||
<h2 className="mb-1 text-lg font-semibold sm:text-xl">
|
||||
Oops! Something went wrong
|
||||
</h2>
|
||||
<p className="mb-3 text-balance text-center text-xs text-gray-800 sm:text-sm">
|
||||
{error?.message || 'An error occurred while fetching'}
|
||||
</p>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
);
|
||||
}
|
||||
178
src/components/Leaderboard/LeaderboardPage.tsx
Normal file
178
src/components/Leaderboard/LeaderboardPage.tsx
Normal file
@@ -0,0 +1,178 @@
|
||||
import { useState, type ReactNode } from 'react';
|
||||
import type {
|
||||
LeadeboardUserDetails,
|
||||
ListLeaderboardStatsResponse,
|
||||
} from '../../api/leaderboard';
|
||||
import { cn } from '../../lib/classname';
|
||||
import { FolderKanban, Zap, Trophy } from 'lucide-react';
|
||||
import { RankBadgeIcon } from '../ReactIcons/RankBadgeIcon';
|
||||
import { TrophyEmoji } from '../ReactIcons/TrophyEmoji';
|
||||
import { SecondPlaceMedalEmoji } from '../ReactIcons/SecondPlaceMedalEmoji';
|
||||
import { ThirdPlaceMedalEmoji } from '../ReactIcons/ThirdPlaceMedalEmoji';
|
||||
|
||||
type LeaderboardPageProps = {
|
||||
stats: ListLeaderboardStatsResponse;
|
||||
};
|
||||
|
||||
export function LeaderboardPage(props: LeaderboardPageProps) {
|
||||
const { stats } = props;
|
||||
|
||||
return (
|
||||
<div className="min-h-screen bg-gray-50">
|
||||
<div className="container py-10">
|
||||
<div className="mb-8 text-center">
|
||||
<div className="mb-2 flex items-center justify-center gap-3">
|
||||
<Trophy className="size-8 text-yellow-500" />
|
||||
<h2 className="text-2xl font-bold sm:text-3xl">Leaderboard</h2>
|
||||
</div>
|
||||
<p className="mx-auto max-w-2xl text-balance text-sm text-gray-500 sm:text-base">
|
||||
Top users based on their activity on roadmap.sh
|
||||
</p>
|
||||
|
||||
<div className="mt-8 grid gap-2 md:grid-cols-2">
|
||||
<LeaderboardLane
|
||||
title="Longest Visit Streak"
|
||||
tabs={[
|
||||
{
|
||||
title: 'Active',
|
||||
users: stats.streaks?.active || [],
|
||||
emptyIcon: <Zap className="size-16 text-gray-300" />,
|
||||
emptyText: 'No users with streaks yet',
|
||||
},
|
||||
{
|
||||
title: 'Lifetime',
|
||||
users: stats.streaks?.lifetime || [],
|
||||
emptyIcon: <Zap className="size-16 text-gray-300" />,
|
||||
emptyText: 'No users with streaks yet',
|
||||
},
|
||||
]}
|
||||
/>
|
||||
<LeaderboardLane
|
||||
title="Projects Completed"
|
||||
tabs={[
|
||||
{
|
||||
title: 'This Month',
|
||||
users: stats.projectSubmissions.currentMonth,
|
||||
emptyIcon: <FolderKanban className="size-16 text-gray-300" />,
|
||||
emptyText: 'No projects submitted this month',
|
||||
},
|
||||
{
|
||||
title: 'Lifetime',
|
||||
users: stats.projectSubmissions.lifetime,
|
||||
emptyIcon: <FolderKanban className="size-16 text-gray-300" />,
|
||||
emptyText: 'No projects submitted yet',
|
||||
},
|
||||
]}
|
||||
/>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
);
|
||||
}
|
||||
|
||||
type LeaderboardLaneProps = {
|
||||
title: string;
|
||||
tabs: {
|
||||
title: string;
|
||||
users: LeadeboardUserDetails[];
|
||||
emptyIcon?: ReactNode;
|
||||
emptyText?: string;
|
||||
}[];
|
||||
};
|
||||
|
||||
function LeaderboardLane(props: LeaderboardLaneProps) {
|
||||
const { title, tabs } = props;
|
||||
|
||||
const [activeTab, setActiveTab] = useState(tabs[0]);
|
||||
const { users: usersToShow, emptyIcon, emptyText } = activeTab;
|
||||
|
||||
return (
|
||||
<div className="overflow-hidden rounded-md border bg-white shadow-sm">
|
||||
<div className="flex items-center justify-between gap-2 bg-gray-100 px-3 py-3 mb-3">
|
||||
<h3 className="text-base font-medium">{title}</h3>
|
||||
|
||||
{tabs.length > 1 && (
|
||||
<div className="flex items-center gap-2">
|
||||
{tabs.map((tab) => {
|
||||
const isActive = tab === activeTab;
|
||||
|
||||
return (
|
||||
<button
|
||||
key={tab.title}
|
||||
onClick={() => setActiveTab(tab)}
|
||||
className={cn(
|
||||
'text-sm font-medium underline-offset-2 transition-colors',
|
||||
{
|
||||
'text-black underline': isActive,
|
||||
'text-gray-400 hover:text-gray-600': !isActive,
|
||||
},
|
||||
)}
|
||||
>
|
||||
{tab.title}
|
||||
</button>
|
||||
);
|
||||
})}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
|
||||
{usersToShow.length === 0 && emptyText && (
|
||||
<div className="flex flex-col items-center justify-center p-8">
|
||||
{emptyIcon}
|
||||
<p className="mt-4 text-sm text-gray-500">{emptyText}</p>
|
||||
</div>
|
||||
)}
|
||||
|
||||
{usersToShow.length > 0 && (
|
||||
<ul className="divide-y divide-gray-100 pb-4">
|
||||
{usersToShow.map((user, counter) => {
|
||||
const avatar = user?.avatar
|
||||
? `${import.meta.env.PUBLIC_AVATAR_BASE_URL}/${user.avatar}`
|
||||
: '/images/default-avatar.png';
|
||||
const rank = counter + 1;
|
||||
|
||||
return (
|
||||
<li
|
||||
key={user.id}
|
||||
className="flex items-center justify-between gap-1 pl-2 pr-5 py-2.5 hover:bg-gray-50"
|
||||
>
|
||||
<div className="flex min-w-0 items-center gap-2">
|
||||
<span
|
||||
className={cn(
|
||||
'relative text-xs mr-1 flex size-6 shrink-0 items-center justify-center rounded-full tabular-nums',
|
||||
{
|
||||
'text-black': rank <= 3,
|
||||
'text-gray-400': rank > 3,
|
||||
},
|
||||
)}
|
||||
>
|
||||
{rank}
|
||||
</span>
|
||||
|
||||
<img
|
||||
src={avatar}
|
||||
alt={user.name}
|
||||
className="size-7 shrink-0 rounded-full"
|
||||
/>
|
||||
<span className="truncate">{user.name}</span>
|
||||
{rank === 1 ? (
|
||||
<TrophyEmoji className="size-5" />
|
||||
) : rank === 2 ? (
|
||||
<SecondPlaceMedalEmoji className="size-5" />
|
||||
) : rank === 3 ? (
|
||||
<ThirdPlaceMedalEmoji className="size-5" />
|
||||
) : (
|
||||
''
|
||||
)}
|
||||
</div>
|
||||
|
||||
<span className="text-sm text-gray-500">{user.count}</span>
|
||||
</li>
|
||||
);
|
||||
})}
|
||||
</ul>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
}
|
||||
@@ -25,7 +25,7 @@ const links = [
|
||||
Icon: Waypoints,
|
||||
},
|
||||
{
|
||||
link: '/backend/projects',
|
||||
link: '/projects',
|
||||
label: 'Projects',
|
||||
description: 'Skill-up with real-world projects',
|
||||
Icon: FolderKanban,
|
||||
|
||||
200
src/components/Projects/ProjectsPage.tsx
Normal file
200
src/components/Projects/ProjectsPage.tsx
Normal file
@@ -0,0 +1,200 @@
|
||||
import { useEffect, useMemo, useRef, useState } from 'react';
|
||||
import { cn } from '../../lib/classname.ts';
|
||||
import { Box, Filter, Group, X } from 'lucide-react';
|
||||
import {
|
||||
deleteUrlParam,
|
||||
getUrlParams,
|
||||
setUrlParams,
|
||||
} from '../../lib/browser.ts';
|
||||
import { CategoryFilterButton } from '../Roadmaps/CategoryFilterButton.tsx';
|
||||
import {
|
||||
projectDifficulties,
|
||||
type ProjectFileType,
|
||||
} from '../../lib/project.ts';
|
||||
import { ProjectCard } from './ProjectCard.tsx';
|
||||
|
||||
type ProjectGroup = {
|
||||
id: string;
|
||||
title: string;
|
||||
projects: ProjectFileType[];
|
||||
};
|
||||
|
||||
type ProjectsPageProps = {
|
||||
roadmapsProjects: ProjectGroup[];
|
||||
userCounts: Record<string, number>;
|
||||
};
|
||||
|
||||
export function ProjectsPage(props: ProjectsPageProps) {
|
||||
const { roadmapsProjects, userCounts } = props;
|
||||
const allUniqueProjectIds = new Set<string>(
|
||||
roadmapsProjects.flatMap((group) =>
|
||||
group.projects.map((project) => project.id),
|
||||
),
|
||||
);
|
||||
const allUniqueProjects = useMemo(
|
||||
() =>
|
||||
Array.from(allUniqueProjectIds)
|
||||
.map((id) =>
|
||||
roadmapsProjects
|
||||
.flatMap((group) => group.projects)
|
||||
.find((project) => project.id === id),
|
||||
)
|
||||
.filter(Boolean) as ProjectFileType[],
|
||||
[allUniqueProjectIds],
|
||||
);
|
||||
|
||||
const [activeGroup, setActiveGroup] = useState<string>('');
|
||||
const [visibleProjects, setVisibleProjects] =
|
||||
useState<ProjectFileType[]>(allUniqueProjects);
|
||||
|
||||
const [isFilterOpen, setIsFilterOpen] = useState(false);
|
||||
|
||||
useEffect(() => {
|
||||
const { g } = getUrlParams() as { g: string };
|
||||
if (!g) {
|
||||
return;
|
||||
}
|
||||
|
||||
setActiveGroup(g);
|
||||
const group = roadmapsProjects.find((group) => group.id === g);
|
||||
if (!group) {
|
||||
return;
|
||||
}
|
||||
|
||||
setVisibleProjects(group.projects);
|
||||
}, []);
|
||||
|
||||
const sortedVisibleProjects = useMemo(
|
||||
() =>
|
||||
visibleProjects.sort((a, b) => {
|
||||
const projectADifficulty = a?.frontmatter.difficulty || 'beginner';
|
||||
const projectBDifficulty = b?.frontmatter.difficulty || 'beginner';
|
||||
return (
|
||||
projectDifficulties.indexOf(projectADifficulty) -
|
||||
projectDifficulties.indexOf(projectBDifficulty)
|
||||
);
|
||||
}),
|
||||
[visibleProjects],
|
||||
);
|
||||
|
||||
const activeGroupDetail = roadmapsProjects.find(
|
||||
(group) => group.id === activeGroup,
|
||||
);
|
||||
|
||||
const requiredSortOrder = [
|
||||
'Frontend',
|
||||
'Backend',
|
||||
'DevOps',
|
||||
'Full-stack',
|
||||
'JavaScript',
|
||||
'Go',
|
||||
'Python',
|
||||
'Node.js',
|
||||
'Java',
|
||||
];
|
||||
|
||||
return (
|
||||
<div className="border-t bg-gray-100">
|
||||
<button
|
||||
onClick={() => {
|
||||
setIsFilterOpen(!isFilterOpen);
|
||||
}}
|
||||
id="filter-button"
|
||||
className={cn(
|
||||
'-mt-1 flex w-full items-center justify-center bg-gray-300 py-2 text-sm text-black focus:shadow-none focus:outline-0 sm:hidden',
|
||||
{
|
||||
'mb-3': !isFilterOpen,
|
||||
},
|
||||
)}
|
||||
>
|
||||
{!isFilterOpen && <Filter size={13} className="mr-1" />}
|
||||
{isFilterOpen && <X size={13} className="mr-1" />}
|
||||
Categories
|
||||
</button>
|
||||
<div className="container relative flex flex-col gap-4 sm:flex-row">
|
||||
<div
|
||||
className={cn(
|
||||
'hidden w-full flex-col from-gray-100 sm:w-[160px] sm:shrink-0 sm:border-r sm:bg-gradient-to-l sm:pt-6',
|
||||
{
|
||||
'hidden sm:flex': !isFilterOpen,
|
||||
'z-50 flex': isFilterOpen,
|
||||
},
|
||||
)}
|
||||
>
|
||||
<div className="absolute top-0 -mx-4 w-full bg-white pb-0 shadow-xl sm:sticky sm:top-10 sm:mx-0 sm:bg-transparent sm:pb-20 sm:shadow-none">
|
||||
<div className="grid grid-cols-1">
|
||||
<CategoryFilterButton
|
||||
onClick={() => {
|
||||
setActiveGroup('');
|
||||
setVisibleProjects(allUniqueProjects);
|
||||
setIsFilterOpen(false);
|
||||
deleteUrlParam('g');
|
||||
}}
|
||||
category={'All Projects'}
|
||||
selected={activeGroup === ''}
|
||||
/>
|
||||
|
||||
{roadmapsProjects
|
||||
.sort((a, b) => {
|
||||
const aIndex = requiredSortOrder.indexOf(a.title);
|
||||
const bIndex = requiredSortOrder.indexOf(b.title);
|
||||
|
||||
if (aIndex === -1 && bIndex === -1) {
|
||||
return a.title.localeCompare(b.title);
|
||||
}
|
||||
|
||||
if (aIndex === -1) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
if (bIndex === -1) {
|
||||
return -1;
|
||||
}
|
||||
return aIndex - bIndex;
|
||||
})
|
||||
.map((group) => (
|
||||
<CategoryFilterButton
|
||||
key={group.id}
|
||||
onClick={() => {
|
||||
setActiveGroup(group.id);
|
||||
setIsFilterOpen(false);
|
||||
document
|
||||
?.getElementById('filter-button')
|
||||
?.scrollIntoView();
|
||||
setVisibleProjects(group.projects);
|
||||
setUrlParams({ g: group.id });
|
||||
}}
|
||||
category={group.title}
|
||||
selected={activeGroup === group.id}
|
||||
/>
|
||||
))}
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<div className="flex flex-grow flex-col pb-20 pt-2 sm:pt-6">
|
||||
<div className="mb-4 flex items-center justify-between text-sm text-gray-500">
|
||||
<h3 className={'flex items-center'}>
|
||||
<Box size={15} className="mr-1" strokeWidth={2} />
|
||||
{activeGroupDetail
|
||||
? `Projects in ${activeGroupDetail?.title}`
|
||||
: 'All Projects'}
|
||||
</h3>
|
||||
<p className="text-left">
|
||||
Matches found ({sortedVisibleProjects.length})
|
||||
</p>
|
||||
</div>
|
||||
|
||||
<div className="grid grid-cols-1 gap-1.5 sm:grid-cols-2">
|
||||
{sortedVisibleProjects.map((project) => (
|
||||
<ProjectCard
|
||||
key={project.id}
|
||||
project={project}
|
||||
userCount={userCounts[project.id] || 0}
|
||||
/>
|
||||
))}
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
);
|
||||
}
|
||||
17
src/components/Projects/ProjectsPageHeader.tsx
Normal file
17
src/components/Projects/ProjectsPageHeader.tsx
Normal file
@@ -0,0 +1,17 @@
|
||||
import { isLoggedIn } from '../../lib/jwt.ts';
|
||||
import { showLoginPopup } from '../../lib/popup.ts';
|
||||
|
||||
export function ProjectsPageHeader() {
|
||||
return (
|
||||
<div className="bg-white py-3 sm:py-12">
|
||||
<div className="container">
|
||||
<div className="flex flex-col items-start bg-white sm:items-center">
|
||||
<h1 className="text-2xl font-bold sm:text-5xl">Project Ideas</h1>
|
||||
<p className="mt-1 text-sm sm:mt-4 sm:text-lg">
|
||||
Browse the ever-growing list of projects ideas and solutions.
|
||||
</p>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
);
|
||||
}
|
||||
@@ -1,4 +1,4 @@
|
||||
import { Flag, Play, Send, Share, X } from 'lucide-react';
|
||||
import { Flag, Play, Send, Share, Square, StopCircle, X } from 'lucide-react';
|
||||
import { useEffect, useRef, useState } from 'react';
|
||||
import { cn } from '../../../lib/classname.ts';
|
||||
import { useStickyStuck } from '../../../hooks/use-sticky-stuck.tsx';
|
||||
@@ -13,6 +13,7 @@ import { showLoginPopup } from '../../../lib/popup.ts';
|
||||
import { SubmitProjectModal } from '../SubmitProjectModal.tsx';
|
||||
import { useCopyText } from '../../../hooks/use-copy-text.ts';
|
||||
import { CheckIcon } from '../../ReactIcons/CheckIcon.tsx';
|
||||
import { pageProgressMessage } from '../../../stores/page.ts';
|
||||
|
||||
type ProjectStatusResponse = {
|
||||
id?: string;
|
||||
@@ -93,7 +94,12 @@ export function ProjectStepper(props: ProjectStepperProps) {
|
||||
return;
|
||||
}
|
||||
|
||||
window.location.reload();
|
||||
pageProgressMessage.set('Update project status');
|
||||
setActiveStep(0);
|
||||
loadProjectStatus().finally(() => {
|
||||
pageProgressMessage.set('');
|
||||
setIsStoppingProject(false);
|
||||
});
|
||||
};
|
||||
|
||||
useEffect(() => {
|
||||
@@ -210,13 +216,13 @@ export function ProjectStepper(props: ProjectStepperProps) {
|
||||
{projectStatus?.startedAt && !projectStatus?.submittedAt && (
|
||||
<button
|
||||
className={cn(
|
||||
'ml-auto hidden items-center gap-1 text-sm disabled:opacity-50 sm:flex',
|
||||
'ml-auto hidden items-center gap-1.5 text-sm hover:text-black disabled:opacity-50 sm:flex',
|
||||
)}
|
||||
onClick={stopProject}
|
||||
disabled={isStoppingProject}
|
||||
>
|
||||
<X className="h-3.5 w-3.5 stroke-[2.5px]" />
|
||||
<span className="hidden md:inline">Stop Project</span>
|
||||
<Square className="h-3 w-3 fill-current stroke-[2.5px]" />
|
||||
<span className="hidden md:inline">Stop Working</span>
|
||||
<span className="md:hidden">Stop</span>
|
||||
</button>
|
||||
)}
|
||||
|
||||
19
src/components/ReactIcons/RankBadgeIcon.tsx
Normal file
19
src/components/ReactIcons/RankBadgeIcon.tsx
Normal file
@@ -0,0 +1,19 @@
|
||||
import type { SVGProps } from 'react';
|
||||
|
||||
export function RankBadgeIcon(props: SVGProps<SVGSVGElement>) {
|
||||
return (
|
||||
<svg
|
||||
width="11"
|
||||
height="11"
|
||||
viewBox="0 0 11 11"
|
||||
fill="none"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
{...props}
|
||||
>
|
||||
<path
|
||||
d="M0 0L11 0V10.0442L5.73392 6.32786L0 10.0442L0 0Z"
|
||||
fill="currentColor"
|
||||
></path>
|
||||
</svg>
|
||||
);
|
||||
}
|
||||
25
src/components/ReactIcons/SecondPlaceMedalEmoji.tsx
Normal file
25
src/components/ReactIcons/SecondPlaceMedalEmoji.tsx
Normal file
@@ -0,0 +1,25 @@
|
||||
import React from 'react';
|
||||
import type { SVGProps } from 'react';
|
||||
|
||||
export function SecondPlaceMedalEmoji(props: SVGProps<SVGSVGElement>) {
|
||||
return (
|
||||
<svg
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
width="1em"
|
||||
height="1em"
|
||||
viewBox="0 0 36 36"
|
||||
{...props}
|
||||
>
|
||||
<path fill="#55acee" d="m18 8l-7-8H0l14 17l11.521-4.75z"></path>
|
||||
<path fill="#3b88c3" d="m25 0l-7 8l5.39 7.312l1.227-1.489L36 0z"></path>
|
||||
<path
|
||||
fill="#ccd6dd"
|
||||
d="M23.205 16.026c.08-.217.131-.448.131-.693a2 2 0 0 0-2-2h-6.667a2 2 0 0 0-2 2c0 .245.05.476.131.693c-3.258 1.826-5.464 5.307-5.464 9.307C7.335 31.224 12.111 36 18.002 36s10.667-4.776 10.667-10.667c0-4-2.206-7.481-5.464-9.307"
|
||||
></path>
|
||||
<path
|
||||
fill="#627077"
|
||||
d="M22.002 28.921h-3.543c.878-1.234 2.412-3.234 3.01-4.301c.449-.879.729-1.439.729-2.43c0-2.076-1.57-3.777-4.244-3.777c-2.225 0-3.74 1.832-3.74 1.832c-.131.15-.112.374.019.487l1.141 1.159a.36.36 0 0 0 .523 0c.355-.393 1.047-.935 1.813-.935c1.047 0 1.646.635 1.646 1.346c0 .523-.243 1.047-.486 1.421c-1.104 1.682-3.871 5.441-4.955 6.862v.374c0 .188.149.355.355.355h7.732a.37.37 0 0 0 .355-.355v-1.682a.367.367 0 0 0-.355-.356"
|
||||
></path>
|
||||
</svg>
|
||||
);
|
||||
}
|
||||
25
src/components/ReactIcons/ThirdPlaceMedalEmoji.tsx
Normal file
25
src/components/ReactIcons/ThirdPlaceMedalEmoji.tsx
Normal file
@@ -0,0 +1,25 @@
|
||||
import React from 'react';
|
||||
import type { SVGProps } from 'react';
|
||||
|
||||
export function ThirdPlaceMedalEmoji(props: SVGProps<SVGSVGElement>) {
|
||||
return (
|
||||
<svg
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
width="1em"
|
||||
height="1em"
|
||||
viewBox="0 0 36 36"
|
||||
{...props}
|
||||
>
|
||||
<path fill="#55ACEE" d="m18 8l-7-8H0l14 17l11.521-4.75z"></path>
|
||||
<path fill="#3B88C3" d="m25 0l-7 8l5.39 7.312l1.227-1.489L36 0z"></path>
|
||||
<path
|
||||
fill="#FF8A3B"
|
||||
d="M23.205 16.026c.08-.217.131-.448.131-.693a2 2 0 0 0-2-2h-6.667a2 2 0 0 0-2 2c0 .245.05.476.131.693c-3.258 1.826-5.464 5.307-5.464 9.307C7.335 31.224 12.111 36 18.002 36s10.667-4.776 10.667-10.667c0-4-2.206-7.481-5.464-9.307"
|
||||
></path>
|
||||
<path
|
||||
fill="#7C4119"
|
||||
d="m14.121 29.35l1.178-1.178a.345.345 0 0 1 .467-.038s1.159.861 2.056.861c.805 0 1.628-.673 1.628-1.496s-.842-1.514-2.225-1.514h-.639a.367.367 0 0 1-.354-.355v-1.552c0-.206.168-.355.354-.355h.639c1.309 0 2-.635 2-1.439c0-.805-.691-1.402-1.496-1.402c-.823 0-1.346.43-1.626.747c-.132.15-.355.15-.504.02l-1.141-1.122c-.151-.132-.132-.355 0-.486c0 0 1.533-1.646 3.57-1.646c2.169 0 4.039 1.328 4.039 3.422c0 1.439-1.085 2.505-1.926 2.897v.057c.879.374 2.262 1.533 2.262 3.141c0 2.038-1.776 3.572-4.357 3.572c-2.354 0-3.552-1.16-3.944-1.664c-.113-.134-.093-.34.019-.47"
|
||||
></path>
|
||||
</svg>
|
||||
);
|
||||
}
|
||||
31
src/components/ReactIcons/TrophyEmoji.tsx
Normal file
31
src/components/ReactIcons/TrophyEmoji.tsx
Normal file
@@ -0,0 +1,31 @@
|
||||
import React from 'react';
|
||||
import type { SVGProps } from 'react';
|
||||
|
||||
export function TrophyEmoji(props: SVGProps<SVGSVGElement>) {
|
||||
return (
|
||||
<svg
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
width="1em"
|
||||
height="1em"
|
||||
viewBox="0 0 36 36"
|
||||
{...props}
|
||||
>
|
||||
<path
|
||||
fill="#ffac33"
|
||||
d="M5.123 5h6C12.227 5 13 4.896 13 6V4c0-1.104-.773-2-1.877-2h-8c-2 0-3.583 2.125-3 5c0 0 1.791 9.375 1.917 9.958C2.373 18.5 4.164 20 6.081 20h6.958c1.105 0-.039-1.896-.039-3v-2c0 1.104-.773 2-1.877 2h-4c-1.104 0-1.833-1.042-2-2S3.539 7.667 3.539 7.667C3.206 5.75 4.018 5 5.123 5m25.812 0h-6C23.831 5 22 4.896 22 6V4c0-1.104 1.831-2 2.935-2h8c2 0 3.584 2.125 3 5c0 0-1.633 9.419-1.771 10c-.354 1.5-2.042 3-4 3h-7.146C21.914 20 22 18.104 22 17v-2c0 1.104 1.831 2 2.935 2h4c1.104 0 1.834-1.042 2-2s1.584-7.333 1.584-7.333C32.851 5.75 32.04 5 30.935 5M20.832 22c0-6.958-2.709 0-2.709 0s-3-6.958-3 0s-3.291 10-3.291 10h12.292c-.001 0-3.292-3.042-3.292-10"
|
||||
></path>
|
||||
<path
|
||||
fill="#ffcc4d"
|
||||
d="M29.123 6.577c0 6.775-6.77 18.192-11 18.192s-11-11.417-11-18.192c0-5.195 1-6.319 3-6.319c1.374 0 6.025-.027 8-.027l7-.001c2.917-.001 4 .684 4 6.347"
|
||||
></path>
|
||||
<path
|
||||
fill="#c1694f"
|
||||
d="M27 33c0 1.104.227 2-.877 2h-16C9.018 35 9 34.104 9 33v-1c0-1.104 1.164-2 2.206-2h13.917c1.042 0 1.877.896 1.877 2z"
|
||||
></path>
|
||||
<path
|
||||
fill="#c1694f"
|
||||
d="M29 34.625c0 .76.165 1.375-1.252 1.375H8.498C7.206 36 7 35.385 7 34.625v-.25C7 33.615 7.738 33 8.498 33h19.25c.759 0 1.252.615 1.252 1.375z"
|
||||
></path>
|
||||
</svg>
|
||||
);
|
||||
}
|
||||
472
src/data/guides/devops-skills.md
Normal file
472
src/data/guides/devops-skills.md
Normal file
@@ -0,0 +1,472 @@
|
||||
---
|
||||
title: '10+ In-Demand DevOps Engineer Skills to Master'
|
||||
description: 'Find out exactly what it takes to be a successful DevOps engineer with my recommendations for essential DevOps skills'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/devops/skills'
|
||||
seo:
|
||||
title: '10+ In-Demand DevOps Engineer Skills to Master'
|
||||
description: 'Find out exactly what it takes to be a successful DevOps engineer with my recommendations for essential DevOps skills'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/devops-engineer-skills-tlace.jpg'
|
||||
isNew: true
|
||||
type: 'textual'
|
||||
date: 2024-09-12
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
The role of the DevOps engineer is not always very well defined; some companies see it as the old-school sysadmin whose sole purpose is to take care of the platform's infrastructure. Others see it as the person in charge of the Terraform configuration files. In the end, properly understanding what DevOps is and what you should expect from this role is critical to properly taking advantage of it and adding the value it’s meant to be adding to your company.
|
||||
|
||||
While you can work on becoming a DevOps engineer from scratch (there is actually a [DevOps roadmap for that](https://roadmap.sh/devops)), usually, a DevOps engineer is someone who has spent enough years either as a developer or in an operations role and wants to start helping solve the problems they’ve experienced throughout their entire career. This person sits between both sides and has intimate knowledge of one of them and a great deal of knowledge about the other side.
|
||||
|
||||
With that said, understanding everything there is to know to become a DevOps engineer who excels at their job is not trivial, and that’s why in this article, we’re going to cover the top 10 DevOps skills to help you level up your game.
|
||||
|
||||
The top 10 DevOps engineer skills to master are:
|
||||
|
||||
1. Understanding Linux and some scripting languages.
|
||||
2. Knowing how to set up your CI/CD pipelines.
|
||||
3. Embracing containerization and orchestration.
|
||||
4. Learning about Infrastructure as Code.
|
||||
5. Understanding cloud computing.
|
||||
6. Knowing how to monitor your infrastructure and manage your logs.
|
||||
7. Having a good grasp of security practices and tools.
|
||||
8. Know how to set up your networking and what that entails for your infrastructure.
|
||||
9. Knowing about version control.
|
||||
10. And finally, understanding configuration management.
|
||||
|
||||
Now, let’s get started.
|
||||
|
||||
## 1\. Proficiency in Linux and Scripting
|
||||
|
||||

|
||||
|
||||
Linux is one of the most common operating systems in the world of software development because of its incredible support, performance, and flexibility, which makes mastering it one of the main DevOps skills to work on.
|
||||
|
||||
Granted, the word “master” is loaded and there are many aspects of the OS that you don’t really need to worry about these days (with all the containers and IaC tools around), however without pushing yourself too hard and becoming a full-blown developer, investing part of your time into learning one or more scripting languages is definitely a good call.
|
||||
|
||||
As a DevOps engineer, you will be scripting and automating tasks, so pick a couple of popular scripting languages and make sure you understand them enough to get the job done. For example, picking Bash is a safe bet, as Bash is the native scripting language in most Linux distros. On top of that, you can pick something like Python or Ruby; both are great options. With an English-like syntax that’s very easy to read and understand and a set of very powerful automation libraries and DevOps tools available, you should be more than fine. For example, if you’re picking Python, you’ll be able to work on Ansible playbooks or custom modules, and if you go with Ruby, you can write Chef cookbooks.
|
||||
|
||||
In the end, it’s either about your own preference or the company’s standards if there are any, just pick one and figure out the tools at your disposal.
|
||||
|
||||
## 2\. Understanding of Continuous Integration and Continuous Deployment (CI/CD)
|
||||
|
||||
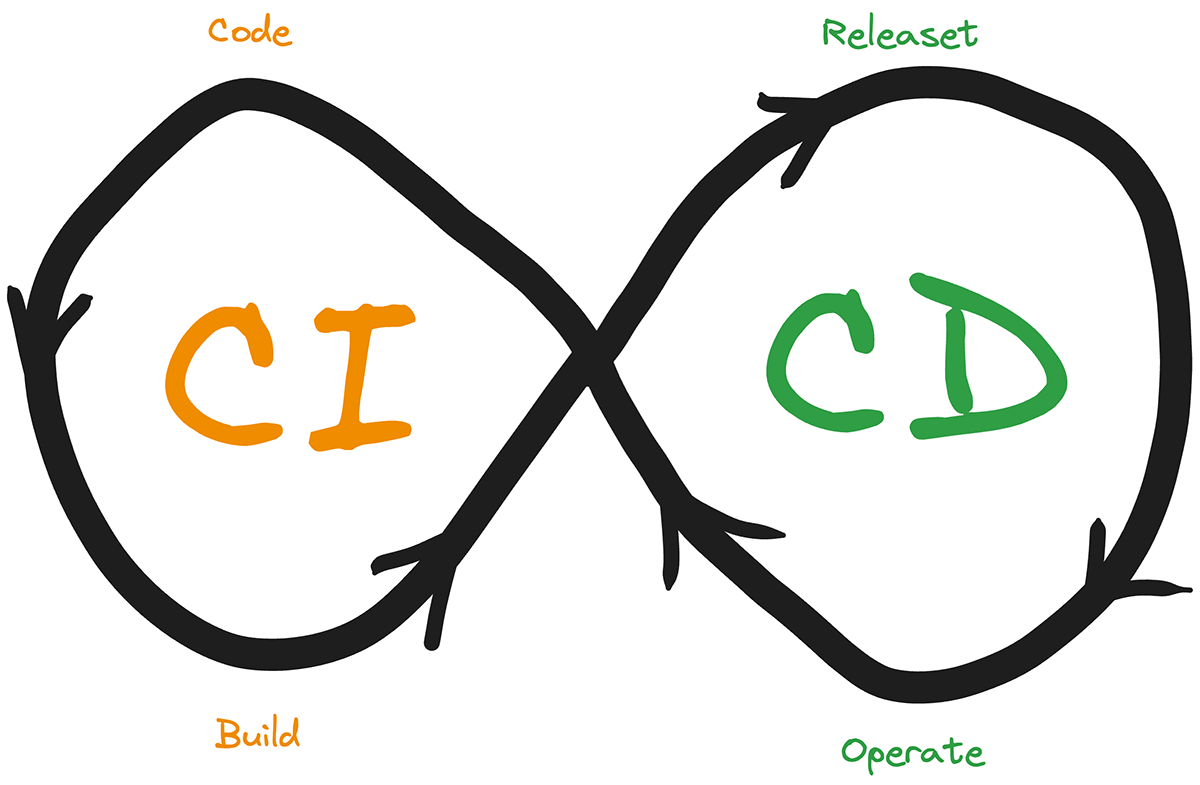
|
||||
|
||||
Continuous Integration and Continuous Deployment (CI/CD) form the backbone of a successful DevOps methodology. As a DevOps engineer, mastering CI/CD is non-negotiable.
|
||||
|
||||
### Understanding CI/CD
|
||||
|
||||
At its core, Continuous Integration (CI) is about automatically integrating code changes from multiple contributors into a shared repository as many times a day as needed (which can be one, zero, or hundreds; the number should be irrelevant).
|
||||
|
||||
The idea is to catch and fix integration bugs early and often, which is crucial for maintaining the health of your project.
|
||||
|
||||
On the other hand, Continuous Deployment (CD) takes this a step further by automatically deploying the integrated code to production environments once it passes all necessary tests. Together, both practices minimize manual intervention, reducing errors and allowing for rapid and reliable delivery of software.
|
||||
|
||||
### Key Tools for CI/CD
|
||||
|
||||
To effectively implement CI/CD pipelines, you'll need to be proficient with the tools that make it possible. There are tons of them out there; some of the most common (and arguably, best ones) are:
|
||||
|
||||
* **Jenkins**: An open-source automation server, Jenkins is highly customizable and supports a huge number of integration plugins.
|
||||
* **GitLab CI**: Part of the larger GitLab platform, GitLab CI is tightly integrated with GitLab's version control and issue-tracking features.
|
||||
* **CircleCI**: Known for its speed and simplicity, CircleCI is perfect for environments that prioritize cloud-native solutions. It provides a user-friendly interface and integrates well with popular tools like Docker, AWS, and Kubernetes.
|
||||
* **GitHub Actions**: GitHub Actions is a powerful CI/CD tool integrated directly into GitHub, allowing developers to automate, test, and deploy their code right from their repositories. It supports custom workflows, integration with other DevOps tools, and provides flexibility to run complex automation tasks across multiple environments.
|
||||
|
||||
### Best Practices for Setting Up and Managing CI/CD Pipelines
|
||||
|
||||
Setting up and managing CI/CD pipelines isn’t just about getting the tools to work; it’s about ensuring that they work well (whatever “well” means for your specific context).
|
||||
|
||||
Here are some best practices to follow:
|
||||
|
||||
1. **Start Small and Iterate**: Don’t try to automate everything at once. Start with the most critical parts of your workflow, then gradually expand the pipeline.
|
||||
2. **Ensure Fast Feedback**: The faster your CI/CD pipeline can provide feedback, the quicker your team can address issues.
|
||||
3. **Maintain a Stable Master Branch**: Always keep your master branch in a deployable state. Implement branch protection rules and require code reviews and automated tests to pass before any changes are merged.
|
||||
4. **Automate Everything Possible**: From testing to deployment, automate as many steps in your pipeline as possible.
|
||||
5. **Monitor and Optimize**: Continuously monitor your CI/CD pipelines for performance bottlenecks, failures, and inefficiencies. Use this data to refine your process.
|
||||
6. **Security Considerations**: Integrate security checks into your CI/CD pipelines to catch vulnerabilities early. Tools like static code analysis, dependency checking, and container scanning can help ensure that your code is secure before it reaches production.
|
||||
|
||||
## 3\. Containerization and Orchestration
|
||||
|
||||
These technologies are at the heart of modern DevOps practices, enabling scalability, portability, and efficiency.
|
||||
|
||||
### Basics of Containerization
|
||||
|
||||
Containerization is a method of packaging applications and their dependencies into isolated units called containers. Unlike traditional virtual machines, which require a full operating system, containers share the host OS’s kernel while running isolated user spaces.
|
||||
|
||||
This makes containers not only lightweight but also faster to start, and more resource-efficient.
|
||||
|
||||
There are many benefits to this technology, as you can probably glean by now, but the primary benefits include:
|
||||
|
||||
* **Portability**: Containers encapsulate everything an application needs to run, making it easy to move them across different environments. As long as there is a way to run containers in an OS, then your code can run on it.
|
||||
* **Scalability**: Containers can be easily scaled up or down based on demand. This flexibility is crucial when you need to handle dynamic workloads.
|
||||
* **Consistency**: By using containers, you can ensure that your applications run the same way across different environments, reducing the infamous "it works on my machine" problem.
|
||||
* **Isolation**: With container applications, don’t use resources outside of the ones defined for them. This means each application is isolated from others running on the same host server, avoiding interference.
|
||||
|
||||
### Key Containerization Tools
|
||||
|
||||
When it comes to containerization tools, Docker is the most popular and widely adopted alternative. However, other tools like Podman are also gaining traction, especially in environments that prioritize security and compatibility with Kubernetes.
|
||||
|
||||
Both tools offer robust features for managing containers, but the choice between them often comes down to specific use cases, security requirements, and integration with other tools in your DevOps toolkit.
|
||||
|
||||
### Orchestration Tools
|
||||
|
||||
While containerization simplifies application deployment, managing containers at scale requires something else: orchestration.
|
||||
|
||||
Orchestration tools like Kubernetes and Docker Swarm automate the deployment, scaling, and management of containerized applications, ensuring that they run efficiently and reliably across distributed environments.
|
||||
|
||||
* **Kubernetes**: Kubernetes is the de facto standard for container orchestration. Kubernetes provides a comprehensive platform for automating the deployment, scaling, and operation of containerized applications by managing clusters of containers.
|
||||
* **Docker Swarm**: Docker Swarm is Docker’s native clustering and orchestration tool. It’s simpler to set up and use compared to Kubernetes, making it a good choice for smaller teams or less complex projects.
|
||||
|
||||
## 4\. Infrastructure as Code (IaC)
|
||||
|
||||
Infrastructure as Code (IaC) has become a foundational practice for DevOps teams. IaC allows you to manage and provision your infrastructure through code, offering a level of automation and consistency that manual processes simply can’t match.
|
||||
|
||||
### Importance of IaC in Modern DevOps Practices
|
||||
|
||||
IaC is crucial in modern DevOps because it brings consistency, scalability, and speed to infrastructure.
|
||||
|
||||
IaC allows teams to define their infrastructure in code, which can be versioned, reviewed, and tested just like application code. If you think about it, IaC is the perfect example of what DevOps means: the merger of both worlds to achieve something that is greater than the sum of its parts.
|
||||
|
||||
Nowadays, IaC is not just a “best practice” but rather, an indispensable part of a DevOps engineer’s workflow, and here is why:
|
||||
|
||||
* **Consistency Across Environments**: As we’ve already mentioned, with IaC, you can ensure that your environments are all configured exactly the same way.
|
||||
* **Scalability**: Whether you need to add more servers, databases, or other resources, you can do it quickly and reliably by updating your code and reapplying it.
|
||||
* **Version Control and Collaboration**: By storing your infrastructure configurations in a version control system like Git, you enable better collaboration and control.
|
||||
* **Automation and Efficiency**: Once your infrastructure is defined in code, you can automate the provisioning, updating, and teardown of resources, allowing your team to focus on higher-value tasks.
|
||||
|
||||
### Key IaC Tools: Terraform, Ansible, Chef, Puppet
|
||||
|
||||
Several tools have become go-to solutions for IaC, each offering unique strengths.
|
||||
|
||||
Here are some of the most popular ones; however, feel free to pick others if they fit better in your particular use case/context:
|
||||
|
||||
* **Terraform**: Terraform is one of the most widely used IaC tools. It’s cloud-agnostic, meaning you can use it to manage infrastructure across different cloud providers like AWS, Azure, and Google Cloud.
|
||||
* **Ansible**: While Ansible’s main focus is automating configuration tasks across multiple servers, it is capable of also working as an IaC tool by providing support for infrastructure provisioning, application deployment, and orchestration.
|
||||
* **Chef**: Chef is another strong player in the configuration management space. It uses a Ruby-based language to create "recipes" that automate the deployment and management of infrastructure.
|
||||
* **Puppet**: Puppet offers a solid solution for configuration management, using its own declarative language to define the state of your infrastructure.
|
||||
|
||||
### Best Practices for Writing and Managing Infrastructure Code
|
||||
|
||||
Like with any coding project, writing clean and easy-to-read code will help a great deal in making the project itself a success. That’s no different in the case of IaC, the words “clean code” need to be engraved in every DevOp’s mind.
|
||||
|
||||
And this is what “clean” means in this context:
|
||||
|
||||
1. **Modularize Your Code**: Break down your infrastructure code into smaller, reusable modules. This approach is especially useful for larger projects where the infrastructure files grow in number; this way you can reuse sections and simplify maintenance.
|
||||
2. **Use Version Control**: Store all your infrastructure code in a version control system like Git. This practice enables you to track changes, collaborate with others, and roll back if something goes wrong.
|
||||
3. **Test Your Infrastructure Code**: Just like application code, infrastructure code should be tested. Tools like Terraform provide validation for configurations, and frameworks like Inspec or Testinfra can verify that your infrastructure is working as expected after deployment.
|
||||
4. **Follow the Principle of Least Privilege**: When defining infrastructure, ensure that each component has only the permissions it needs to perform its function. This practice reduces security risks by limiting the potential impact of a breach or misconfiguration.
|
||||
5. **Keep Secrets Secure**: Avoid the rooky mistake of hardcoding sensitive information, such as API keys or passwords, directly into your infrastructure code. Use tools like HashiCorp Vault, AWS Secrets Manager, or Azure Key Vault to manage secrets securely.
|
||||
6. **Document Your Code**: Just like application code, your infrastructure code should also be commented on and explained, not for you now, but for you next week or someone else next month. The easier it is to understand the code, the faster they’ll be able to work with it.
|
||||
7. **Integrate IaC into CI/CD Pipelines**: Automate as much as possible in the IaC workflow. That includes the validation, testing, and deployment of your infrastructure code by integrating it into your continuous integration and continuous deployment (CI/CD) pipelines. This ensures that your environments are always up-to-date and consistent with your codebase, reducing the risk of drift.
|
||||
|
||||
## 5\. Cloud Computing Expertise
|
||||
|
||||

|
||||
|
||||
In the DevOps ecosystem, cloud computing is more than just a trend companies are starting to follow—it's a fundamental element that defines modern software development and deployment practices.
|
||||
|
||||
And because of that, it’s one of the main DevOps skills you’ll want to develop.
|
||||
|
||||
### Importance of Cloud Platforms in DevOps
|
||||
|
||||
Cloud platforms have revolutionized the way software is developed, deployed, and managed. The cloud allows organizations to leverage vast computing resources on demand, scale their operations effortlessly, and reduce infrastructure costs.
|
||||
|
||||
Specifically for DevOps teams, cloud platforms offer several key benefits:
|
||||
|
||||
* **Scalability**: One of the most significant advantages of cloud computing is its ability to scale resources up or down based on demand. This elasticity is crucial for handling varying workloads, ensuring that applications remain responsive and, most importantly (as some would argue), cost-effective.
|
||||
* **Speed and Agility**: Provisioning of resources can be done with just a few clicks, allowing DevOps teams to spin up development, testing, and production environments in minutes. This speed accelerates the software development lifecycle, enabling faster releases and more frequent updates.
|
||||
* **Global Reach**: Cloud providers operate data centers around the world, making it easier for organizations to deploy applications closer to their users, reducing latency and improving performance.
|
||||
* **Cost Efficiency**: This is a recurring topic when discussing cloud platforms, as they help reduce the need for large upfront capital investments in hardware. Instead, organizations can pay for the resources they use, optimizing costs and reducing waste.
|
||||
* **Automation**: Cloud environments are highly automatable, allowing DevOps teams to automate infrastructure provisioning, scaling, and management.
|
||||
|
||||
### Key Cloud Providers: AWS, Azure, Google Cloud Platform (GCP)
|
||||
|
||||
When it comes to cloud providers, three providers dominate the market: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). While they’re not the only ones, and in some regions of the world, they’re not even the top providers. In general, they own most of the cloud market.
|
||||
|
||||
Each of them offers a vast array of services and tools that cater to different needs, making them the go-to choices for DevOps professionals.
|
||||
|
||||
* **Amazon Web Services (AWS)**: AWS is the largest and most mature of the three, offering an extensive range of services, including computing power (EC2), storage (S3), databases (RDS), and more. AWS is known for its large number of features, including advanced networking, security, and analytics tools. For DevOps engineers, AWS provides powerful services like AWS Lambda (serverless computing), AWS CodePipeline (CI/CD), and CloudFormation (IaC), which are essential for building and managing cloud-native applications.
|
||||
* **Microsoft Azure**: Azure is a close competitor to AWS, particularly strong in enterprise environments where Microsoft technologies like Windows Server, SQL Server, and .NET are prevalent. Azure offers a very rich list of cloud services, including, like the other two, virtual machines, AI, and machine learning tools. Azure also offers DevOps-specific services like Azure DevOps, which integrates CI/CD, version control, and agile planning into a single platform. Azure's hybrid cloud capabilities also make it a popular choice for organizations that need to integrate on-premises infrastructure with cloud resources.
|
||||
* **Google Cloud Platform (GCP)**: GCP, while newer to the cloud market compared to AWS and Azure, has quickly gained a reputation for its data analytics, machine learning, and container orchestration services. Google’s Kubernetes Engine (GKE), for instance, is quite liked by the DevOps community for managing containerized applications at scale. GCP is also known for its strong support of open-source technologies, making it a favorite among developers who prioritize flexibility and innovation.
|
||||
|
||||
### Understanding Cloud-Native Tools, Services, and Architectural Patterns
|
||||
|
||||
Another key technical skill for DevOps engineers is to understand not only cloud-native tools and services but also the architectural patterns that define modern application development.
|
||||
|
||||
These patterns define how applications are structured and interact with cloud infrastructure, directly affecting areas such as scalability, resilience, and maintainability.
|
||||
|
||||
* **Microservices Architecture**: In a microservices architecture, applications are composed of small, independent services that communicate over APIs. Key tools to understand by DevOps engineers include **API gateways** (like AWS API Gateway), **service meshes** (such as Istio), and **message queues** (like Amazon SQS or Google Pub/Sub).
|
||||
* **Service-Oriented Architecture (SOA)**: SOA is a broader (and older) architectural style where services are designed to provide specific business functionalities and can communicate with each other over a network. Tools like **Enterprise Service Buses (ESBs)** and **message brokers** (such as RabbitMQ) are often used to facilitate SOA architectures.
|
||||
* **Serverless Architecture**: Serverless computing allows developers to build and deploy applications without managing the underlying infrastructure. In a serverless architecture, code is executed in response to events, such as HTTP requests or changes in data, using services like **AWS Lambda**, **Azure Functions**, or **Google Cloud Functions**.
|
||||
* **Event-Driven Architecture**: In an event-driven architecture, applications respond to events in real-time, often using tools like **event streams** (e.g., Apache Kafka) and **message queues**.
|
||||
|
||||
## 6\. Monitoring and Logging!
|
||||
|
||||
[monitoring logging servers][https://assets.roadmap.sh/guest/monitoring-logging-servers-ztf1a.png]
|
||||
|
||||
Monitoring and logging are vital components of a robust DevOps strategy. They provide visibility into the health and performance of your systems, allowing you to detect issues early, troubleshoot, and ensure the reliability of your applications.
|
||||
|
||||
### Importance of Monitoring and Logging for Maintaining System Health
|
||||
|
||||
No matter what type of application you’re running, maintaining the health and performance of your systems is crucial if your business depends on it.
|
||||
|
||||
Monitoring and logging has turned into one of the most relevant DevOps skills out there.
|
||||
|
||||
Through monitoring you can track the performance of your infrastructure and applications in real-time, alerting you to any potential problems such as resource bottlenecks, slowdowns, or outages.
|
||||
|
||||
Logging, on the other hand, captures detailed records of system events and user interactions, providing invaluable information for diagnosing problems and understanding system behavior.
|
||||
|
||||
The reasons why you want to have effective monitoring and logging, are:
|
||||
|
||||
* **Proactive Issue Detection**: By continuously monitoring system metrics, you can detect issues before they escalate into critical problems, reducing downtime and improving overall system reliability.
|
||||
* **Troubleshooting and Root Cause Analysis**: Logs provide detailed information about system events, making it easier to pinpoint the root cause of issues. This speeds up the resolution process and minimizes the impact on users.
|
||||
* **Performance Optimization**: Monitoring allows you to track key performance indicators (KPIs) and identify areas where your systems can be optimized, leading to better resource utilization and cost savings.
|
||||
* **Compliance and Auditing**: Logging is essential for maintaining compliance with regulatory requirements. Logs can be used to audit system access, track changes, and ensure that your systems meet security and operational standards.
|
||||
|
||||
### Key Tools for Monitoring: Prometheus, Grafana, Nagios
|
||||
|
||||
Several tools have become essential for monitoring systems in DevOps environments. Each offers unique features tailored to different needs, from real-time metrics collection to visual dashboards and alerting.
|
||||
|
||||
* **Prometheus**: Prometheus is an open-source monitoring tool designed for reliability and scalability. It collects real-time metrics from your systems and applications, stores them in a time-series database, and supports powerful query languages for analysis.
|
||||
* **Grafana**: Grafana is a popular open-source platform for visualizing monitoring data. It integrates with Prometheus and other data sources, allowing you to create interactive, customizable dashboards that provide insights into system performance at a glance.
|
||||
* **Nagios**: Nagios is one of the oldest and most widely used monitoring tools. It provides comprehensive monitoring of network services, host resources, and infrastructure components.
|
||||
|
||||
### Logging Tools: ELK Stack (Elasticsearch, Logstash, Kibana), Splunk
|
||||
|
||||
Effective logging requires tools that can collect, store, and analyze large volumes of log data efficiently, given how much information modern systems can generate.
|
||||
|
||||
The following tools are among the most widely used in the industry:
|
||||
|
||||
* **ELK Stack**: The ELK Stack is a powerful open-source solution for managing logs. It consists of **Elastic** for storing and searching logs, **Logstash** to act as a data processing/ingestion pipeline, and **Kibana** for data visualization.
|
||||
* **Splunk**: Splunk is a commercial tool that offers advanced log management and analysis capabilities. It can ingest data from a wide variety of sources, index it in real time, and provide powerful search and reporting features.
|
||||
|
||||
### Best Practices for Setting Up Effective Monitoring and Logging Systems
|
||||
|
||||
While both practices are crucial for a successful DevOps strategy, if you ignore best practices the results you’ll get will be subpar, at best.
|
||||
|
||||
Instead, try to follow these (or some of them) guidelines to ensure you get the most out of your monitoring and logging efforts.
|
||||
|
||||
1. **Define Clear Objectives**: Before setting up your monitoring and logging systems, define what you want to achieve. Identify the key metrics and logs that are most critical to your operations, such as CPU usage, memory consumption, application response times, and error rates.
|
||||
2. **Implement Comprehensive Monitoring**: Monitor all layers of your infrastructure, from hardware and networks to applications and services. Use a combination of tools to ensure that no aspect of your system goes unmonitored. If you ignore one area, you’ll end up having blindspots when debugging and trying to troubleshoot problems.
|
||||
3. **Centralize Log Management**: Centralizing your logs in a single platform like the ELK Stack or Splunk allows for easier management, search, and analysis. This centralization is particularly important in distributed systems where logs are generated across multiple servers and services.
|
||||
4. **Set Up Alerts and Notifications**: Monitoring without alerting is like watching a movie without any sound; if you constantly pay attention to the picture, you might figure out what’s happening on a general level, but you’ll miss the details. And with monitoring, it’s the same thing: set up alerts and notifications so when a threshold is exceeded (say, the number of error responses in the last 10 minutes), you’ll know, even if it’s in the middle of the night.
|
||||
5. **Ensure Scalability**: As your infrastructure grows, your monitoring and logging systems need to scale accordingly. Choose tools that can handle increasing volumes of data without compromising performance. In other words, don’t turn your logging/monitoring setup into a bottleneck for your platform.
|
||||
6. **Regularly Review and Tune**: Continuously review and adjust your monitoring and logging configurations. As your systems evolve, your monitoring and logging needs may change, requiring you to add new metrics, refine alert thresholds, or optimize data retention policies.
|
||||
7. **Secure Your Monitoring and Logging Infrastructure**: Protect your monitoring and logging data from unauthorized access. Ensure that logs containing sensitive information are encrypted and access to monitoring dashboards is restricted based on roles.
|
||||
|
||||
## 7\. Security Practices and Tools (DevSecOps)
|
||||
|
||||
As DevOps has transformed software development by integrating development and operations teams together into a seamless process, security can no longer be treated as an afterthought. The rise of DevSecOps emphasizes the need for DevOps engineers to develop their security skills.
|
||||
|
||||
### Integrating Security into the DevOps Pipeline
|
||||
|
||||
DevSecOps shifts the classical paradigm (having security reviews happen at the end of the development lifecycle) by integrating security into every phase of the DevOps pipeline—from code development to deployment and beyond. That, in turn, involves the following:
|
||||
|
||||
* **Shift-Left Security**: This principle involves moving security practices earlier in the SDLC, such as during the coding and design phases.
|
||||
* **Continuous Security**: Security checks should be continuous and automated throughout the pipeline. This ensures that each code change, build, and deployment is evaluated for security risks.
|
||||
* **Collaboration and Culture**: DevSecOps is as much about culture as it is about tools. Developers, operations, and security teams must collaborate closely, sharing responsibility for security.
|
||||
|
||||
### Key Security Practices
|
||||
|
||||
To effectively integrate security into the DevOps pipeline, certain practices are essential:
|
||||
|
||||
* **Automated Security Testing**: Automation is key to scaling security practices within a rapidly growing DevOps environment. Automated security testing involves integrating security checks into your CI/CD pipelines. This can include static application security testing (SAST) to analyze source code for security flaws, dynamic application security testing (DAST) to evaluate running applications, and interactive application security testing (IAST) that combines both approaches.
|
||||
* **Vulnerability Scanning**: Regular vulnerability scanning is crucial for identifying and mitigating risks across your infrastructure and applications. Scanning tools can detect known vulnerabilities in code, dependencies, container images, and cloud configurations.
|
||||
* **Security as Code**: Just as Infrastructure as Code (IaC) treats infrastructure configuration as code, Security as Code applies the same principles to security configurations. This involves automating the provisioning and management of security controls, policies, and compliance checks.
|
||||
|
||||
### Tools for DevSecOps
|
||||
|
||||
Several tools have emerged to support the integration of security into the DevOps practice. These tools help automate security tasks, identify vulnerabilities, and enforce security policies, making it easier for teams to adopt DevSecOps practices.
|
||||
|
||||
Some examples are:
|
||||
|
||||
* **Aqua Security**: Aqua Security specializes in securing cloud-native applications, particularly those that run in containers. Aqua provides a comprehensive platform for securing the entire container lifecycle, from development to runtime.
|
||||
* **Snyk**: Snyk is a developer-friendly security platform that helps identify and fix vulnerabilities in open-source libraries, container images, and infrastructure as code. Snyk integrates with CI/CD pipelines, providing automated security testing and real-time feedback.
|
||||
* **Trivy**: Trivy is an open-source vulnerability scanner that is particularly well-suited for container environments. It scans container images, file systems, and Git repositories for known vulnerabilities, misconfigurations, and secrets.
|
||||
|
||||
## 8\. Networking and System Administration
|
||||
|
||||

|
||||
|
||||
Networking and system administration are foundational DevOps skills. These disciplines ensure that the infrastructure supporting your applications is robust, secure, and efficient.
|
||||
|
||||
### Which networking concepts are most relevant to DevOps?
|
||||
|
||||
Networking is the backbone of any IT infrastructure, connecting systems, applications, and users. A solid understanding of networking concepts is crucial for DevOps engineers to design, deploy, and manage systems effectively.
|
||||
|
||||
Some of the most important concepts include:
|
||||
|
||||
* **TCP/IP Networking**: TCP/IP (Transmission Control Protocol/Internet Protocol) is the fundamental protocol suite for the Internet and most private networks. Understanding how TCP/IP works is essential.
|
||||
* **Network Topologies**: Network topology refers to the arrangement of different elements (links, nodes, etc.) in a computer network. Common topologies include star, mesh, and hybrid configurations.
|
||||
* **Load Balancing**: Load balancing is the process of distributing network or application traffic across multiple servers to ensure no single server becomes overwhelmed. DevOps engineers need to understand different load balancing algorithms (round-robin, least connections, IP hash) and how to implement load balancers (like NGINX, HAProxy, or cloud-native solutions).
|
||||
* **Firewalls and Security Groups**: Firewalls are essential for controlling incoming and outgoing network traffic based on predetermined security rules. In cloud environments, security groups serve a similar function by acting as virtual firewalls for instances.
|
||||
* **DNS (Domain Name System)**: DNS is the system that translates human-readable domain names (like [www.example.com](http://www.example.com)) into IP addresses that computers use to identify each other on the network.
|
||||
* **VPNs and Secure Communication**: Virtual Private Networks (VPNs) allow secure communication over public networks by encrypting data between remote devices and the network.
|
||||
|
||||
### System Administration Tasks and Best Practices
|
||||
|
||||
System administration involves the management of computer systems, including servers, networks, and applications. DevOps engineers often take on system administration tasks to ensure that infrastructure is stable, secure, and performing optimally.
|
||||
|
||||
Some of these tasks include:
|
||||
|
||||
* **User and Permission Management**: Managing user accounts, groups, and permissions is fundamental to system security.
|
||||
* **Server Configuration and Management**: Configuring servers to meet the needs of applications and ensuring they run efficiently is a core task.
|
||||
* **System Monitoring and Maintenance**: As we’ve already mentioned, regular monitoring of system performance metrics is essential for proactive maintenance.
|
||||
* **Backup and Recovery**: Regular backups of data and configurations are crucial for disaster recovery.
|
||||
* **Patch Management**: Keeping systems up to date with the latest security patches and software updates is critical for maintaining your infrastructure secure.
|
||||
* **Security Hardening**: Security hardening involves reducing the attack surface of a system by configuring systems securely, removing unnecessary services, and applying best practices.
|
||||
* **Script Automation**: Developing your automation skills is key, as you’ll be automating routine tasks with scripts every day. Common scripting languages include Bash for Linux and PowerShell for Windows.
|
||||
|
||||
### Best Practices for Networking and System Administration
|
||||
|
||||
1. **Automate Repetitive Tasks**: Use automation tools and scripts to handle routine tasks such as backups, patch management, and monitoring setup.
|
||||
2. **Implement Redundancy and Failover**: Design your network and systems with redundancy and failover mechanisms. This includes setting up redundant network paths, using load balancers, and configuring failover for critical services to minimize downtime.
|
||||
3. **Enforce Strong Security Practices**: Regularly audit user access, apply patches promptly, and follow security best practices for hardening systems.
|
||||
4. **Regularly Review and Update Documentation**: Keep detailed documentation of your network configurations, system setups, and processes.
|
||||
5. **Monitor Proactively**: Set up comprehensive monitoring for all critical systems and networks. Alerts should be used to catch issues early, and logs should be reviewed regularly to spot potential security or performance issues.
|
||||
6. **Test Disaster Recovery Plans**: Regularly test your backup and disaster recovery procedures to ensure they work as expected.
|
||||
|
||||
## 9\. Familiarity with Version Control Systems
|
||||
|
||||
Version control systems (VCS) are at the center of modern software development, enabling teams to collaborate, track changes, and manage their codebase.
|
||||
|
||||
In a DevOps environment, where continuous integration and continuous deployment (CI/CD) are central practices, mastering version control is not just beneficial—it's essential.
|
||||
|
||||
### Importance of Version Control in DevOps Workflows
|
||||
|
||||
Version control is crucial in DevOps for several reasons:
|
||||
|
||||
* **Collaboration**: Version control systems allow multiple developers to work on the same codebase simultaneously without overwriting each other's changes.
|
||||
* **Change Tracking**: Every change to the codebase is tracked, with a history of who made the change, when, and why.
|
||||
* **Branching and Merging**: Version control systems enable the creation of branches, allowing developers to work on new features, bug fixes, or experiments in isolation.
|
||||
* **Continuous Integration/Continuous Deployment (CI/CD)**: Version control is crucial to CI/CD pipelines, where code changes are automatically tested, integrated, and deployed.
|
||||
* **Disaster Recovery**: In case of errors or issues, version control allows you to revert to previous stable versions of the codebase, minimizing downtime and disruption.
|
||||
|
||||
### Mastering Git: Key Commands, Workflows, and Best Practices
|
||||
|
||||
Git is the most widely used version control system in the DevOps world, known for its flexibility, performance, and breadth of features. Having a deep understanding of Git is crucial for any DevOps engineer, as it is the foundation upon which most CI/CD workflows are built.
|
||||
|
||||
The key commands you should try to master first are `init`, `clone`, `commit`, `pull`/`push`, `branch`, `checkout`, `merge`, and one that is definitely useful in your context: `log`.
|
||||
|
||||
#### Git Workflows
|
||||
|
||||
Git can be used as the driving force for your development workflow. However, there are many ways to use it. Some of the most common ones are:
|
||||
|
||||
* **Feature Branch Workflow**: Developers create a new branch for each feature or bug fix. Once complete, the branch is merged back into the main branch, often through a pull request, where code reviews and automated tests are conducted.
|
||||
* **Gitflow Workflow**: A more structured workflow that uses feature branches, a develop branch for integration, and a master branch for production-ready code. It also includes hotfix branches for urgent bug fixes in production.
|
||||
* **Forking Workflow**: Common in open-source projects, this workflow involves forking a repository, making changes in the fork, and then submitting a pull request to the original repository for review and integration.
|
||||
|
||||
#### Best practices when using Git
|
||||
|
||||
* **Commit Often, Commit Early**: Make small, frequent commits with clear, descriptive messages. This practice makes it easier to track changes and revert specific parts of the codebase if needed.
|
||||
* **Use Meaningful Branch Names**: Name branches based on the work they are doing, such as `feature/user-authentication` or `bugfix/login-issue`.
|
||||
* **Perform Code Reviews**: Use pull requests and code reviews as part of the merge process.
|
||||
* **Keep a Clean Commit History**: Use tools like `git rebase` to clean up your commit history before merging branches. A clean commit history makes it easier to understand the evolution of the project and debug issues.
|
||||
* **Resolve Conflicts Early**: When working on shared branches, regularly pull changes from the remote repository to minimize and resolve merge conflicts as early as possible.
|
||||
|
||||
### Tools for Managing Version Control: GitHub, GitLab, Bitbucket
|
||||
|
||||
While Git itself is a command-line tool, various platforms provide user-friendly interfaces and additional features to manage Git repositories effectively.
|
||||
|
||||
* **GitHub**: GitHub is the most popular platform for hosting Git repositories. It offers many collaboration features and on top of them, GitHub Actions integrates CI/CD directly into the platform, automating workflows from development to deployment.
|
||||
* **GitLab**: GitLab is a complete DevOps platform that includes Git repository management, CI/CD, issue tracking, and more. GitLab can be hosted on-premises, which is a significant advantage for organizations with strict data security requirements.
|
||||
* **Bitbucket**: Bitbucket, developed by Atlassian, integrates tightly with other Atlassian tools like Jira and Confluence. It supports Git and Mercurial and offers features like pull requests, code reviews, and CI/CD pipelines through Bitbucket Pipelines.
|
||||
|
||||
As usual, the right set of DevOps tools will drastically depend on your specific context and needs.
|
||||
|
||||
## 10\. Knowledge of Configuration Management
|
||||
|
||||
Configuration management is a critical component of DevOps, enabling teams to automate the setup and maintenance of systems and applications across different environments.
|
||||
|
||||
### The Role of Configuration Management in DevOps
|
||||
|
||||
This practice involves maintaining the consistency of a system's performance and functionality by ensuring that its configurations are properly set up and managed.
|
||||
|
||||
In DevOps, where continuous integration and continuous deployment (CI/CD) are key practices, understanding how to manage your configurations ensures that environments are consistently configured, regardless of where they are deployed.
|
||||
|
||||
Configure once and deploy endless times; that’s the DevOps way.
|
||||
|
||||
The main reasons why this is such an important practice in DevOps are:
|
||||
|
||||
* **Automation tools**: These tools automate the process of setting up and maintaining infrastructure, reducing manual effort and minimizing the risk of human error.
|
||||
* **Consistency Across Environments**: By defining configurations as code, conf. management ensures that all environments are configured identically.
|
||||
* **Scalability**: As systems scale, manually managing configurations becomes impractical. Configuration management allows you to scale infrastructure and applications, ensuring that new instances are configured correctly from the start.
|
||||
* **Compliance and Auditing**: These tools provide a clear and auditable record of system configurations. This is essential for compliance with industry standards and regulations.
|
||||
* **Disaster Recovery**: In the event of a system failure, configuration management tools can quickly restore systems to their desired state, reducing downtime and minimizing the impact on business operations.
|
||||
|
||||
### DevOps Configuration Management Tools to Master
|
||||
|
||||
Several tools have become staples in this landscape, each offering unique features and strengths. For example:
|
||||
|
||||
* **Ansible**: Ansible, developed by Red Hat, is an open-source tool known for its simplicity and ease of use. It uses YAML for configuration files, known as playbooks, which are easy to read and write. Ansible is ideal for automating tasks like software installation, service management, and configuration updates across multiple servers.
|
||||
* **Puppet**: Puppet is a powerful tool that uses a declarative language to define system configurations. Puppet’s strength lies in its scalability and ability to manage large, complex environments.
|
||||
* **Chef**: Chef is another popular tool that uses a Ruby-based DSL (Domain-Specific Language) to write recipes and cookbooks, which define how systems should be configured and managed.
|
||||
|
||||
### Best Practices for Managing Configurations Across Environments
|
||||
|
||||
Effective configuration management requires you to follow best practices that ensure consistency, reliability, and security across all environments.
|
||||
|
||||
1. **Use Configuration as Code (CaC)**: Treat configurations as code by storing them in version control systems like Git.
|
||||
2. **Modularize Configurations**: Break down configurations into reusable modules or roles. This approach allows you to apply the same configuration logic across different environments.
|
||||
3. **Test Configurations in Multiple Environments**: Before deploying configurations to production, test them thoroughly in staging or testing environments.
|
||||
4. **Implement Idempotency**: Ensure that your processes are idempotent, meaning that applying the same configuration multiple times does not change the system after the first application.
|
||||
5. **Centralization**: Use a centralized tool to maintain a single source of truth for all configurations.
|
||||
6. **Encrypt Sensitive Data**: When managing configurations that include sensitive data (e.g., passwords, API keys), use encryption and secure storage solutions like HashiCorp Vault.
|
||||
7. **Document Configurations and Changes**: Maintain detailed documentation for your configurations and any changes made to them.
|
||||
8. **Monitor and Audit Configurations**: Continuously monitor configurations to detect and prevent drift (when configurations deviate from the desired state).
|
||||
|
||||
## Bonus: Collaboration and Communication Skills
|
||||
|
||||
While technical skills are critical to becoming a successful DevOps engineer, the importance of soft skills—particularly collaboration and communication—cannot be ignored.
|
||||
|
||||
In a DevOps environment, where cross-functional teams work closely together to deliver software, effective communication, and collaboration are essential for success.
|
||||
|
||||
### Importance of Soft Skills in a DevOps Environment
|
||||
|
||||
DevOps is not just about tools and processes; it's also about people and how they work together.
|
||||
|
||||
Key reasons why soft skills are crucial in a DevOps environment:
|
||||
|
||||
* **Cross-Functional Collaboration**: DevOps brings together diverse teams with different expertise—developers, operations, QA, security, and more.
|
||||
* **Problem Solving and Conflict Resolution**: In software development in general, issues and conflicts are inevitable. Strong communication skills help teams navigate these challenges, finding quick resolutions and keeping the focus on delivering value to the customer.
|
||||
* **Agility and Adaptability**: DevOps teams often need to adapt to changing requirements and priorities. Effective communication ensures that these changes are understood and implemented without issues.
|
||||
|
||||
### Tools for Effective Collaboration: Slack, Microsoft Teams, Jira
|
||||
|
||||
Several tools are essential for facilitating communication and collaboration in a DevOps environment.
|
||||
|
||||
Is there an absolute best one? The answer to that question is “no.”, the best option depends on your needs and preferences, so study the list and figure out yourself which software (or combination of) helps your specific teams.
|
||||
|
||||
* **Slack**: Slack is a popular communication platform designed for team collaboration. It offers integration with other DevOps tools like GitHub, Jenkins, and Jira.
|
||||
* **Microsoft Teams**: Microsoft Teams is another powerful collaboration tool, especially popular in organizations using the Microsoft ecosystem.
|
||||
* **Jira**: Jira, developed by Atlassian, is a robust project management tool that helps teams track work, manage backlogs, and plan sprints. It’s particularly useful in Agile and DevOps environments where transparency and continuous improvement are key.
|
||||
|
||||
### Best Practices for Fostering a Collaborative Culture
|
||||
|
||||
Building a collaborative culture in a DevOps environment requires effort and ongoing commitment.
|
||||
|
||||
Here are some general guidelines you can follow to help achieve that collaborative environment:
|
||||
|
||||
1. **Promote Open Communication**: Encourage team members to communicate openly about their work, challenges, and ideas.
|
||||
2. **Regular Stand-Ups and Check-Ins**: Implement daily stand-ups or regular check-ins to ensure that everyone is on the same page. Whether they’re in person, during a video call, or asynchronous, these check-ins help find blockers and solve them fast.
|
||||
3. **Use Collaborative Documentation**: Maintain shared documentation using tools like Confluence or Google Docs.
|
||||
4. **Encourage Cross-Functional Training**: Facilitate training sessions or workshops where team members from different disciplines can learn about each other's work.
|
||||
5. **Foster a Blameless Culture**: In a DevOps environment, mistakes and failures should be viewed as learning opportunities rather than reasons to assign blame. Encourage a blameless culture where issues are discussed openly, and the focus is on understanding the root cause.
|
||||
|
||||
## Conclusion
|
||||
|
||||
In the world of DevOps, mastering a diverse set of skills is not an option but rather an absolute must. From understanding the details of cloud computing and infrastructure as code to implementing monitoring and security practices, each skill plays a crucial role in fulfilling the main goal of any DevOps practice: enabling fast, reliable, and secure software delivery.
|
||||
|
||||
For those looking to deepen their understanding or get started on their DevOps journey, here are some valuable resources:
|
||||
|
||||
* [**Expanded DevOps Roadmap**](https://roadmap.sh/devops): A comprehensive guide that details the full range of DevOps skills, tools, and technologies you need to master as a DevOps engineer.
|
||||
* [**Simplified DevOps Roadmap**](https://roadmap.sh/devops?r=devops-beginner): A more streamlined version that highlights the core components of a DevOps career, making it easier for beginners to navigate the field.
|
||||
|
||||
Success in DevOps is about cultivating a well-rounded skill set that combines technical expertise with strong collaboration, communication, and problem-solving abilities.
|
||||
|
||||
As the industry continues to evolve, so too will the tools, practices, and challenges that DevOps engineers face. By committing to continuous learning and staying adaptable, you can ensure that you remain at the forefront of this dynamic field, driving innovation and delivering value in your organization.
|
||||
@@ -0,0 +1,11 @@
|
||||
# MVI
|
||||
|
||||
The **MVI** `Model-View-Intent` pattern is a reactive architectural pattern, similar to **MVVM** and **MVP**, focusing on immutability and handling states in unidirectional cycles. The data flow is unidirectional: Intents update the Model's state through the `ViewModel`, and then the View reacts to the new state. This ensures a clear and predictable cycle between logic and the interface.
|
||||
|
||||
- Model: Represents the UI state. It is immutable and contains all the necessary information to represent a screen.
|
||||
- View: Displays the UI state and receives the user's intentions.
|
||||
- Intent: The user's intentions trigger state updates, managed by the `ViewModel`.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@MVI with Kotlin](https://proandroiddev.com/mvi-architecture-with-kotlin-flows-and-channels-d36820b2028d)
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# ACID
|
||||
|
||||
ACID are the four properties of relational database systems that help in making sure that we are able to perform the transactions in a reliable manner. It's an acronym which refers to the presence of four properties: atomicity, consistency, isolation and durability
|
||||
ACID is an acronym representing four key properties that guarantee reliable processing of database transactions. It stands for Atomicity, Consistency, Isolation, and Durability. Atomicity ensures that a transaction is treated as a single, indivisible unit that either completes entirely or fails completely. Consistency maintains the database in a valid state before and after the transaction. Isolation ensures that concurrent transactions do not interfere with each other, appearing to execute sequentially. Durability guarantees that once a transaction is committed, it remains so, even in the event of system failures. These properties are crucial in maintaining data integrity and reliability in database systems, particularly in scenarios involving multiple, simultaneous transactions or where data accuracy is critical, such as in financial systems or e-commerce platforms.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
|
||||
@@ -1,9 +1,10 @@
|
||||
# Apache
|
||||
|
||||
Apache is a free, open-source HTTP server, available on many operating systems, but mainly used on Linux distributions. It is one of the most popular options for web developers, as it accounts for over 30% of all the websites, as estimated by W3Techs.
|
||||
Apache, officially known as the Apache HTTP Server, is a free, open-source web server software developed and maintained by the Apache Software Foundation. It's one of the most popular web servers worldwide, known for its robustness, flexibility, and extensive feature set. Apache supports a wide range of operating systems and can handle various content types and programming languages through its modular architecture. It offers features like virtual hosting, SSL/TLS support, and URL rewriting. Apache's configuration files allow for detailed customization of server behavior. While it has faced competition from newer alternatives like Nginx, especially in high-concurrency scenarios, Apache remains widely used due to its stability, comprehensive documentation, and large community support. It's particularly favored for its ability to integrate with other open-source technologies in the LAMP (Linux, Apache, MySQL, PHP/Perl/Python) stack.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Apache Server Website](https://httpd.apache.org/)
|
||||
- [@official@Apache Server Website](https://httpd.apache.org/)
|
||||
- [@video@What is Apache Web Server?](https://www.youtube.com/watch?v=kaaenHXO4t4)
|
||||
- [@video@Apache vs NGINX](https://www.youtube.com/watch?v=9nyiY-psbMs)
|
||||
- [@feed@Explore top posts about Apache](https://app.daily.dev/tags/apache?ref=roadmapsh)
|
||||
|
||||
@@ -1,20 +1,9 @@
|
||||
# Authentication
|
||||
|
||||
The API authentication process validates the identity of the client attempting to make a connection by using an authentication protocol. The protocol sends the credentials from the remote client requesting the connection to the remote access server in either plain text or encrypted form. The server then knows whether it can grant access to that remote client or not.
|
||||
|
||||
Here is the list of common ways of authentication:
|
||||
|
||||
- JWT Authentication
|
||||
- Token based Authentication
|
||||
- Session based Authentication
|
||||
- Basic Authentication
|
||||
- OAuth - Open Authorization
|
||||
- SSO - Single Sign On
|
||||
API authentication is the process of verifying the identity of clients attempting to access an API, ensuring that only authorized users or applications can interact with the API's resources. Common methods include API keys, OAuth 2.0, JSON Web Tokens (JWT), basic authentication, and OpenID Connect. These techniques vary in complexity and security level, from simple token-based approaches to more sophisticated protocols that handle both authentication and authorization. API authentication protects sensitive data, prevents unauthorized access, enables usage tracking, and can provide granular control over resource access. The choice of authentication method depends on factors such as security requirements, types of clients, ease of implementation, and scalability needs. Implementing robust API authentication is crucial for maintaining the integrity, security, and controlled usage of web services and applications in modern, interconnected software ecosystems.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@User Authentication: Understanding the Basics & Top Tips](https://swoopnow.com/user-authentication/)
|
||||
- [@article@An overview about authentication methods](https://betterprogramming.pub/how-do-you-authenticate-mate-f2b70904cc3a)
|
||||
- [@roadmap.sh@SSO - Single Sign On](https://roadmap.sh/guides/sso)
|
||||
- [@roadmap.sh@OAuth - Open Authorization](https://roadmap.sh/guides/oauth)
|
||||
- [@roadmap.sh@JWT Authentication](https://roadmap.sh/guides/jwt-authentication)
|
||||
|
||||
@@ -1,11 +1,9 @@
|
||||
# AWS Neptune
|
||||
|
||||
AWS Neptune is a fully managed graph database service designed for applications that require highly connected data.
|
||||
Amazon Neptune is a fully managed graph database service provided by Amazon Web Services (AWS). It's designed to store and navigate highly connected data, supporting both property graph and RDF (Resource Description Framework) models. Neptune uses graph query languages like Gremlin and SPARQL, making it suitable for applications involving complex relationships, such as social networks, recommendation engines, fraud detection systems, and knowledge graphs. It offers high availability, with replication across multiple Availability Zones, and supports up to 15 read replicas for improved performance. Neptune integrates with other AWS services, provides encryption at rest and in transit, and offers fast recovery from failures. Its scalability and performance make it valuable for handling large-scale, complex data relationships in enterprise-level applications.
|
||||
|
||||
It supports two popular graph models: Property Graph and RDF (Resource Description Framework), allowing you to build applications that traverse billions of relationships with millisecond latency.
|
||||
Learn more from the following resources:
|
||||
|
||||
Neptune is optimized for storing and querying graph data, making it ideal for use cases like social networks, recommendation engines, fraud detection, and knowledge graphs.
|
||||
|
||||
It offers high availability, automatic backups, and multi-AZ (Availability Zone) replication, ensuring data durability and fault tolerance.
|
||||
|
||||
Additionally, Neptune integrates seamlessly with other AWS services and supports open standards like Gremlin, SPARQL, and Apache TinkerPop, making it flexible and easy to integrate into existing applications.
|
||||
- [@official@AWS Neptune Website](https://aws.amazon.com/neptune/)
|
||||
- [@video@Getting Started with Neptune Serverless](https://www.youtube.com/watch?v=b04-jjM9t4g)
|
||||
- [@article@Setting Up Amazon Neptune Graph Database](https://cliffordedsouza.medium.com/setting-up-amazon-neptune-graph-database-2b73512a7388)
|
||||
@@ -1,15 +1,9 @@
|
||||
# Backpressure
|
||||
|
||||
Backpressure is a design pattern that is used to manage the flow of data through a system, particularly in situations where the rate of data production exceeds the rate of data consumption. It is commonly used in cloud computing environments to prevent overloading of resources and to ensure that data is processed in a timely and efficient manner.
|
||||
|
||||
There are several ways to implement backpressure in a cloud environment:
|
||||
|
||||
- Buffering: This involves storing incoming data in a buffer until it can be processed, allowing the system to continue receiving data even if it is temporarily unable to process it.
|
||||
- Batching: This involves grouping incoming data into batches and processing the batches in sequence, rather than processing each piece of data individually.
|
||||
- Flow control: This involves using mechanisms such as flow control signals or windowing to regulate the rate at which data is transmitted between systems.
|
||||
|
||||
Backpressure is an important aspect of cloud design, as it helps to ensure that data is processed efficiently and that the system remains stable and available. It is often used in conjunction with other design patterns, such as auto-scaling and load balancing, to provide a scalable and resilient cloud environment.
|
||||
Back pressure is a flow control mechanism in systems processing asynchronous data streams, where the receiving component signals its capacity to handle incoming data to the sending component. This feedback loop prevents overwhelming the receiver with more data than it can process, ensuring system stability and optimal performance. In software systems, particularly those dealing with high-volume data or event-driven architectures, back pressure helps manage resource allocation, prevent memory overflows, and maintain responsiveness. It's commonly implemented in reactive programming, message queues, and streaming data processing systems. By allowing the receiver to control the flow of data, back pressure helps create more resilient, efficient systems that can gracefully handle varying loads and prevent cascading failures in distributed systems.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Awesome Architecture: Backpressure](https://awesome-architecture.com/back-pressure/)
|
||||
- [@article@Backpressure explained — the resisted flow of data through software](https://medium.com/@jayphelps/backpressure-explained-the-flow-of-data-through-software-2350b3e77ce7)
|
||||
- [@video@What is Back Pressure](https://www.youtube.com/watch?v=viTGm_cV7lE)
|
||||
|
||||
@@ -1 +1,7 @@
|
||||
# Base
|
||||
# Base
|
||||
|
||||
Oracle Base Database Service enables you to maintain absolute control over your data while using the combined capabilities of Oracle Database and Oracle Cloud Infrastructure. Oracle Base Database Service offers database systems (DB systems) on virtual machines. They are available as single-node DB systems and multi-node RAC DB systems on Oracle Cloud Infrastructure (OCI). You can manage these DB systems by using the OCI Console, the OCI API, the OCI CLI, the Database CLI (DBCLI), Enterprise Manager, or SQL Developer.
|
||||
|
||||
Learn more from the following resources:
|
||||
|
||||
- [@official@Base Database Website](https://docs.oracle.com/en-us/iaas/base-database/index.html)
|
||||
@@ -1,11 +1,10 @@
|
||||
# Basic authentication
|
||||
|
||||
Given the name "Basic Authentication", you should not confuse Basic Authentication with the standard username and password authentication. Basic authentication is a part of the HTTP specification, and the details can be [found in the RFC7617](https://www.rfc-editor.org/rfc/rfc7617.html).
|
||||
|
||||
Because it is a part of the HTTP specifications, all the browsers have native support for "HTTP Basic Authentication".
|
||||
Basic Authentication is a simple HTTP authentication scheme built into the HTTP protocol. It works by sending a user's credentials (username and password) encoded in base64 format within the HTTP header. When a client makes a request to a server requiring authentication, the server responds with a 401 status code and a "WWW-Authenticate" header. The client then resends the request with the Authorization header containing the word "Basic" followed by the base64-encoded string of "username:password". While easy to implement, Basic Authentication has significant security limitations: credentials are essentially sent in plain text (base64 is easily decoded), and it doesn't provide any encryption. Therefore, it should only be used over HTTPS connections to ensure the credentials are protected during transmission. Due to its simplicity and lack of advanced security features, Basic Authentication is generally recommended only for simple, low-risk scenarios or as a fallback mechanism.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@roadmap.sh@HTTP Basic Authentication](https://roadmap.sh/guides/http-basic-authentication)
|
||||
- [@video@Basic Authentication in 5 minutes](https://www.youtube.com/watch?v=rhi1eIjSbvk)
|
||||
- [@video@Illustrated HTTP Basic Authentication](https://www.youtube.com/watch?v=mwccHwUn7Gc)
|
||||
- [@feed@Explore top posts about Authentication](https://app.daily.dev/tags/authentication?ref=roadmapsh)
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
# Bcrypt
|
||||
|
||||
bcrypt is a password hashing function, that has been proven reliable and secure since it's release in 1999. It has been implemented into most commonly-used programming languages.
|
||||
Bcrypt is a password-hashing function designed to securely hash passwords for storage in databases. Created by Niels Provos and David Mazières, it's based on the Blowfish cipher and incorporates a salt to protect against rainbow table attacks. Bcrypt's key feature is its adaptive nature, allowing for the adjustment of its cost factor to make it slower as computational power increases, thus maintaining resistance against brute-force attacks over time. It produces a fixed-size hash output, typically 60 characters long, which includes the salt and cost factor. Bcrypt is widely used in many programming languages and frameworks due to its security strength and relative ease of implementation. Its deliberate slowness in processing makes it particularly effective for password storage, where speed is not a priority but security is paramount.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@bcrypts npm package](https://www.npmjs.com/package/bcrypt)
|
||||
- [@article@Understanding bcrypt](https://auth0.com/blog/hashing-in-action-understanding-bcrypt/)
|
||||
- [@video@bcrypt explained](https://www.youtube.com/watch?v=O6cmuiTBZVs)
|
||||
- [@video@bcrypt explained](https://www.youtube.com/watch?v=AzA_LTDoFqY)
|
||||
|
||||
@@ -1,15 +1,10 @@
|
||||
# Bitbucket
|
||||
|
||||
Bitbucket is a Git based hosting and source code repository service that is Atlassian's alternative to other products like GitHub, GitLab etc
|
||||
|
||||
Bitbucket offers hosting options via Bitbucket Cloud (Atlassian's servers), Bitbucket Server (customer's on-premise) or Bitbucket Data Centre (number of servers in customers on-premise or cloud environment)
|
||||
Bitbucket is a web-based version control repository hosting service owned by Atlassian. It primarily uses Git version control systems, offering both cloud-hosted and self-hosted options. Bitbucket provides features such as pull requests for code review, branch permissions, and inline commenting on code. It integrates seamlessly with other Atlassian products like Jira and Trello, making it popular among teams already using Atlassian tools. Bitbucket supports continuous integration and deployment through Bitbucket Pipelines. It offers unlimited private repositories for small teams, making it cost-effective for smaller organizations. While similar to GitHub in many aspects, Bitbucket's integration with Atlassian's ecosystem and its pricing model for private repositories are key differentiators. It's widely used for collaborative software development, particularly in enterprise environments already invested in Atlassian's suite of products.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@official@Bitbucket Website](https://bitbucket.org/product)
|
||||
- [@official@Getting started with Bitbucket](https://bitbucket.org/product/guides/basics/bitbucket-interface)
|
||||
- [@article@Using Git with Bitbucket Cloud](https://www.atlassian.com/git/tutorials/learn-git-with-bitbucket-cloud)
|
||||
- [@official@A brief overview of Bitbucket](https://bitbucket.org/product/guides/getting-started/overview#a-brief-overview-of-bitbucket)
|
||||
- [@video@Bitbucket tutorial | How to use Bitbucket Cloud](https://www.youtube.com/watch?v=M44nEyd_5To)
|
||||
- [@video@Bitbucket Tutorial | Bitbucket for Beginners](https://www.youtube.com/watch?v=i5T-DB8tb4A)
|
||||
- [@feed@Explore top posts about Bitbucket](https://app.daily.dev/tags/bitbucket?ref=roadmapsh)
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
# Browsers
|
||||
|
||||
A web browser is a software application that enables a user to access and display web pages or other online content through its graphical user interface.
|
||||
Web browsers are software applications that enable users to access, retrieve, and navigate information on the World Wide Web. They interpret and display HTML, CSS, and JavaScript to render web pages. Modern browsers like Google Chrome, Mozilla Firefox, Apple Safari, and Microsoft Edge offer features such as tabbed browsing, bookmarks, extensions, and synchronization across devices. They incorporate rendering engines (e.g., Blink, Gecko, WebKit) to process web content, and JavaScript engines for executing code. Browsers also manage security through features like sandboxing, HTTPS enforcement, and pop-up blocking. They support various web standards and technologies, including HTML5, CSS3, and Web APIs, enabling rich, interactive web experiences. With the increasing complexity of web applications, browsers have evolved to become powerful platforms, balancing performance, security, and user experience in the ever-changing landscape of the internet.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@How Browsers Work](https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/)
|
||||
- [@article@Role of Rendering Engine in Browsers](https://www.browserstack.com/guide/browser-rendering-engine)
|
||||
- [@article@How Browsers Work](https://www.ramotion.com/blog/what-is-web-browser/)
|
||||
- [@article@Populating the Page: How Browsers Work](https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work)
|
||||
- [@video@How Do Web Browsers Work?](https://www.youtube.com/watch?v=5rLFYtXHo9s)
|
||||
- [@feed@Explore top posts about Browsers](https://app.daily.dev/tags/browsers?ref=roadmapsh)
|
||||
@@ -1,19 +1,8 @@
|
||||
# Building for Scale
|
||||
|
||||
Speaking in general terms, scalability is the ability of a system to handle a growing amount of work by adding resources to it.
|
||||
Speaking in general terms, scalability is the ability of a system to handle a growing amount of work by adding resources to it. A software that was conceived with a scalable architecture in mind, is a system that will support higher workloads without any fundamental changes to it, but don't be fooled, this isn't magic. You'll only get so far with smart thinking without adding more sources to it. When you think about the infrastructure of a scalable system, you have two main ways of building it: using on-premises resources or leveraging all the tools a cloud provider can give you.
|
||||
|
||||
A software that was conceived with a scalable architecture in mind, is a system that will support higher workloads without any fundamental changes to it, but don't be fooled, this isn't magic. You'll only get so far with smart thinking without adding more sources to it.
|
||||
|
||||
For a system to be scalable, there are certain things you must pay attention to, like:
|
||||
|
||||
- Coupling
|
||||
- Observability
|
||||
- Evolvability
|
||||
- Infrastructure
|
||||
|
||||
When you think about the infrastructure of a scalable system, you have two main ways of building it: using on-premises resources or leveraging all the tools a cloud provider can give you.
|
||||
|
||||
The main difference between on-premises and cloud resources will be FLEXIBILITY, on cloud providers you don't really need to plan ahead, you can upgrade your infrastructure with a couple of clicks, while with on-premises resources you will need a certain level of planning.
|
||||
The main difference between on-premises and cloud resources will be **flexibility**, on cloud providers you don't really need to plan ahead, you can upgrade your infrastructure with a couple of clicks, while with on-premises resources you will need a certain level of planning.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
|
||||
@@ -1,11 +1,10 @@
|
||||
# C\#
|
||||
|
||||
C# (pronounced "C sharp") is a general purpose programming language made by Microsoft. It is used to perform different tasks and can be used to create web apps, games, mobile apps, etc.
|
||||
C# (pronounced C-sharp) is a modern, object-oriented programming language developed by Microsoft as part of its .NET framework. It combines the power and efficiency of C++ with the simplicity of Visual Basic, featuring strong typing, lexical scoping, and support for functional, generic, and component-oriented programming paradigms. C# is widely used for developing Windows desktop applications, web applications with ASP.NET, games with Unity, and cross-platform mobile apps using Xamarin. It offers features like garbage collection, type safety, and extensive library support. C# continues to evolve, with regular updates introducing new capabilities such as asynchronous programming, nullable reference types, and pattern matching. Its integration with the .NET ecosystem and Microsoft's development tools makes it a popular choice for enterprise software development and large-scale applications.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@C# Learning Path](https://docs.microsoft.com/en-us/learn/paths/csharp-first-steps/?WT.mc_id=dotnet-35129-website)
|
||||
- [@course@C# Learning Path](https://docs.microsoft.com/en-us/learn/paths/csharp-first-steps/?WT.mc_id=dotnet-35129-website)
|
||||
- [@article@C# on W3 schools](https://www.w3schools.com/cs/index.php)
|
||||
- [@article@Introduction to C#](https://docs.microsoft.com/en-us/shows/CSharp-101/?WT.mc_id=Educationalcsharp-c9-scottha)
|
||||
- [@video@C# tutorials](https://www.youtube.com/watch?v=gfkTfcpWqAY\&list=PLTjRvDozrdlz3_FPXwb6lX_HoGXa09Yef)
|
||||
- [@video@Learn C# Programming – Full Course with Mini-Projects](https://www.youtube.com/watch?v=YrtFtdTTfv0)
|
||||
- [@feed@Explore top posts about C#](https://app.daily.dev/tags/c#?ref=roadmapsh)
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
# Caching
|
||||
|
||||
Caching is a technique of storing frequently used data or results of complex computations in a local memory, for a certain period. So, next time, when the client requests the same information, instead of retrieving the information from the database, it will give the information from the local memory. The main advantage of caching is that it improves performance by reducing the processing burden.
|
||||
|
||||
NB! Caching is a complicated topic that has obvious benefits but can lead to pitfalls like stale data, cache invalidation, distributed caching etc
|
||||
Caching is a technique used in computing to store and retrieve frequently accessed data quickly, reducing the need to fetch it from the original, slower source repeatedly. It involves keeping a copy of data in a location that's faster to access than its primary storage. Caching can occur at various levels, including browser caching, application-level caching, and database caching. It significantly improves performance by reducing latency, decreasing network traffic, and lowering the load on servers or databases. Common caching strategies include time-based expiration, least recently used (LRU) algorithms, and write-through or write-back policies. While caching enhances speed and efficiency, it also introduces challenges in maintaining data consistency and freshness. Effective cache management is crucial in balancing performance gains with the need for up-to-date information in dynamic systems.
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
# Caddy
|
||||
|
||||
The Caddy web server is an extensible, cross-platform, open-source web server written in Go. It has some really nice features like automatic SSL/HTTPs and a really easy configuration file.
|
||||
Caddy is a modern, open-source web server written in Go. It's known for its simplicity, automatic HTTPS encryption, and HTTP/2 support out of the box. Caddy stands out for its ease of use, with a simple configuration syntax and the ability to serve static files with zero configuration. It automatically obtains and renews SSL/TLS certificates from Let's Encrypt, making secure deployments straightforward. Caddy supports various plugins and modules for extended functionality, including reverse proxying, load balancing, and dynamic virtual hosting. It's designed with security in mind, implementing modern web standards by default. While it may not match the raw performance of servers like Nginx in extremely high-load scenarios, Caddy's simplicity, built-in security features, and low resource usage make it an attractive choice for many web hosting needs, particularly for smaller to medium-sized projects or developers seeking a hassle-free server setup.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Official Website](https://caddyserver.com/)
|
||||
- [@video@Getting started with Caddy the HTTPS Web Server from scratch](https://www.youtube.com/watch?v=t4naLFSlBpQ)
|
||||
- [@official@Official Website](https://caddyserver.com/)
|
||||
- [@opensource@caddyserver/caddy](https://github.com/caddyserver/caddy)
|
||||
- [@video@How to Make a Simple Caddy 2 Website](https://www.youtube.com/watch?v=WgUV_BlHvj0)
|
||||
|
||||
@@ -1,11 +1,10 @@
|
||||
# CAP Theorem
|
||||
|
||||
CAP is an acronym that stands for Consistency, Availability and Partition Tolerance. According to CAP theorem, any distributed system can only guarantee two of the three properties at any point of time. You can't guarantee all three properties at once.
|
||||
The CAP Theorem, also known as Brewer's Theorem, is a fundamental principle in distributed database systems. It states that in a distributed system, it's impossible to simultaneously guarantee all three of the following properties: Consistency (all nodes see the same data at the same time), Availability (every request receives a response, without guarantee that it contains the most recent version of the data), and Partition tolerance (the system continues to operate despite network failures between nodes). According to the theorem, a distributed system can only strongly provide two of these three guarantees at any given time. This principle guides the design and architecture of distributed systems, influencing decisions on data consistency models, replication strategies, and failure handling. Understanding the CAP Theorem is crucial for designing robust, scalable distributed systems and for choosing appropriate database solutions for specific use cases in distributed computing environments.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@What is CAP Theorem?](https://www.bmc.com/blogs/cap-theorem/)
|
||||
- [@article@CAP Theorem - Wikipedia](https://en.wikipedia.org/wiki/CAP_theorem)
|
||||
- [@article@An Illustrated Proof of the CAP Theorem](https://mwhittaker.github.io/blog/an_illustrated_proof_of_the_cap_theorem/)
|
||||
- [@article@CAP Theorem and its applications in NoSQL Databases](https://www.ibm.com/uk-en/cloud/learn/cap-theorem)
|
||||
- [@video@What is CAP Theorem?](https://www.youtube.com/watch?v=_RbsFXWRZ10)
|
||||
|
||||
@@ -1,11 +1,10 @@
|
||||
# Column Databases
|
||||
# Cassandra
|
||||
|
||||
A **<u>wide-column database</u>** (sometimes referred to as a column database) is similar to a relational database. It store data in tables, rows and columns. However in opposite to relational databases here each row can have its own format of the columns. Column databases can be seen as a two-dimensional key-value database. One of such database system is **Apache Cassandra**.
|
||||
|
||||
**Warning:** <a href="https://en.wikipedia.org/wiki/Wide-column_store#Wide-column_stores_versus_columnar_databases">note that a "columnar database" and a "column database" are two different terms!</a>
|
||||
Apache Cassandra is a highly scalable, distributed NoSQL database designed to handle large amounts of structured data across multiple commodity servers. It provides high availability with no single point of failure, offering linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure. Cassandra uses a masterless ring architecture, where all nodes are equal, allowing for easy data distribution and replication. It supports flexible data models and can handle both unstructured and structured data. Cassandra excels in write-heavy environments and is particularly suitable for applications requiring high throughput and low latency. Its data model is based on wide column stores, offering a more complex structure than key-value stores. Widely used in big data applications, Cassandra is known for its ability to handle massive datasets while maintaining performance and reliability.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Apache Cassandra](https://cassandra.apache.org/_/index.html)
|
||||
- [@official@Apache Cassandra](https://cassandra.apache.org/_/index.html)
|
||||
- [article@Cassandra - Quick Guide](https://www.tutorialspoint.com/cassandra/cassandra_quick_guide.htm)
|
||||
- [@video@Apache Cassandra - Course for Beginners](https://www.youtube.com/watch?v=J-cSy5MeMOA)
|
||||
- [@feed@Explore top posts about Backend Development](https://app.daily.dev/tags/backend?ref=roadmapsh)
|
||||
|
||||
@@ -1,12 +1,10 @@
|
||||
# CDN (Content Delivery Network)
|
||||
|
||||
A Content Delivery Network (CDN) service aims to provide high availability and performance improvements of websites. This is achieved with fast delivery of website assets and content typically via geographically closer endpoints to the client requests.
|
||||
Traditional commercial CDNs (Amazon CloudFront, Akamai, CloudFlare and Fastly) provide servers across the globe which can be used for this purpose.
|
||||
Serving assets and contents via a CDN reduces bandwidth on website hosting, provides an extra layer of caching to reduce potential outages and can improve website security as well
|
||||
Traditional commercial CDNs (Amazon CloudFront, Akamai, CloudFlare and Fastly) provide servers across the globe which can be used for this purpose. Serving assets and contents via a CDN reduces bandwidth on website hosting, provides an extra layer of caching to reduce potential outages and can improve website security as well
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@CloudFlare - What is a CDN? | How do CDNs work?](https://www.cloudflare.com/en-ca/learning/cdn/what-is-a-cdn/)
|
||||
- [@article@Wikipedia - Content Delivery Network](https://en.wikipedia.org/wiki/Content_delivery_network)
|
||||
- [@video@What is Cloud CDN?](https://www.youtube.com/watch?v=841kyd_mfH0)
|
||||
- [@video@What is a Content Delivery Network (CDN)?](https://www.youtube.com/watch?v=Bsq5cKkS33I)
|
||||
- [@video@What is a CDN and how does it work?](https://www.youtube.com/watch?v=RI9np1LWzqw)
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# CI/CD
|
||||
|
||||
CI/CD (Continuous Integration/Continuous Deployment) is the practice of automating building, testing, and deployment of applications with the main goal of detecting issues early, and provide quicker releases to the production environment.
|
||||
CI/CD (Continuous Integration/Continuous Delivery) is a set of practices and tools in software development that automate the process of building, testing, and deploying code changes. Continuous Integration involves frequently merging code changes into a central repository, where automated builds and tests are run. Continuous Delivery extends this by automatically deploying all code changes to a testing or staging environment after the build stage. Some implementations include Continuous Deployment, where changes are automatically released to production. CI/CD pipelines typically involve stages like code compilation, unit testing, integration testing, security scans, and deployment. This approach aims to improve software quality, reduce time to market, and increase development efficiency by catching and addressing issues early in the development cycle.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
@@ -8,6 +8,5 @@ Visit the following resources to learn more:
|
||||
- [@video@Automate your Workflows with GitHub Actions](https://www.youtube.com/watch?v=nyKZTKQS_EQ)
|
||||
- [@article@What is CI/CD?](https://about.gitlab.com/topics/ci-cd/)
|
||||
- [@article@A Primer: Continuous Integration and Continuous Delivery (CI/CD)](https://thenewstack.io/a-primer-continuous-integration-and-continuous-delivery-ci-cd/)
|
||||
- [@article@3 Ways to Use Automation in CI/CD Pipelines](https://thenewstack.io/3-ways-to-use-automation-in-ci-cd-pipelines/)
|
||||
- [@article@Articles about CI/CD](https://thenewstack.io/category/ci-cd/)
|
||||
- [@feed@Explore top posts about CI/CD](https://app.daily.dev/tags/cicd?ref=roadmapsh)
|
||||
|
||||
@@ -1,12 +1,9 @@
|
||||
# Circuit Breaker
|
||||
|
||||
The circuit breaker design pattern is a way to protect a system from failures or excessive load by temporarily stopping certain operations if the system is deemed to be in a failed or overloaded state. It is commonly used in cloud computing environments to prevent cascading failures and to improve the resilience and availability of a system.
|
||||
|
||||
A circuit breaker consists of three states: closed, open, and half-open. In the closed state, the circuit breaker allows operations to proceed as normal. If the system encounters a failure or becomes overloaded, the circuit breaker moves to the open state, and all subsequent operations are immediately stopped. After a specified period of time, the circuit breaker moves to the half-open state, and a small number of operations are allowed to proceed. If these operations are successful, the circuit breaker moves back to the closed state; if they fail, the circuit breaker moves back to the open state.
|
||||
|
||||
The circuit breaker design pattern is useful for protecting a system from failures or excessive load by providing a way to temporarily stop certain operations and allow the system to recover. It is often used in conjunction with other design patterns, such as retries and fallbacks, to provide a more robust and resilient cloud environment.
|
||||
The circuit breaker design pattern is a way to protect a system from failures or excessive load by temporarily stopping certain operations if the system is deemed to be in a failed or overloaded state. It is commonly used in cloud computing environments to prevent cascading failures and to improve the resilience and availability of a system. A circuit breaker consists of three states: closed, open, and half-open. In the closed state, the circuit breaker allows operations to proceed as normal. If the system encounters a failure or becomes overloaded, the circuit breaker moves to the open state, and all subsequent operations are immediately stopped. After a specified period of time, the circuit breaker moves to the half-open state, and a small number of operations are allowed to proceed. If these operations are successful, the circuit breaker moves back to the closed state; if they fail, the circuit breaker moves back to the open state.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Circuit Breaker - AWS Well-Architected Framework](https://docs.aws.amazon.com/wellarchitected/latest/reliability-pillar/rel_mitigate_interaction_failure_graceful_degradation.html)
|
||||
- [@article@Circuit Breaker - Complete Guide](https://mateus4k.github.io/posts/circuit-breakers/)
|
||||
- [@article@The Circuit Breaker Pattern](https://aerospike.com/blog/circuit-breaker-pattern/)
|
||||
- [@video@Back to Basics: Static Stability Using a Circuit Breaker Pattern](https://www.youtube.com/watch?v=gy1RITZ7N7s)
|
||||
|
||||
@@ -1,7 +1,8 @@
|
||||
# Client Side Caching
|
||||
|
||||
Client-side caching is the storage of network data to a local cache for future re-use. After an application fetches network data, it stores that resource in a local cache. Once a resource has been cached, the browser uses the cache on future requests for that resource to boost performance.
|
||||
Client-side caching is a technique where web browsers or applications store data locally on the user's device to improve performance and reduce server load. It involves saving copies of web pages, images, scripts, and other resources on the client's system for faster access on subsequent visits. Modern browsers implement various caching mechanisms, including HTTP caching (using headers like Cache-Control and ETag), service workers for offline functionality, and local storage APIs. Client-side caching significantly reduces network traffic and load times, enhancing user experience, especially on slower connections. However, it requires careful management to balance improved performance with the need for up-to-date content. Developers must implement appropriate cache invalidation strategies and consider cache-busting techniques for critical updates. Effective client-side caching is crucial for creating responsive, efficient web applications while minimizing server resource usage.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@video@Everything you need to know about HTTP Caching](https://www.youtube.com/watch?v=HiBDZgTNpXY)
|
||||
- [@article@Client-side Caching](https://redis.io/docs/latest/develop/use/client-side-caching/)
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
# Containerization vs. Virtualization
|
||||
|
||||
Containers and virtual machines are the two most popular approaches to setting up a software infrastructure for your organization.
|
||||
Containerization and virtualization are both technologies for isolating and running multiple applications on shared hardware, but they differ significantly in approach and resource usage. Virtualization creates separate virtual machines (VMs), each with its own operating system, running on a hypervisor. This provides strong isolation but consumes more resources. Containerization, exemplified by Docker, uses a shared operating system kernel to create isolated environments (containers) for applications. Containers are lighter, start faster, and use fewer resources than VMs. They're ideal for microservices architectures and rapid deployment. Virtualization offers better security isolation and is suitable for running different operating systems on the same hardware. Containerization provides greater efficiency and scalability, especially for cloud-native applications. The choice between them depends on specific use cases, security requirements, and infrastructure needs.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Containerization vs. Virtualization: Everything you need to know](https://middleware.io/blog/containerization-vs-virtualization/)
|
||||
- [@video@Containerization or Virtualization - The Differences ](https://www.youtube.com/watch?v=1WnDHitznGY)
|
||||
- [@video@Virtual Machine (VM) vs Docker](https://www.youtube.com/watch?v=a1M_thDTqmU)
|
||||
- [@feed@Explore top posts about Containers](https://app.daily.dev/tags/containers?ref=roadmapsh)
|
||||
|
||||
@@ -1,7 +1,8 @@
|
||||
# Cookie-Based Authentication
|
||||
|
||||
Cookies are pieces of data used to identify the user and their preferences. The browser returns the cookie to the server every time the page is requested. Specific cookies like HTTP cookies are used to perform cookie-based authentication to maintain the session for each user.
|
||||
Cookie-based authentication is a method of maintaining user sessions in web applications. When a user logs in, the server creates a session and sends a unique identifier (session ID) to the client as a cookie. This cookie is then sent with every subsequent request, allowing the server to identify and authenticate the user. The actual session data is typically stored on the server, with the cookie merely serving as a key to access this data. This approach is stateful on the server side and works well for traditional web applications. It's relatively simple to implement and is natively supported by browsers. However, cookie-based authentication faces challenges with cross-origin requests, can be vulnerable to CSRF attacks if not properly secured, and may not be ideal for modern single-page applications or mobile apps. Despite these limitations, it remains a common authentication method, especially for server-rendered web applications.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@How does cookie based authentication work?](https://stackoverflow.com/questions/17769011/how-does-cookie-based-authentication-work)
|
||||
- [@video@Session vs Token Authentication in 100 Seconds](https://www.youtube.com/watch?v=UBUNrFtufWo)
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
# Cors
|
||||
|
||||
Cross-Origin Resource Sharing (CORS) is an HTTP-header based mechanism that allows a server to indicate any origins (domain, scheme, or port) other than its own from which a browser should permit loading resources.
|
||||
Cross-Origin Resource Sharing (CORS) is a security mechanism implemented by web browsers to control access to resources (like APIs or fonts) on a web page from a different domain than the one serving the web page. It extends and adds flexibility to the Same-Origin Policy, allowing servers to specify who can access their resources. CORS works through a system of HTTP headers, where browsers send a preflight request to the server hosting the cross-origin resource, and the server responds with headers indicating whether the actual request is allowed. This mechanism helps prevent unauthorized access to sensitive data while enabling legitimate cross-origin requests. CORS is crucial for modern web applications that often integrate services and resources from multiple domains, balancing security needs with the functionality requirements of complex, distributed web systems.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Cross-Origin Resource Sharing (CORS)](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS)
|
||||
- [@article@Understanding CORS](https://rbika.com/blog/understanding-cors)
|
||||
- [@video@CORS in 100 Seconds](https://www.youtube.com/watch?v=4KHiSt0oLJ0)
|
||||
- [@video@CORS in 6 minutes](https://www.youtube.com/watch?v=PNtFSVU-YTI)
|
||||
- [@article@Understanding CORS](https://rbika.com/blog/understanding-cors)
|
||||
|
||||
@@ -4,8 +4,6 @@ Apache CouchDB is an open-source document-oriented NoSQL database. It uses JSON
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@CouchDB Website](https://couchdb.apache.org/)
|
||||
- [@article@CouchDB Documentation](https://docs.couchdb.org/)
|
||||
- [@article@The big NoSQL databases comparison](https://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis/)
|
||||
- [@article@pouchdb - a JavaScript database inspired by CouchDB](https://pouchdb.com/)
|
||||
- [@official@CouchDB Website](https://couchdb.apache.org/)
|
||||
- [@video@What is CouchDB?](https://www.youtube.com/watch?v=Mru4sHzIfSA)
|
||||
- [@feed@Explore top posts about CouchDB](https://app.daily.dev/tags/couchdb?ref=roadmapsh)
|
||||
|
||||
@@ -1,7 +1,8 @@
|
||||
# CQRS
|
||||
|
||||
CQRS, or command query responsibility segregation, defines an architectural pattern where the main focus is to separate the approach of reading and writing operations for a data store. CQRS can also be used along with Event Sourcing pattern in order to persist application state as an ordered of sequence events, making it possible to restore data to any point in time.
|
||||
CQRS (Command Query Responsibility Segregation) is an architectural pattern that separates read and write operations for a data store. In this pattern, "commands" handle data modification (create, update, delete), while "queries" handle data retrieval. The principle behind CQRS is that for many systems, especially complex ones, the requirements for reading data differ significantly from those for writing data. By separating these concerns, CQRS allows for independent scaling, optimization, and evolution of the read and write sides. This can lead to improved performance, scalability, and security. CQRS is often used in event-sourced systems and can be particularly beneficial in high-performance, complex domain applications. However, it also introduces additional complexity and should be applied judiciously based on the specific needs and constraints of the system.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@CQRS Pattern](https://docs.microsoft.com/en-us/azure/architecture/patterns/cqrs)
|
||||
- [@video@Learn CQRS Pattern in 5 minutes!](https://www.youtube.com/watch?v=eiut3FIY1Cg)
|
||||
|
||||
@@ -1,9 +1,10 @@
|
||||
# Content Security Policy
|
||||
|
||||
Content Security Policy is a computer security standard introduced to prevent cross-site scripting, clickjacking and other code injection attacks resulting from execution of malicious content in the trusted web page context.
|
||||
Content Security Policy (CSP) is a security standard implemented by web browsers to prevent cross-site scripting (XSS), clickjacking, and other code injection attacks. It works by allowing web developers to specify which sources of content are trusted and can be loaded on a web page. CSP is typically implemented through HTTP headers or meta tags, defining rules for various types of resources like scripts, stylesheets, images, and fonts. By restricting the origins from which content can be loaded, CSP significantly reduces the risk of malicious code execution. It also provides features like reporting violations to help developers identify and fix potential security issues. While powerful, implementing CSP requires careful configuration to balance security with functionality, especially for sites using third-party resources or inline scripts.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@MDN — Content Security Policy (CSP)](https://developer.mozilla.org/en-US/docs/Web/HTTP/CSP)
|
||||
- [@article@Google Devs — Content Security Policy (CSP)](https://developers.google.com/web/fundamentals/security/csp)
|
||||
- [@video@Content Security Policy Explained](https://www.youtube.com/watch?v=-LjPRzFR5f0)
|
||||
- [@feed@Explore top posts about Security](https://app.daily.dev/tags/security?ref=roadmapsh)
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
# Data Replication
|
||||
|
||||
Data replication is the process by which data residing on a physical/virtual server(s) or cloud instance (primary instance) is continuously replicated or copied to a secondary server(s) or cloud instance (standby instance). Organizations replicate data to support high availability, backup, and/or disaster recovery.
|
||||
Data replication is the process of creating and maintaining multiple copies of the same data across different locations or nodes in a distributed system. It enhances data availability, reliability, and performance by ensuring that data remains accessible even if one or more nodes fail. Replication can be synchronous (changes are applied to all copies simultaneously) or asynchronous (changes are propagated after being applied to the primary copy). It's widely used in database systems, content delivery networks, and distributed file systems. Replication strategies include master-slave, multi-master, and peer-to-peer models. While improving fault tolerance and read performance, replication introduces challenges in maintaining data consistency across copies and managing potential conflicts. Effective replication strategies must balance consistency, availability, and partition tolerance, often in line with the principles of the CAP theorem.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@What is data replication?](https://www.ibm.com/topics/data-replication)
|
||||
- [@video@What is Data Replication?](https://youtu.be/fUrKt-AQYtE)
|
||||
- [@video@What is Data Replication?](https://www.youtube.com/watch?v=iO8a1nMbL1o)
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
# Database Indexes
|
||||
|
||||
An index is a data structure that you build and assign on top of an existing table that basically looks through your table and tries to analyze and summarize so that it can create shortcuts.
|
||||
Database indexes are data structures that improve the speed of data retrieval operations in a database management system. They work similarly to book indexes, providing a quick way to look up information based on specific columns or sets of columns. Indexes create a separate structure that holds a reference to the actual data, allowing the database engine to find information without scanning the entire table. While indexes significantly enhance query performance, especially for large datasets, they come with trade-offs. They increase storage space requirements and can slow down write operations as the index must be updated with each data modification. Common types include B-tree indexes for general purpose use, bitmap indexes for low-cardinality data, and hash indexes for equality comparisons. Proper index design is crucial for optimizing database performance, balancing faster reads against slower writes and increased storage needs.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Database index - Wikipedia](https://en.wikipedia.org/wiki/Database_index)
|
||||
- [@article@What is a Database Index?](https://www.codecademy.com/article/sql-indexes)
|
||||
- [@video@Database Indexing Explained](https://www.youtube.com/watch?v=-qNSXK7s7_w)
|
||||
- [@feed@Explore top posts about Database](https://app.daily.dev/tags/database?ref=roadmapsh)
|
||||
|
||||
@@ -1,37 +1,16 @@
|
||||
# Design and Development Principles
|
||||
|
||||
In this section, we'll discuss some essential design and development principles to follow while building the backend of any application. These principles will ensure that the backend is efficient, scalable, and maintainable.
|
||||
Design and Development Principles are fundamental guidelines that inform the creation of software systems. Key principles include:
|
||||
|
||||
## 1. Separation of Concerns (SoC)
|
||||
1. SOLID (Single Responsibility, Open-Closed, Liskov Substitution, Interface Segregation, Dependency Inversion)
|
||||
2. DRY (Don't Repeat Yourself)
|
||||
3. KISS (Keep It Simple, Stupid)
|
||||
4. YAGNI (You Aren't Gonna Need It)
|
||||
5. Separation of Concerns
|
||||
6. Modularity
|
||||
7. Encapsulation
|
||||
8. Composition over Inheritance
|
||||
9. Loose Coupling and High Cohesion
|
||||
10. Principle of Least Astonishment
|
||||
|
||||
Separation of Concerns is a fundamental principle that states that different functionalities of a system should be as independent as possible. This approach improves maintainability and scalability by allowing developers to work on separate components without affecting each other. Divide your backend into clear modules and layers, such as data storage, business logic, and network communication.
|
||||
|
||||
## 2. Reusability
|
||||
|
||||
Reusability is the ability to use components, functions, or modules in multiple places without duplicating code. While designing the backend, look for opportunities where you can reuse existing code. Use techniques like creating utility functions, abstract classes, and interfaces to promote reusability and reduce redundancy.
|
||||
|
||||
## 3. Keep It Simple and Stupid (KISS)
|
||||
|
||||
KISS principle states that the simpler the system, the easier it is to understand, maintain, and extend. When designing the backend, try to keep the architecture and code as simple as possible. Use clear naming conventions and modular structures, and avoid over-engineering and unnecessary complexity.
|
||||
|
||||
## 4. Don't Repeat Yourself (DRY)
|
||||
|
||||
Do not duplicate code or functionality across your backend. Duplication can lead to inconsistency and maintainability issues. Instead, focus on creating reusable components, functions or modules, which can be shared across different parts of the backend.
|
||||
|
||||
## 5. Scalability
|
||||
|
||||
A scalable system is one that can efficiently handle an increasing number of users, requests, or data. Design the backend with scalability in mind, considering factors such as data storage, caching, load balancing, and horizontal scaling (adding more instances of the backend server).
|
||||
|
||||
## 6. Security
|
||||
|
||||
Security is a major concern when developing any application. Always follow best practices to prevent security flaws, such as protecting sensitive data, using secure communication protocols (e.g., HTTPS), implementing authentication and authorization mechanisms, and sanitizing user inputs.
|
||||
|
||||
## 7. Testing
|
||||
|
||||
Testing is crucial for ensuring the reliability and stability of the backend. Implement a comprehensive testing strategy, including unit, integration, and performance tests. Use automated testing tools and set up continuous integration (CI) and continuous deployment (CD) pipelines to streamline the testing and deployment process.
|
||||
|
||||
## 8. Documentation
|
||||
|
||||
Proper documentation helps developers understand and maintain the backend codebase. Write clear and concise documentation for your code, explaining the purpose, functionality, and how to use it. Additionally, use comments and appropriate naming conventions to make the code itself more readable and self-explanatory.
|
||||
|
||||
By following these design and development principles, you'll be well on your way to creating an efficient, secure, and maintainable backend for your applications.
|
||||
These principles aim to create more maintainable, scalable, and robust software. They encourage clean code, promote reusability, reduce complexity, and enhance flexibility. While not rigid rules, these principles guide developers in making design decisions that lead to better software architecture and easier long-term maintenance. Applying these principles helps in creating systems that are easier to understand, modify, and extend over time.
|
||||
@@ -1,13 +1,10 @@
|
||||
# DNS
|
||||
|
||||
The Domain Name System (DNS) is the phonebook of the Internet. Humans access information online through domain names, like nytimes.com or espn.com. Web browsers interact through Internet Protocol (IP) addresses. DNS translates domain names to IP addresses so browsers can load Internet resources.
|
||||
DNS (Domain Name System) is a hierarchical, decentralized naming system for computers, services, or other resources connected to the Internet or a private network. It translates human-readable domain names (like www.example.com) into IP addresses (like 192.0.2.1) that computers use to identify each other. DNS servers distributed worldwide work together to resolve these queries, forming a global directory service. The system uses a tree-like structure with root servers at the top, followed by top-level domain servers (.com, .org, etc.), authoritative name servers for specific domains, and local DNS servers. DNS is crucial for the functioning of the Internet, enabling users to access websites and services using memorable names instead of numerical IP addresses. It also supports email routing, service discovery, and other network protocols.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@What is DNS?](https://www.cloudflare.com/en-gb/learning/dns/what-is-dns/)
|
||||
- [@article@How DNS works (comic)](https://howdns.works/)
|
||||
- [@article@Understanding Domain names](https://developer.mozilla.org/en-US/docs/Glossary/DNS/)
|
||||
- [@video@DNS and How does it Work?](https://www.youtube.com/watch?v=Wj0od2ag5sk)
|
||||
- [@video@DNS Records](https://www.youtube.com/watch?v=7lxgpKh_fRY)
|
||||
- [@video@Complete DNS mini-series](https://www.youtube.com/watch?v=zEmUuNFBgN8\&list=PLTk5ZYSbd9MhMmOiPhfRJNW7bhxHo4q-K)
|
||||
- [@feed@Explore top posts about DNS](https://app.daily.dev/tags/dns?ref=roadmapsh)
|
||||
|
||||
@@ -1,17 +1,9 @@
|
||||
# Domain-Driven Design
|
||||
|
||||
Domain-driven design (DDD) is a software design approach focusing on modeling software to match a domain according to input from that domain's experts.
|
||||
|
||||
In terms of object-oriented programming, it means that the structure and language of software code (class names, class methods, class variables) should match the business domain. For example, if a software processes loan applications, it might have classes like LoanApplication and Customer, and methods such as AcceptOffer and Withdraw.
|
||||
|
||||
DDD connects the implementation to an evolving model and it is predicated on the following goals:
|
||||
|
||||
- Placing the project's primary focus on the core domain and domain logic;
|
||||
- Basing complex designs on a model of the domain;
|
||||
- Initiating a creative collaboration between technical and domain experts to iteratively refine a conceptual model that addresses particular domain problems.
|
||||
Domain-Driven Design (DDD) is a software development approach that focuses on creating a deep understanding of the business domain and using this knowledge to inform the design of software systems. It emphasizes close collaboration between technical and domain experts to develop a shared language (ubiquitous language) and model that accurately represents the core concepts and processes of the business. DDD promotes organizing code around business concepts (bounded contexts), using rich domain models to encapsulate business logic, and separating the domain logic from infrastructure concerns. Key patterns in DDD include entities, value objects, aggregates, repositories, and domain services. This approach aims to create more maintainable and flexible software systems that closely align with business needs and can evolve with changing requirements. DDD is particularly valuable for complex domains where traditional CRUD-based architectures may fall short in capturing the nuances and rules of the business.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Domain-Driven Design](https://redis.com/glossary/domain-driven-design-ddd/)
|
||||
- [@article@Domain-Driven Design: Tackling Complexity in the Heart of Software](https://www.amazon.com/Domain-Driven-Design-Tackling-Complexity-Software/dp/0321125215)
|
||||
- [@video@Domain Driven Design: What You Need To Know](https://www.youtube.com/watch?v=4rhzdZIDX_k)
|
||||
- [@feed@Explore top posts about Domain-Driven Design](https://app.daily.dev/tags/domain-driven-design?ref=roadmapsh)
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
# DynamoDB
|
||||
|
||||
DynamoDB is a fully managed NoSQL database service provided by AWS, designed for high-performance applications that require low-latency data access at any scale.
|
||||
Amazon DynamoDB is a fully managed, serverless NoSQL database service provided by Amazon Web Services (AWS). It offers high-performance, scalable, and flexible data storage for applications of any scale. DynamoDB supports both key-value and document data models, providing fast and predictable performance with seamless scalability. It features automatic scaling, built-in security, backup and restore options, and global tables for multi-region deployment. DynamoDB excels in handling high-traffic web applications, gaming backends, mobile apps, and IoT solutions. It offers consistent single-digit millisecond latency at any scale and supports both strongly consistent and eventually consistent read models. With its integration into the AWS ecosystem, on-demand capacity mode, and support for transactions, DynamoDB is widely used for building highly responsive and scalable applications, particularly those with unpredictable workloads or requiring low-latency data access.
|
||||
|
||||
It supports key-value and document data models, allowing developers to store and retrieve any amount of data with predictable performance.
|
||||
Learn more from the following resources:
|
||||
|
||||
DynamoDB is known for its seamless scalability, automatic data replication across multiple AWS regions, and built-in security features, making it ideal for use cases like real-time analytics, mobile apps, gaming, IoT, and more.
|
||||
|
||||
Key features include flexible schema design, powerful query capabilities, and integration with other AWS services.
|
||||
- [@official@AWS DynamoDB Website](https://aws.amazon.com/dynamodb/)
|
||||
- [@video@AWS DynamoDB Tutorial For Beginners](https://www.youtube.com/watch?v=2k2GINpO308)
|
||||
- [@feed@daily.dev AWS DynamoDB Feed](https://app.daily.dev/tags/aws-dynamodb)
|
||||
@@ -6,4 +6,5 @@ Visit the following resources to learn more:
|
||||
|
||||
- [@official@Elasticsearch Website](https://www.elastic.co/elasticsearch/)
|
||||
- [@official@Elasticsearch Documentation](https://www.elastic.co/guide/index.html)
|
||||
- [@video@What is Elasticsearch](https://www.youtube.com/watch?v=ZP0NmfyfsoM)
|
||||
- [@feed@Explore top posts about ELK](https://app.daily.dev/tags/elk?ref=roadmapsh)
|
||||
|
||||
@@ -1,12 +1,9 @@
|
||||
# Event Sourcing
|
||||
|
||||
Event sourcing is a design pattern in which the state of a system is represented as a sequence of events that have occurred over time. In an event-sourced system, changes to the state of the system are recorded as events and stored in an event store. The current state of the system is derived by replaying the events from the event store.
|
||||
|
||||
One of the main benefits of event sourcing is that it provides a clear and auditable history of all the changes that have occurred in the system. This can be useful for debugging and for tracking the evolution of the system over time.
|
||||
|
||||
Event sourcing is often used in conjunction with other patterns, such as Command Query Responsibility Segregation (CQRS) and domain-driven design, to build scalable and responsive systems with complex business logic. It is also useful for building systems that need to support undo/redo functionality or that need to integrate with external systems.
|
||||
Event sourcing is a design pattern in which the state of a system is represented as a sequence of events that have occurred over time. In an event-sourced system, changes to the state of the system are recorded as events and stored in an event store. The current state of the system is derived by replaying the events from the event store. One of the main benefits of event sourcing is that it provides a clear and auditable history of all the changes that have occurred in the system. This can be useful for debugging and for tracking the evolution of the system over time.Event sourcing is often used in conjunction with other patterns, such as Command Query Responsibility Segregation (CQRS) and domain-driven design, to build scalable and responsive systems with complex business logic. It is also useful for building systems that need to support undo/redo functionality or that need to integrate with external systems.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Event Sourcing - Martin Fowler](https://martinfowler.com/eaaDev/EventSourcing.html)
|
||||
- [@video@Event Sourcing 101](https://www.youtube.com/watch?v=lg6aF5PP4Tc)
|
||||
- [@feed@Explore top posts about Architecture](https://app.daily.dev/tags/architecture?ref=roadmapsh)
|
||||
|
||||
@@ -1,14 +1,4 @@
|
||||
# Failure Modes
|
||||
|
||||
There are several different failure modes that can occur in a database, including:
|
||||
Database failure modes refer to the various ways in which a database system can malfunction or cease to operate correctly. These include hardware failures (like disk crashes or network outages), software bugs, data corruption, performance degradation due to overload, and inconsistencies in distributed systems. Common failure modes involve data loss, system unavailability, replication lag in distributed databases, and deadlocks. To mitigate these, databases employ strategies such as redundancy, regular backups, transaction logging, and failover mechanisms. Understanding potential failure modes is crucial for designing robust database systems with high availability and data integrity. It informs the implementation of fault tolerance measures, recovery procedures, and monitoring systems to ensure database reliability and minimize downtime in critical applications.
|
||||
|
||||
- Read contention: This occurs when multiple clients or processes are trying to read data from the same location in the database at the same time, which can lead to delays or errors.
|
||||
- Write contention: This occurs when multiple clients or processes are trying to write data to the same location in the database at the same time, which can lead to delays or errors.
|
||||
- Thundering herd: This occurs when a large number of clients or processes try to access the same resource simultaneously, which can lead to resource exhaustion and reduced performance.
|
||||
- Cascade: This occurs when a failure in one part of the database system causes a chain reaction that leads to failures in other parts of the system.
|
||||
- Deadlock: This occurs when two or more transactions are waiting for each other to release a lock on a resource, leading to a standstill.
|
||||
- Corruption: This occurs when data in the database becomes corrupted, which can lead to errors or unexpected results when reading or writing to the database.
|
||||
- Hardware failure: This occurs when hardware components, such as disk drives or memory, fail, which can lead to data loss or corruption.
|
||||
- Software failure: This occurs when software components, such as the database management system or application, fail, which can lead to errors or unexpected results.
|
||||
- Network failure: This occurs when the network connection between the database and the client is lost, which can lead to errors or timeouts when trying to access the database.
|
||||
- Denial of service (DoS) attack: This occurs when a malicious actor attempts to overwhelm the database with requests, leading to resource exhaustion and reduced performance.
|
||||
|
||||
@@ -1,6 +1,9 @@
|
||||
# Realtime databases
|
||||
# Firebase
|
||||
|
||||
A real-time database is broadly defined as a data store designed to collect, process, and/or enrich an incoming series of data points (i.e., a data stream) in real time, typically immediately after the data is created.
|
||||
Firebase is a comprehensive mobile and web application development platform owned by Google. It provides a suite of cloud-based services that simplify app development, hosting, and scaling. Key features include real-time database, cloud storage, authentication, hosting, cloud functions, and analytics. Firebase offers real-time synchronization, allowing data to be updated across clients instantly. Its authentication service supports multiple providers, including email/password, social media logins, and phone authentication. The platform's serverless architecture enables developers to focus on front-end development without managing backend infrastructure. Firebase also provides tools for app testing, crash reporting, and performance monitoring. While it excels in rapid prototyping and building real-time applications, its proprietary nature and potential for vendor lock-in are considerations for large-scale or complex applications. Firebase's ease of use and integration with Google Cloud Platform make it popular for startups and projects requiring quick deployment.
|
||||
|
||||
[Firebase](https://firebase.google.com/)
|
||||
[RethinkDB](https://rethinkdb.com/)
|
||||
Learn more from the following resources:
|
||||
|
||||
- [@official@Firebase Website](https://firebase.google.com/)
|
||||
- [@video@Firebase in 100 seconds](https://www.youtube.com/watch?v=vAoB4VbhRzM)
|
||||
- [@course@The ultimate guide to Firebase](https://fireship.io/lessons/the-ultimate-beginners-guide-to-firebase/)
|
||||
@@ -1,10 +1,9 @@
|
||||
# Functional Testing
|
||||
|
||||
Functional testing is where software is tested to ensure functional requirements are met. Usually, it is a form of black box testing in which the tester has no understanding of the source code; testing is performed by providing input and comparing expected/actual output.
|
||||
It contrasts with non-functional testing, which includes performance, load, scalability, and penetration testing.
|
||||
Functional testing is where software is tested to ensure functional requirements are met. Usually, it is a form of black box testing in which the tester has no understanding of the source code; testing is performed by providing input and comparing expected/actual output. It contrasts with non-functional testing, which includes performance, load, scalability, and penetration testing.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@What is Functional Testing?](https://www.guru99.com/functional-testing.html)
|
||||
- [@video@Functional Testing vs Non-Functional Testing](https://youtu.be/j_79AXkG4PY)
|
||||
- [@video@Functional Testing vs Non-Functional Testing](https://www.youtube.com/watch?v=NgQT7miTP9M)
|
||||
- [@feed@Explore top posts about Testing](https://app.daily.dev/tags/testing?ref=roadmapsh)
|
||||
|
||||
@@ -1,13 +1,12 @@
|
||||
# Git
|
||||
|
||||
[Git](https://git-scm.com/) is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
|
||||
Git is a distributed version control system designed to handle projects of any size with speed and efficiency. Created by Linus Torvalds in 2005, it tracks changes in source code during software development, allowing multiple developers to work together on non-linear development. Git maintains a complete history of all changes, enabling easy rollbacks and comparisons between versions. Its distributed nature means each developer has a full copy of the repository, allowing for offline work and backup. Git's key features include branching and merging capabilities, staging area for commits, and support for collaborative workflows like pull requests. Its speed, flexibility, and robust branching and merging capabilities have made it the most widely used version control system in software development, particularly for open-source projects and team collaborations.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Introduction to Git](https://learn.microsoft.com/en-us/training/modules/intro-to-git/)
|
||||
- [@roadmap@Learn Git & GitHub](/git-github)
|
||||
- [@video@Git & GitHub Crash Course For Beginners](https://www.youtube.com/watch?v=SWYqp7iY_Tc)
|
||||
- [@article@Learn Git with Tutorials, News and Tips - Atlassian](https://www.atlassian.com/git)
|
||||
- [@article@Git Cheat Sheet](https://cs.fyi/guide/git-cheatsheet)
|
||||
- [@article@Learn Git Branching](https://learngitbranching.js.org/)
|
||||
- [@article@Git Tutorial](https://www.w3schools.com/git/)
|
||||
- [@feed@Explore top posts about Git](https://app.daily.dev/tags/git?ref=roadmapsh)
|
||||
|
||||
@@ -1,15 +1,12 @@
|
||||
# GitHub
|
||||
|
||||
GitHub is a provider of Internet hosting for software development and version control using Git. It offers the distributed version control and source code management functionality of Git, plus its own features.
|
||||
GitHub is a web-based platform for version control and collaboration using Git. Owned by Microsoft, it provides hosting for software development and offers features beyond basic Git functionality. GitHub includes tools for project management, code review, and social coding. Key features include repositories for storing code, pull requests for proposing and reviewing changes, issues for tracking bugs and tasks, and actions for automating workflows. It supports both public and private repositories, making it popular for open-source projects and private development. GitHub's collaborative features, like forking repositories and inline code comments, facilitate team development and community contributions. With its extensive integrations and large user base, GitHub has become a central hub for developers, serving as a portfolio, collaboration platform, and deployment tool for software projects of all sizes.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@opensource@GitHub Website](https://github.com)
|
||||
- [@article@GitHub Documentation](https://docs.github.com/en/get-started/quickstart)
|
||||
- [@article@How to Use Git in a Professional Dev Team](https://ooloo.io/project/github-flow)
|
||||
- [@roadmap@Learn Git & GitHub](/git-github)
|
||||
- [@official@GitHub Website](https://github.com)
|
||||
- [@video@What is GitHub?](https://www.youtube.com/watch?v=w3jLJU7DT5E)
|
||||
- [@video@Git vs. GitHub: Whats the difference?](https://www.youtube.com/watch?v=wpISo9TNjfU)
|
||||
- [@video@Git and GitHub for Beginners](https://www.youtube.com/watch?v=RGOj5yH7evk)
|
||||
- [@video@Git and GitHub - CS50 Beyond 2019](https://www.youtube.com/watch?v=eulnSXkhE7I)
|
||||
- [@article@Learn Git Branching](https://learngitbranching.js.org/?locale=en_us)
|
||||
- [@feed@Explore top posts about GitHub](https://app.daily.dev/tags/github?ref=roadmapsh)
|
||||
|
||||
@@ -1,9 +1,10 @@
|
||||
# GitLab
|
||||
|
||||
GitLab is a provider of internet hosting for software development and version control using Git. It offers the distributed version control and source code management functionality of Git, plus its own features.
|
||||
GitLab is a web-based DevOps platform that provides a complete solution for the software development lifecycle. It offers source code management, continuous integration/continuous deployment (CI/CD), issue tracking, and more, all integrated into a single application. GitLab supports Git repositories and includes features like merge requests (similar to GitHub's pull requests), wiki pages, and issue boards. It emphasizes DevOps practices, providing built-in CI/CD pipelines, container registry, and Kubernetes integration. GitLab offers both cloud-hosted and self-hosted options, giving organizations flexibility in deployment. Its all-in-one approach differentiates it from competitors, as it includes features that might require multiple tools in other ecosystems. GitLab's focus on the entire DevOps lifecycle, from planning to monitoring, makes it popular among enterprises and teams seeking a unified platform for their development workflows.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@opensource@GitLab Website](https://gitlab.com/)
|
||||
- [@article@GitLab Documentation](https://docs.gitlab.com/)
|
||||
- [@video@What is Gitlab and Why Use It?](https://www.youtube.com/watch?v=bnF7f1zGpo4)
|
||||
- [@feed@Explore top posts about GitLab](https://app.daily.dev/tags/gitlab?ref=roadmapsh)
|
||||
|
||||
@@ -1,15 +1,12 @@
|
||||
# Go
|
||||
|
||||
Go is an open source programming language supported by Google. Go can be used to write cloud services, CLI tools, used for API development, and much more.
|
||||
Go, also known as Golang, is a statically typed, compiled programming language designed by Google. It combines the efficiency of compiled languages with the ease of use of dynamically typed interpreted languages. Go features built-in concurrency support through goroutines and channels, making it well-suited for networked and multicore systems. It has a simple and clean syntax, fast compilation times, and efficient garbage collection. Go's standard library is comprehensive, reducing the need for external dependencies. The language emphasizes simplicity and readability, with features like implicit interfaces and a lack of inheritance. Go is particularly popular for building microservices, web servers, and distributed systems. Its performance, simplicity, and robust tooling make it a favored choice for cloud-native development, DevOps tools, and large-scale backend systems.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@roadmap@Visit Dedicated Go Roadmap](/golang)
|
||||
- [@official@A Tour of Go – Go Basics](https://go.dev/tour/welcome/1)
|
||||
- [@official@Go Reference Documentation](https://go.dev/doc/)
|
||||
- [@article@Go by Example - annotated example programs](https://gobyexample.com/)
|
||||
- [@article@W3Schools Go Tutorial ](https://www.w3schools.com/go/)
|
||||
- [@article@Making a RESTful JSON API in Go](https://thenewstack.io/make-a-restful-json-api-go/)
|
||||
- [@article@Go, the Programming Language of the Cloud](https://thenewstack.io/go-the-programming-language-of-the-cloud/)
|
||||
- [@video@Go Class by Matt](https://www.youtube.com/playlist?list=PLoILbKo9rG3skRCj37Kn5Zj803hhiuRK6)
|
||||
- [@video@Go Programming – Golang Course with Bonus Projects](https://www.youtube.com/watch?v=un6ZyFkqFKo)
|
||||
- [@feed@Explore top posts about Golang](https://app.daily.dev/tags/golang?ref=roadmapsh)
|
||||
|
||||
@@ -1,12 +1,6 @@
|
||||
# GoF Design Patterns
|
||||
|
||||
The Gang of Four (GoF) design patterns are a set of design patterns for object-oriented software development that were first described in the book "Design Patterns: Elements of Reusable Object-Oriented Software" by Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides (also known as the Gang of Four).
|
||||
|
||||
The GoF design patterns are divided into three categories: Creational, Structural and Behavioral.
|
||||
|
||||
- Creational Patterns
|
||||
- Structural Patterns
|
||||
- Behavioral Patterns
|
||||
The Gang of Four (GoF) Design Patterns are a collection of 23 foundational software design patterns that provide solutions to common object-oriented design problems. These patterns are grouped into three categories: *Creational* (focused on object creation like Singleton and Factory), *Structural* (focused on class and object composition like Adapter and Composite), and *Behavioral* (focused on communication between objects like Observer and Strategy). Each pattern offers a proven template for addressing specific design challenges, promoting code reusability, flexibility, and maintainability across software systems.
|
||||
|
||||
Learn more from the following links:
|
||||
|
||||
|
||||
@@ -1,11 +1,9 @@
|
||||
# Graceful Degradation
|
||||
|
||||
Graceful degradation is a design principle that states that a system should be designed to continue functioning, even if some of its components or features are not available. In the context of web development, graceful degradation refers to the ability of a web page or application to continue functioning, even if the user's browser or device does not support certain features or technologies.
|
||||
|
||||
Graceful degradation is often used as an alternative to progressive enhancement, a design principle that states that a system should be designed to take advantage of advanced features and technologies if they are available.
|
||||
Graceful degradation is a design principle that states that a system should be designed to continue functioning, even if some of its components or features are not available. In the context of web development, graceful degradation refers to the ability of a web page or application to continue functioning, even if the user's browser or device does not support certain features or technologies. Graceful degradation is often used as an alternative to progressive enhancement, a design principle that states that a system should be designed to take advantage of advanced features and technologies if they are available.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@What is Graceful Degradation & Why Does it Matter?](https://blog.hubspot.com/website/graceful-degradation)
|
||||
- [@article@Four Considerations When Designing Systems For Graceful Degradation](https://newrelic.com/blog/best-practices/design-software-for-graceful-degradation)
|
||||
- [@article@The Art of Graceful Degradation](https://farfetchtechblog.com/en/blog/post/the-art-of-failure-ii-graceful-degradation/)
|
||||
- [@video@Graceful Degradation - Georgia Tech](https://www.youtube.com/watch?v=Tk7e0LMsAlI)
|
||||
|
||||
@@ -1,15 +1,10 @@
|
||||
# GraphQL
|
||||
|
||||
GraphQL is a query language and runtime system for APIs (application programming interfaces). It is designed to provide a flexible and efficient way for clients to request data from servers, and it is often used as an alternative to REST (representational state transfer) APIs.
|
||||
|
||||
One of the main features of GraphQL is its ability to specify exactly the data that is needed, rather than receiving a fixed set of data from an endpoint. This allows clients to request only the data that they need, and it reduces the amount of data that needs to be transferred over the network.
|
||||
|
||||
GraphQL also provides a way to define the structure of the data that is returned from the server, allowing clients to request data in a predictable and flexible way. This makes it easier to build and maintain client applications that depend on data from the server.
|
||||
|
||||
GraphQL is widely used in modern web and mobile applications, and it is supported by a large and active developer community.
|
||||
GraphQL is a query language for APIs and a runtime for executing those queries, developed by Facebook. Unlike REST, where fixed endpoints return predefined data, GraphQL allows clients to request exactly the data they need, making API interactions more flexible and efficient. It uses a single endpoint and relies on a schema that defines the types and structure of the available data. This approach reduces over-fetching and under-fetching of data, making it ideal for complex applications with diverse data needs across multiple platforms (e.g., web, mobile).
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@roadmap@GraphQL Roadmap](/graphql)
|
||||
- [@official@GraphQL Official Website](https://graphql.org/)
|
||||
- [@video@Tutorial - GraphQL Explained in 100 Seconds](https://www.youtube.com/watch?v=eIQh02xuVw4)
|
||||
- [@feed@Explore top posts about GraphQL](https://app.daily.dev/tags/graphql?ref=roadmapsh)
|
||||
|
||||
@@ -1,13 +1,10 @@
|
||||
# gRPC
|
||||
|
||||
gRPC is a high-performance, open source universal RPC framework
|
||||
|
||||
RPC stands for Remote Procedure Call, there's an ongoing debate on what the g stands for. RPC is a protocol that allows a program to execute a procedure of another program located on another computer. The great advantage is that the developer doesn’t need to code the details of the remote interaction. The remote procedure is called like any other function. But the client and the server can be coded in different languages.
|
||||
gRPC is a high-performance, open source universal RPC framework, RPC stands for Remote Procedure Call, there's an ongoing debate on what the g stands for. RPC is a protocol that allows a program to execute a procedure of another program located on another computer. The great advantage is that the developer doesn’t need to code the details of the remote interaction. The remote procedure is called like any other function. But the client and the server can be coded in different languages.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@official@gRPC Website](https://grpc.io/)
|
||||
- [@official@gRPC Docs](https://grpc.io/docs/)
|
||||
- [@article@What Is GRPC?](https://www.wallarm.com/what/the-concept-of-grpc)
|
||||
- [@video@What Is GRPC?](https://www.youtube.com/watch?v=hVrwuMnCtok)
|
||||
- [@feed@Explore top posts about gRPC](https://app.daily.dev/tags/grpc?ref=roadmapsh)
|
||||
|
||||
@@ -1,5 +1,8 @@
|
||||
# Hateoas
|
||||
|
||||
HATEOAS is an acronym for <b>H</b>ypermedia <b>A</b>s <b>T</b>he <b>E</b>ngine <b>O</b>f <b>A</b>pplication <b>S</b>tate, it's the concept that when sending information over a RESTful API the document received should contain everything the client needs in order to parse and use the data i.e they don't have to contact any other endpoint not explicitly mentioned within the Document.
|
||||
HATEOAS (Hypermedia As The Engine Of Application State) is a constraint of RESTful architecture that allows clients to navigate an API dynamically through hypermedia links provided in responses. Instead of hard-coding URLs or endpoints, the client discovers available actions through these links, much like a web browser following links on a webpage. This enables greater flexibility and decouples clients from server-side changes, making the system more adaptable and scalable without breaking existing clients. It's a key element of REST's principle of statelessness and self-descriptive messages.
|
||||
|
||||
Learn more from the following resources:
|
||||
|
||||
- [@article@What is HATEOAS and why is it important for my REST API?](https://restcookbook.com/Basics/hateoas/)
|
||||
- [@video@What happened to HATEOAS](https://www.youtube.com/watch?v=HNTSrytKCoQ)
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Internet
|
||||
|
||||
The Internet is a global network of computers connected to each other which communicate through a standardized set of protocols.
|
||||
The internet is a global network of interconnected computers that communicate using standardized protocols, primarily TCP/IP. When you request a webpage, your device sends a data packet through your internet service provider (ISP) to a DNS server, which translates the website's domain name into an IP address. The packet is then routed across various networks (using routers and switches) to the destination server, which processes the request and sends back the response. This back-and-forth exchange enables the transfer of data like web pages, emails, and files, making the internet a dynamic, decentralized system for global communication.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
@@ -9,5 +9,4 @@ Visit the following resources to learn more:
|
||||
- [@article@How Does the Internet Work?](http://web.stanford.edu/class/msande91si/www-spr04/readings/week1/InternetWhitepaper.htm)
|
||||
- [@roadmap.sh@Introduction to Internet](/guides/what-is-internet)
|
||||
- [@video@How does the Internet work?](https://www.youtube.com/watch?v=x3c1ih2NJEg)
|
||||
- [@video@How the Internet Works in 5 Minutes](https://www.youtube.com/watch?v=7_LPdttKXPc)
|
||||
- [@video@How does the internet work? (Full Course)](https://www.youtube.com/watch?v=zN8YNNHcaZc)
|
||||
|
||||
@@ -1,17 +1,11 @@
|
||||
# HTTPS
|
||||
|
||||
HTTPS is a secure way to send data between a web server and a browser.
|
||||
|
||||
A communication through HTTPS starts with the handshake phase during which the server and the client agree on how to encrypt the communication, in particular they choose an encryption algorithm and a secret key. After the handshake all the communication between the server and the client will be encrypted using the agreed upon algorithm and key.
|
||||
|
||||
The handshake phase uses a particular kind of cryptography, called asymmetric cryptography, to communicate securely even though client and server have not yet agreed on a secret key. After the handshake phase the HTTPS communication is encrypted with symmetric cryptography, which is much more efficient but requires client and server to both have knowledge of the secret key.
|
||||
HTTPS (Hypertext Transfer Protocol Secure) is an extension of HTTP designed to secure data transmission between a client (e.g., browser) and a server. It uses encryption through SSL/TLS protocols to ensure data confidentiality, integrity, and authenticity. This prevents sensitive information, like login credentials or payment details, from being intercepted or tampered with by attackers. HTTPS is essential for securing web applications and has become a standard for most websites, especially those handling user data, as it helps protect against man-in-the-middle attacks and eavesdropping.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@What is HTTPS?](https://www.cloudflare.com/en-gb/learning/ssl/what-is-https/)
|
||||
- [@article@Why HTTPS Matters](https://developers.google.com/web/fundamentals/security/encrypt-in-transit/why-https)
|
||||
- [@article@Enabling HTTPS on Your Servers](https://web.dev/articles/enable-https)
|
||||
- [@article@How HTTPS works (comic)](https://howhttps.works/)
|
||||
- [@video@SSL, TLS, HTTP, HTTPS Explained](https://www.youtube.com/watch?v=hExRDVZHhig)
|
||||
- [@video@HTTPS — Stories from the field](https://www.youtube.com/watch?v=GoXgl9r0Kjk)
|
||||
- [@article@HTTPS explained with carrier pigeons](https://baida.dev/articles/https-explained-with-carrier-pigeons)
|
||||
- [@video@HTTP vs HTTPS](https://www.youtube.com/watch?v=nOmT_5hqgPk)
|
||||
|
||||
@@ -1,11 +1,10 @@
|
||||
# Timeseries databases
|
||||
# InfluxDB
|
||||
|
||||
## InfluxDB
|
||||
|
||||
InfluxDB was built from the ground up to be a purpose-built time series database; i.e., it was not repurposed to be time series. Time was built-in from the beginning. InfluxDB is part of a comprehensive platform that supports the collection, storage, monitoring, visualization and alerting of time series data. It’s much more than just a time series database.
|
||||
InfluxDB is a high-performance, open-source time-series database designed for handling large volumes of timestamped data, such as metrics, events, and real-time analytics. It is optimized for use cases like monitoring, IoT, and application performance management, where data arrives in continuous streams. InfluxDB supports SQL-like queries through its query language (Flux), and it can handle high write and query loads efficiently. Key features include support for retention policies, downsampling, and automatic data compaction, making it ideal for environments that require fast and scalable time-series data storage and retrieval.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@InfluxDB Website](https://www.influxdata.com/)
|
||||
- [@official@InfluxDB Website](https://www.influxdata.com/)
|
||||
- [@article@Time series database](https://www.influxdata.com/time-series-database/)
|
||||
- [@video@The Basics of Time Series Data](https://www.youtube.com/watch?v=wBWTj-1XiRU)
|
||||
- [@feed@Explore top posts about Backend Development](https://app.daily.dev/tags/backend?ref=roadmapsh)
|
||||
|
||||
@@ -1,14 +1,11 @@
|
||||
# Instrumentation, Monitoring, and Telemetry
|
||||
|
||||
Instrumentation refers to the measure of a product's performance, in order to diagnose errors and to write trace information. Instrumentation can be of two types: source instrumentation and binary instrumentation.
|
||||
|
||||
Backend monitoring allows the user to view the performance of infrastructure i.e. the components that run a web application. These include the HTTP server, middleware, database, third-party API services, and more.
|
||||
|
||||
Telemetry is the process of continuously collecting data from different components of the application. This data helps engineering teams to troubleshoot issues across services and identify the root causes. In other words, telemetry data powers observability for your distributed applications.
|
||||
Instrumentation, monitoring, and telemetry are critical components for ensuring system reliability and performance. *Instrumentation* refers to embedding code or tools within applications to capture key metrics, logs, and traces. *Monitoring* involves observing these metrics in real time to detect anomalies, failures, or performance issues, often using dashboards and alerting systems. *Telemetry* is the automated collection and transmission of this data from distributed systems, enabling visibility into system behavior. Together, these practices provide insights into the health, usage, and performance of systems, aiding in proactive issue resolution and optimizing overall system efficiency.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@What is Instrumentation?](https://en.wikipedia.org/wiki/Instrumentation_\(computer_programming\))
|
||||
- [@article@What is Monitoring?](https://www.yottaa.com/performance-monitoring-backend-vs-front-end-solutions/)
|
||||
- [@article@What is Telemetry?](https://www.sumologic.com/insight/what-is-telemetry/)
|
||||
- [@video@Observability vs. APM vs. Monitoring](https://www.youtube.com/watch?v=CAQ_a2-9UOI)
|
||||
- [@feed@Explore top posts about Monitoring](https://app.daily.dev/tags/monitoring?ref=roadmapsh)
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
# Integration Testing
|
||||
|
||||
Integration testing is a broad category of tests where multiple software modules are **integrated** and tested as a group. It is meant to test the **interaction** between multiple services, resources, or modules. For example, an API's interaction with a backend service, or a service with a database.
|
||||
Integration testing focuses on verifying the interactions between different components or modules of a software system to ensure they work together as expected. It comes after unit testing and tests how modules communicate with each other, often using APIs, databases, or third-party services. The goal is to catch issues related to the integration points, such as data mismatches, protocol errors, or misconfigurations. Integration tests help ensure that independently developed components can function seamlessly as part of a larger system, making them crucial for identifying bugs that wouldn't surface in isolated unit tests.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Integration Testing](https://www.guru99.com/integration-testing.html)
|
||||
- [@article@How to Integrate and Test Your Tech Stack](https://thenewstack.io/how-to-integrate-and-test-your-tech-stack/)
|
||||
- [@video@What is Integration Testing?](https://youtu.be/QYCaaNz8emY)
|
||||
- [@video@What is Integration Testing?](https://www.youtube.com/watch?v=kRD6PA6uxiY)
|
||||
- [@feed@Explore top posts about Testing](https://app.daily.dev/tags/testing?ref=roadmapsh)
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Internet
|
||||
|
||||
The Internet is a global network of computers connected to each other which communicate through a standardized set of protocols.
|
||||
The internet is a global network of interconnected computers that communicate using standardized protocols, primarily TCP/IP. When you request a webpage, your device sends a data packet through your internet service provider (ISP) to a DNS server, which translates the website's domain name into an IP address. The packet is then routed across various networks (using routers and switches) to the destination server, which processes the request and sends back the response. This back-and-forth exchange enables the transfer of data like web pages, emails, and files, making the internet a dynamic, decentralized system for global communication.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
@@ -9,5 +9,5 @@ Visit the following resources to learn more:
|
||||
- [@article@How Does the Internet Work?](http://web.stanford.edu/class/msande91si/www-spr04/readings/week1/InternetWhitepaper.htm)
|
||||
- [@roadmap.sh@Introduction to Internet](/guides/what-is-internet)
|
||||
- [@video@How does the Internet work?](https://www.youtube.com/watch?v=x3c1ih2NJEg)
|
||||
- [@video@How the Internet Works in 5 Minutes](https://www.youtube.com/watch?v=7_LPdttKXPc)
|
||||
- [@video@Computer Network | Google IT Support Certificate](https://www.youtube.com/watch?v=Z_hU2zm4_S8)
|
||||
- [@video@How does the internet work? (Full Course)](https://www.youtube.com/watch?v=zN8YNNHcaZc)
|
||||
|
||||
|
||||
@@ -1,13 +1,11 @@
|
||||
# Java
|
||||
|
||||
Java is general-purpose language, primarily used for Internet-based applications.
|
||||
It was created in 1995 by James Gosling at Sun Microsystems and is one of the most popular options for backend developers.
|
||||
Java is a high-level, object-oriented programming language known for its portability, robustness, and scalability. Developed by Sun Microsystems (now Oracle), Java follows the "write once, run anywhere" principle, allowing code to run on any device with a Java Virtual Machine (JVM). It's widely used for building large-scale enterprise applications, Android mobile apps, and web services. Java features automatic memory management (garbage collection), a vast standard library, and strong security features, making it a popular choice for backend systems, distributed applications, and cloud-based solutions.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@roadmap@Visit Dedicated Java Roadmap](/java)
|
||||
- [@official@Java Website](https://www.java.com/)
|
||||
- [@article@W3 Schools Tutorials](https://www.w3schools.com/java/)
|
||||
- [@video@Java Crash Course](https://www.youtube.com/watch?v=eIrMbAQSU34)
|
||||
- [@video@Complete Java course](https://www.youtube.com/watch?v=xk4_1vDrzzo)
|
||||
- [@feed@Explore top posts about Java](https://app.daily.dev/tags/java?ref=roadmapsh)
|
||||
|
||||
@@ -1,11 +1,11 @@
|
||||
# JavaScript
|
||||
|
||||
JavaScript allows you to add interactivity to your pages. Common examples that you may have seen on the websites are sliders, click interactions, popups and so on.
|
||||
JavaScript is a versatile, high-level programming language primarily used for adding interactivity and dynamic features to websites. It runs in the browser, allowing for client-side scripting that can manipulate HTML and CSS, respond to user events, and interact with web APIs. JavaScript is also used on the server side with environments like Node.js, enabling full-stack development. It supports event-driven, functional, and imperative programming styles, and has a rich ecosystem of libraries and frameworks (like React, Angular, and Vue) that enhance its capabilities and streamline development.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@roadmap@Visit Dedicated JavaScript Roadmap](/javascript)
|
||||
- [@article@The Modern JavaScript Tutorial](https://javascript.info/)
|
||||
- [@video@JavaScript Crash Course for Beginners](https://youtu.be/hdI2bqOjy3c?t=2)
|
||||
- [@article@Build 30 Javascript projects in 30 days](https://javascript30.com/)
|
||||
- [@video@JavaScript Crash Course for Beginners](https://youtu.be/hdI2bqOjy3c?t=2)
|
||||
- [@feed@Explore top posts about JavaScript](https://app.daily.dev/tags/javascript?ref=roadmapsh)
|
||||
|
||||
@@ -5,5 +5,5 @@ JSON or JavaScript Object Notation is an encoding scheme that is designed to eli
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@official@Official Website](https://jsonapi.org/)
|
||||
- [@official@Official Docs](https://jsonapi.org/implementations/)
|
||||
- [@video@JSON API: Explained in 4 minutes ](https://www.youtube.com/watch?v=N-4prIh7t38)
|
||||
- [@article@What is JSON API?](https://medium.com/@niranjan.cs/what-is-json-api-3b824fba2788)
|
||||
- [@video@JSON API: Explained in 4 minutes](https://www.youtube.com/watch?v=N-4prIh7t38)
|
||||
|
||||
@@ -1,12 +1,10 @@
|
||||
# JWT
|
||||
|
||||
JWT stands for JSON Web Token is a token-based encryption open standard/methodology that is used to transfer information securely as a JSON object. Clients and Servers use JWT to securely share information, with the JWT containing encoded JSON objects and claims. JWT tokens are designed to be compact, safe to use within URLs, and ideal for SSO contexts.
|
||||
JWT (JSON Web Token) is an open standard for securely transmitting information between parties as a JSON object. It consists of three parts: a header (which specifies the token type and algorithm used for signing), a payload (which contains the claims or the data being transmitted), and a signature (which is used to verify the token’s integrity and authenticity). JWTs are commonly used for authentication and authorization purposes, allowing users to securely transmit and validate their identity and permissions across web applications and APIs. They are compact, self-contained, and can be easily transmitted in HTTP headers, making them popular for modern web and mobile applications.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@official@jwt.io Website](https://jwt.io/)
|
||||
- [@official@Introduction to JSON Web Tokens](https://jwt.io/introduction)
|
||||
- [@article@What is JWT?](https://www.akana.com/blog/what-is-jwt)
|
||||
- [@video@What Is JWT and Why Should You Use JWT](https://www.youtube.com/watch?v=7Q17ubqLfaM)
|
||||
- [@video@What is JWT? JSON Web Token Explained](https://www.youtube.com/watch?v=926mknSW9Lo)
|
||||
- [@feed@Explore top posts about JWT](https://app.daily.dev/tags/jwt?ref=roadmapsh)
|
||||
|
||||
@@ -1,9 +1,10 @@
|
||||
# Kafka
|
||||
|
||||
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
|
||||
Apache Kafka is a distributed event streaming platform designed for high-throughput, fault-tolerant data processing. It acts as a message broker, allowing systems to publish and subscribe to streams of records, similar to a distributed commit log. Kafka is highly scalable and can handle large volumes of data with low latency, making it ideal for real-time analytics, log aggregation, and data integration. It features topics for organizing data streams, partitions for parallel processing, and replication for fault tolerance, enabling reliable and efficient handling of large-scale data flows across distributed systems.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Apache Kafka quickstart](https://kafka.apache.org/quickstart)
|
||||
- [@official@Apache Kafka quickstart](https://kafka.apache.org/quickstart)
|
||||
- [@video@Apache Kafka Fundamentals](https://www.youtube.com/watch?v=B5j3uNBH8X4)
|
||||
- [@video@Kafka in 100 Seconds](https://www.youtube.com/watch?v=uvb00oaa3k8)
|
||||
- [@feed@Explore top posts about Kafka](https://app.daily.dev/tags/kafka?ref=roadmapsh)
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
# APIs
|
||||
|
||||
API is the acronym for Application Programming Interface, which is a software intermediary that allows two applications to talk to each other.
|
||||
An API (Application Programming Interface) is a set of defined rules and protocols that allow different software applications to communicate and interact with each other. It provides a standardized way for developers to access and manipulate the functionalities or data of a service, application, or platform without needing to understand its internal workings. APIs can be public or private and are commonly used to integrate disparate systems, facilitate third-party development, and enable interoperability between applications. They typically include endpoints, request methods (like GET, POST, PUT), and data formats (like JSON or XML) to interact with.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@What is an API?](https://aws.amazon.com/what-is/api/)
|
||||
- [@video@What is an API?](https://www.youtube.com/watch?v=s7wmiS2mSXY)
|
||||
- [@video@What is an API (in 5 minutes)](https://www.youtube.com/watch?v=ByGJQzlzxQg)
|
||||
- [@feed@daily.dev API Feed](https://app.daily.dev/tags/rest-api)
|
||||
@@ -1,11 +1,7 @@
|
||||
# Load Shifting
|
||||
|
||||
Load shifting is a design pattern that is used to manage the workload of a system by shifting the load to different components or resources at different times. It is commonly used in cloud computing environments to balance the workload of a system and to optimize the use of resources.
|
||||
Load shifting is a strategy used to manage and distribute computing or system workloads more efficiently by moving or redistributing the load from peak times to off-peak periods. This approach helps in balancing the demand on resources, optimizing performance, and reducing costs. In cloud computing and data centers, load shifting can involve rescheduling jobs, leveraging different regions or availability zones, or adjusting resource allocation based on real-time demand. By smoothing out peak loads, organizations can enhance system reliability, minimize latency, and better utilize their infrastructure.
|
||||
|
||||
There are several ways to implement load shifting in a cloud environment:
|
||||
Learn more from the following resources:
|
||||
|
||||
- Scheduling: This involves scheduling the execution of tasks or workloads to occur at specific times or intervals.
|
||||
- Load balancing: This involves distributing the workload of a system across multiple resources, such as servers or containers, to ensure that the workload is balanced and that resources are used efficiently.
|
||||
- Auto-scaling: This involves automatically adjusting the number of resources that are available to a system based on the workload, allowing the system to scale up or down as needed.
|
||||
|
||||
Load shifting is an important aspect of cloud design, as it helps to ensure that resources are used efficiently and that the system remains stable and available. It is often used in conjunction with other design patterns, such as throttling and backpressure, to provide a scalable and resilient cloud environment.
|
||||
- [@video@Load Shifting 101](https://www.youtube.com/watch?v=DOyMJEdk5aE)
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
Long polling is a technique where the client polls the server for new data. However, if the server does not have any data available for the client, instead of sending an empty response, the server holds the request and waits for some specified period of time for new data to be available. If new data becomes available during that time, the server immediately sends a response to the client, completing the open request. If no new data becomes available and the timeout period specified by the client expires, the server sends a response indicating that fact. The client will then immediately re-request data from the server, creating a new request-response cycle.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
Learn more from the following resources:
|
||||
|
||||
- [@article@Long polling](https://javascript.info/long-polling)
|
||||
- [@article@What are Long-Polling, Websockets, Server-Sent Events (SSE) and Comet?](https://stackoverflow.com/questions/11077857/what-are-long-polling-websockets-server-sent-events-sse-and-comet)
|
||||
- [@article@Long Polling](https://javascript.info/long-polling)
|
||||
- [@video@What is Long Polling?](https://www.youtube.com/watch?v=LD0_-uIsnOE)
|
||||
|
||||
@@ -4,7 +4,7 @@ LXC is an abbreviation used for Linux Containers which is an operating system th
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@LXC Documentation](https://linuxcontainers.org/lxc/documentation/)
|
||||
- [@official@LXC Documentation](https://linuxcontainers.org/lxc/documentation/)
|
||||
- [@article@What is LXC?](https://linuxcontainers.org/lxc/introduction/)
|
||||
- [@video@Linux Container (LXC) Introduction](https://youtu.be/_KnmRdK69qM)
|
||||
- [@video@Getting started with LXD Containerization](https://www.youtube.com/watch?v=aIwgPKkVj8s)
|
||||
- [@video@Getting started with LXC containers](https://youtu.be/CWmkSj_B-wo)
|
||||
|
||||
@@ -6,6 +6,5 @@ Visit the following resources to learn more:
|
||||
|
||||
- [@official@MariaDB website](https://mariadb.org/)
|
||||
- [@article@MariaDB vs MySQL](https://www.guru99.com/mariadb-vs-mysql.html)
|
||||
- [@article@W3Schools - MariaDB tutorial ](https://www.w3schools.blog/mariadb-tutorial)
|
||||
- [@video@MariaDB Tutorial For Beginners in One Hour](https://www.youtube.com/watch?v=_AMj02sANpI)
|
||||
- [@feed@Explore top posts about Infrastructure](https://app.daily.dev/tags/infrastructure?ref=roadmapsh)
|
||||
|
||||
@@ -1,9 +1,10 @@
|
||||
# MD5
|
||||
|
||||
MD5 (Message-Digest Algorithm 5) is a hash function that is currently advised not to be used due to its extensive vulnerabilities. It is still used as a checksum to verify data integrity.
|
||||
MD5 (Message-Digest Algorithm 5) is a widely used cryptographic hash function that produces a 128-bit hash value, typically represented as a 32-character hexadecimal number. It was designed to provide a unique identifier for data by generating a fixed-size output (the hash) for any input. While MD5 was once popular for verifying data integrity and storing passwords, it is now considered cryptographically broken and unsuitable for security-sensitive applications due to vulnerabilities that allow for collision attacks (where two different inputs produce the same hash). As a result, MD5 has largely been replaced by more secure hash functions like SHA-256.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Wikipedia - MD5](https://en.wikipedia.org/wiki/MD5)
|
||||
- [@article@What is MD5?](https://www.techtarget.com/searchsecurity/definition/MD5)
|
||||
- [@article@Why is MD5 not safe?](https://infosecscout.com/why-md5-is-not-safe/)
|
||||
- [@video@How the MD5 hash function works](https://www.youtube.com/watch?v=5MiMK45gkTY)
|
||||
|
||||
@@ -1,13 +1,11 @@
|
||||
# Memcached
|
||||
|
||||
Memcached (pronounced variously mem-cash-dee or mem-cashed) is a general-purpose distributed memory-caching system. It is often used to speed up dynamic database-driven websites by caching data and objects in RAM to reduce the number of times an external data source (such as a database or API) must be read. Memcached is free and open-source software, licensed under the Revised BSD license. Memcached runs on Unix-like operating systems (Linux and macOS) and on Microsoft Windows. It depends on the `libevent` library.
|
||||
|
||||
Memcached's APIs provide a very large hash table distributed across multiple machines. When the table is full, subsequent inserts cause older data to be purged in the least recently used (LRU) order. Applications using Memcached typically layer requests and additions into RAM before falling back on a slower backing store, such as a database.
|
||||
Memcached (pronounced variously mem-cash-dee or mem-cashed) is a general-purpose distributed memory-caching system. It is often used to speed up dynamic database-driven websites by caching data and objects in RAM to reduce the number of times an external data source (such as a database or API) must be read. Memcached is free and open-source software, licensed under the Revised BSD license. Memcached runs on Unix-like operating systems (Linux and macOS) and on Microsoft Windows. It depends on the `libevent` library. Memcached's APIs provide a very large hash table distributed across multiple machines. When the table is full, subsequent inserts cause older data to be purged in the least recently used (LRU) order. Applications using Memcached typically layer requests and additions into RAM before falling back on a slower backing store, such as a database.
|
||||
|
||||
Memcached has no internal mechanism to track misses which may happen. However, some third-party utilities provide this functionality.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Memcached, From Wikipedia](https://en.wikipedia.org/wiki/Memcached)
|
||||
- [@opensource@Memcached, From Official Github](https://github.com/memcached/memcached#readme)
|
||||
- [@opensource@memcached/memcached](https://github.com/memcached/memcached#readme)
|
||||
- [@article@Memcached Tutorial](https://www.tutorialspoint.com/memcached/index.htm)
|
||||
- [@video@Redis vs Memcached](https://www.youtube.com/watch?v=Gyy1SiE8avE)
|
||||
|
||||
@@ -1,7 +1,9 @@
|
||||
# Message Brokers
|
||||
|
||||
Message brokers are an inter-application communication technology to help build a common integration mechanism to support cloud-native, microservices-based, serverless, and hybrid cloud architectures. Two of the most famous message brokers are `RabbitMQ` and `Apache Kafka`
|
||||
Message brokers are intermediaries that facilitate communication between distributed systems or components by receiving, routing, and delivering messages. They enable asynchronous message passing, decoupling producers (senders) from consumers (receivers), which improves scalability and flexibility. Common functions of message brokers include message queuing, load balancing, and ensuring reliable message delivery through features like persistence and acknowledgment. Popular message brokers include Apache Kafka, RabbitMQ, and ActiveMQ, each offering different features and capabilities suited to various use cases like real-time data processing, event streaming, or task management.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@What are message brokers?](https://www.ibm.com/topics/message-brokers)
|
||||
- [@video@Introduction to Message Brokers](https://www.youtube.com/watch?v=57Qr9tk6Uxc)
|
||||
- [@video@Kafka vs RabbitMQ](https://www.youtube.com/watch?v=_5mu7lZz5X4)
|
||||
|
||||
@@ -1,12 +1,12 @@
|
||||
# Microservices
|
||||
|
||||
Microservice architecture is a pattern in which highly cohesive, loosely coupled services are separately developed, maintained, and deployed. Each component handles an individual function, and when combined, the application handles an overall business function.
|
||||
Microservices is an architectural style that structures an application as a collection of loosely coupled, independently deployable services. Each microservice focuses on a specific business capability and communicates with others via lightweight protocols, typically HTTP or messaging queues. This approach allows for greater scalability, flexibility, and resilience, as services can be developed, deployed, and scaled independently. Microservices also facilitate the use of diverse technologies and languages for different components, and they support continuous delivery and deployment. However, managing microservices involves complexity in terms of inter-service communication, data consistency, and deployment orchestration.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@official@Pattern: Microservice Architecture](https://microservices.io/patterns/microservices.html)
|
||||
- [@article@Pattern: Microservice Architecture](https://microservices.io/patterns/microservices.html)
|
||||
- [@article@What is Microservices?](https://smartbear.com/solutions/microservices/)
|
||||
- [@article@Microservices 101](https://thenewstack.io/microservices-101/)
|
||||
- [@article@Primer: Microservices Explained](https://thenewstack.io/primer-microservices-explained/)
|
||||
- [@article@Articles about Microservices](https://thenewstack.io/category/microservices/)
|
||||
- [@video@Microservices explained in 5 minutes](https://www.youtube.com/watch?v=lL_j7ilk7rc)
|
||||
- [@feed@Explore top posts about Microservices](https://app.daily.dev/tags/microservices?ref=roadmapsh)
|
||||
|
||||
@@ -1,7 +1,17 @@
|
||||
# Migration Strategies
|
||||
|
||||
Learn how to run database migrations effectively. Especially zero downtime multi-phase schema migrations. Rather than make all changes at once, do smaller incremental changes to allow old code, and new code to work with the database at the same time, before removing old code, and finally removing the parts of the database schema which is no longer used.
|
||||
Migration strategies involve planning and executing the transition of applications, data, or infrastructure from one environment to another, such as from on-premises systems to the cloud or between different cloud providers. Key strategies include:
|
||||
|
||||
1. **Rehost (Lift and Shift)**: Moving applications as-is to the new environment with minimal changes, which is often the quickest but may not fully leverage new platform benefits.
|
||||
2. **Replatform**: Making some optimizations or changes to adapt applications for the new environment, enhancing performance or scalability while retaining most of the existing architecture.
|
||||
3. **Refactor**: Redesigning and modifying applications to optimize for the new environment, often taking advantage of new features and improving functionality or performance.
|
||||
4. **Repurchase**: Replacing existing applications with new, often cloud-based, solutions that better meet current needs.
|
||||
5. **Retain**: Keeping certain applications or systems in their current environment due to specific constraints or requirements.
|
||||
6. **Retire**: Decommissioning applications that are no longer needed or are redundant.
|
||||
|
||||
Each strategy has its own trade-offs in terms of cost, complexity, and benefits, and the choice depends on factors like the application’s architecture, business needs, and resource availability.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Databases as a Challenge for Continuous Delivery](https://phauer.com/2015/databases-challenge-continuous-delivery/)
|
||||
- [@video@AWS Cloud Migration Strategies](https://www.youtube.com/watch?v=9ziB82V7qVM)
|
||||
|
||||
@@ -1,13 +1,11 @@
|
||||
# MongoDB
|
||||
|
||||
MongoDB is a source-available cross-platform document-oriented database program. Classified as a NoSQL database program, MongoDB uses JSON-like documents with optional schemas. MongoDB is developed by MongoDB Inc. and licensed under the Server Side Public License (SSPL).
|
||||
MongoDB is a NoSQL, open-source database designed for storing and managing large volumes of unstructured or semi-structured data. It uses a document-oriented data model where data is stored in BSON (Binary JSON) format, which allows for flexible and hierarchical data representation. Unlike traditional relational databases, MongoDB doesn't require a fixed schema, making it suitable for applications with evolving data requirements or varying data structures. It supports horizontal scaling through sharding and offers high availability with replica sets. MongoDB is commonly used for applications requiring rapid development, real-time analytics, and large-scale data handling, such as content management systems, IoT applications, and big data platforms.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@roadmap@Visit Dedicated MongoDB Roadmap](/mongodb)
|
||||
- [@article@MongoDB Website](https://www.mongodb.com/)
|
||||
- [@article@MongoDB Documentation](https://docs.mongodb.com/)
|
||||
- [@official@MongoDB Website](https://www.mongodb.com/)
|
||||
- [@official@Learning Path for MongoDB Developers](https://learn.mongodb.com/catalog)
|
||||
- [@article@MongoDB Online Sandbox](https://mongoplayground.net/)
|
||||
- [@article@Learning Path for MongoDB Developers](https://learn.mongodb.com/catalog)
|
||||
- [@article@Dynamo DB Docs](https://docs.aws.amazon.com/dynamodb/index.html)
|
||||
- [@article@Official Developers Guide](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Introduction.html)
|
||||
- [@feed@daily.dev MongoDB Feed](https://app.daily.dev/tags/mongodb)
|
||||
|
||||
@@ -1,18 +1,9 @@
|
||||
# Monitoring
|
||||
|
||||
Distributed systems are hard to build, deploy and maintain. They consist of multiple components which communicate with each other. In parallel to that, users use the system, resulting in multiple requests. Making sense of this noise is important to understand:
|
||||
- how the system behaves
|
||||
- is it broken
|
||||
- is it fast enough
|
||||
- what can be improved
|
||||
Monitoring involves continuously observing and tracking the performance, availability, and health of systems, applications, and infrastructure. It typically includes collecting and analyzing metrics, logs, and events to ensure systems are operating within desired parameters. Monitoring helps detect anomalies, identify potential issues before they escalate, and provides insights into system behavior. It often involves tools and platforms that offer dashboards, alerts, and reporting features to facilitate real-time visibility and proactive management. Effective monitoring is crucial for maintaining system reliability, performance, and for supporting incident response and troubleshooting.
|
||||
|
||||
A product can integrate with existing monitoring products (APM - application performance management). They can show a detailed view of each request - its user, time, components involved, state(error or OK) etc.
|
||||
A few popular tools are Grafana, Sentry, Mixpanel, NewRelic.
|
||||
|
||||
We can build dashboards with custom events or metrics according to our needs. Automatic alert rules can be configured on top of these events/metrics.
|
||||
|
||||
A few popular tools are Grafana, Sentry, Mixpanel, NewRelic etc
|
||||
|
||||
- [@article@Observability vs Monitoring?](https://www.dynatrace.com/news/blog/observability-vs-monitoring/)
|
||||
- [@article@What is APM?](https://www.sumologic.com/blog/the-role-of-apm-and-distributed-tracing-in-observability/)
|
||||
- [@article@Top monitoring tools 2024](https://thectoclub.com/tools/best-application-monitoring-software/)
|
||||
- [@article@Caching strategies](https://medium.com/@genchilu/cache-strategy-in-backend-d0baaacd2d79)
|
||||
- [@video@Grafana Explained in 5 Minutes](https://www.youtube.com/watch?v=lILY8eSspEo)
|
||||
- [@feed@daily.dev Monitoring Feed](https://app.daily.dev/tags/monitoring)
|
||||
@@ -1,10 +1,9 @@
|
||||
# Monolithic Apps
|
||||
|
||||
Monolithic architecture is a pattern in which an application handles requests, executes business logic, interacts with the database, and creates the HTML for the front end. In simpler terms, this one application does many things. It's inner components are highly coupled and deployed as one unit.
|
||||
|
||||
It is recommended to build simple applications as a monolith for faster development cycle. Also suitable for Proof-of-Concept(PoC) projects.
|
||||
Monolithic applications are designed as a single, cohesive unit where all components—such as user interface, business logic, and data access—are tightly integrated and run as a single service. This architecture simplifies development and deployment since the entire application is managed and deployed together. However, it can lead to challenges with scalability, maintainability, and agility as the application grows. Changes to one part of the application may require redeploying the entire system, and scaling might necessitate duplicating the entire application rather than scaling individual components. Monolithic architectures can be suitable for smaller applications or projects with less complex requirements, but many organizations transition to microservices or modular architectures to address these limitations as they scale.
|
||||
|
||||
Visit the following resources to learn more:
|
||||
|
||||
- [@article@Pattern: Monolithic Architecture](https://microservices.io/patterns/monolithic.html)
|
||||
- [@article@Monolithic Architecture - Advantages & Disadvantages](https://datamify.medium.com/monolithic-architecture-advantages-and-disadvantages-e71a603eec89)
|
||||
- [@video@Monolithic vs Microservice Architecture](https://www.youtube.com/watch?v=NdeTGlZ__Do)
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user