Compare commits
43 Commits
fix/sync-c
...
content/da
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
f6589f9a8c | ||
|
|
5c287d825f | ||
|
|
449e8f12e4 | ||
|
|
a15b13cedd | ||
|
|
609683db2f | ||
|
|
3e21d05767 | ||
|
|
82edfba6e9 | ||
|
|
65d7a737ac | ||
|
|
2e0a69ad72 | ||
|
|
485ffcf755 | ||
|
|
933c568066 | ||
|
|
3b809d9f81 | ||
|
|
12ae7de3c5 | ||
|
|
9316d4027f | ||
|
|
5a63432412 | ||
|
|
ffecb5ae1a | ||
|
|
efd5d20089 | ||
|
|
7a51c1af6c | ||
|
|
6970cccc85 | ||
|
|
78940d44a9 | ||
|
|
6f11403a41 | ||
|
|
214799b0c2 | ||
|
|
b5f564cba4 | ||
|
|
3a4514b9f1 | ||
|
|
df53280ee9 | ||
|
|
487a6a222b | ||
|
|
7933e222ee | ||
|
|
e7b8c033fb | ||
|
|
d893d0fe5d | ||
|
|
1c8571e484 | ||
|
|
3b43ed33c1 | ||
|
|
8a276d8e04 | ||
|
|
36a9e987b5 | ||
|
|
402104665e | ||
|
|
9ec3c1fb9d | ||
|
|
179cefe4da | ||
|
|
93c1ea0496 | ||
|
|
c9ee8b0ee0 | ||
|
|
0d5bce309e | ||
|
|
87a2d493e2 | ||
|
|
4c7daa6a5b | ||
|
|
88ac6406f9 | ||
|
|
374a56eeff |
@@ -3,6 +3,6 @@
|
||||
"enabled": false
|
||||
},
|
||||
"_variables": {
|
||||
"lastUpdateCheck": 1755042938009
|
||||
"lastUpdateCheck": 1756224238932
|
||||
}
|
||||
}
|
||||
7
.github/workflows/sync-content-to-repo.yml
vendored
@@ -50,11 +50,10 @@ jobs:
|
||||
branch: "chore/sync-content-to-repo-${{ inputs.roadmap_slug }}"
|
||||
base: "master"
|
||||
labels: |
|
||||
dependencies
|
||||
automated pr
|
||||
reviewers: arikchakma
|
||||
reviewers: jcanalesluna,kamranahmedse
|
||||
commit-message: "chore: sync content to repo"
|
||||
title: "chore: sync content to repository"
|
||||
title: "chore: sync content to repository - ${{ inputs.roadmap_slug }}"
|
||||
body: |
|
||||
## Sync Content to Repo
|
||||
|
||||
@@ -64,4 +63,4 @@ jobs:
|
||||
> Commit: ${{ github.sha }}
|
||||
> Workflow Path: ${{ github.workflow_ref }}
|
||||
|
||||
**Please Review the Changes and Merge the PR if everything is fine.**
|
||||
**Please Review the Changes and Merge the PR if everything is fine.**
|
||||
|
||||
2
.github/workflows/sync-repo-to-database.yml
vendored
@@ -46,7 +46,7 @@ jobs:
|
||||
echo "$CHANGED_FILES"
|
||||
|
||||
# Convert to space-separated list for the script
|
||||
CHANGED_FILES_LIST=$(echo "$CHANGED_FILES" | tr '\n' ' ')
|
||||
CHANGED_FILES_LIST=$(echo "$CHANGED_FILES" | tr '\n' ',')
|
||||
|
||||
echo "has_changes=true" >> $GITHUB_OUTPUT
|
||||
echo "changed_files=$CHANGED_FILES_LIST" >> $GITHUB_OUTPUT
|
||||
|
||||
@@ -31,6 +31,7 @@
|
||||
"migrate:editor-roadmaps": "tsx ./scripts/migrate-editor-roadmap.ts",
|
||||
"sync:content-to-repo": "tsx ./scripts/sync-content-to-repo.ts",
|
||||
"sync:repo-to-database": "tsx ./scripts/sync-repo-to-database.ts",
|
||||
"migrate:content-repo-to-database": "tsx ./scripts/migrate-content-repo-to-database.ts",
|
||||
"test:e2e": "playwright test"
|
||||
},
|
||||
"dependencies": {
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 351 KiB |
{kind=link}
|
Before Width: | Height: | Size: 420 KiB |
{kind=link}
|
Before Width: | Height: | Size: 36 KiB |
{kind=link}
|
Before Width: | Height: | Size: 34 KiB |
{kind=link}
|
Before Width: | Height: | Size: 36 KiB |
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |
{kind=link}
|
Before Width: | Height: | Size: 126 KiB |
{kind=link}
|
Before Width: | Height: | Size: 431 KiB |
{kind=link}
|
Before Width: | Height: | Size: 235 KiB |
{kind=link}
|
Before Width: | Height: | Size: 205 KiB |
{kind=link}
|
Before Width: | Height: | Size: 242 KiB |
{kind=link}
|
Before Width: | Height: | Size: 572 KiB |
{kind=link}
|
Before Width: | Height: | Size: 283 KiB |
{kind=link}
|
Before Width: | Height: | Size: 437 KiB |
{kind=link}
|
Before Width: | Height: | Size: 799 KiB |
{kind=link}
|
Before Width: | Height: | Size: 233 KiB |
{kind=link}
|
Before Width: | Height: | Size: 1.0 MiB |
{kind=link}
|
Before Width: | Height: | Size: 756 KiB |
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |
{kind=link}
|
Before Width: | Height: | Size: 7.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 18 KiB |
{kind=link}
|
Before Width: | Height: | Size: 142 KiB |
{kind=link}
|
Before Width: | Height: | Size: 1.4 MiB |
{kind=link}
|
Before Width: | Height: | Size: 685 KiB |
{kind=link}
|
Before Width: | Height: | Size: 128 KiB |
{kind=link}
|
Before Width: | Height: | Size: 92 KiB |
{kind=link}
|
Before Width: | Height: | Size: 835 KiB |
{kind=link}
|
Before Width: | Height: | Size: 602 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 18 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 25 KiB |
{kind=link}
|
Before Width: | Height: | Size: 24 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 11 KiB |
{kind=link}
|
Before Width: | Height: | Size: 11 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB |
{kind=link}
|
Before Width: | Height: | Size: 44 KiB |
{kind=link}
|
Before Width: | Height: | Size: 26 KiB |
{kind=link}
|
Before Width: | Height: | Size: 345 KiB |
{kind=link}
|
Before Width: | Height: | Size: 516 KiB |
BIN
public/pdfs/roadmaps/bi-analyst.pdf
Normal file
BIN
public/pdfs/roadmaps/nextjs.pdf
Normal file
BIN
public/roadmaps/bi-analyst.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 633 KiB |
BIN
public/roadmaps/nextjs.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 326 KiB |
@@ -47,6 +47,7 @@ Here is the list of available roadmaps with more being actively worked upon.
|
||||
- [Linux Roadmap](https://roadmap.sh/linux)
|
||||
- [Terraform Roadmap](https://roadmap.sh/terraform)
|
||||
- [Data Analyst Roadmap](https://roadmap.sh/data-analyst)
|
||||
- [BI Analyst Roadmap](https://roadmap.sh/bi-analyst)
|
||||
- [Data Engineer Roadmap](https://roadmap.sh/data-engineer)
|
||||
- [Machine Learning Roadmap](https://roadmap.sh/machine-learning)
|
||||
- [MLOps Roadmap](https://roadmap.sh/mlops)
|
||||
@@ -61,6 +62,7 @@ Here is the list of available roadmaps with more being actively worked upon.
|
||||
- [TypeScript Roadmap](https://roadmap.sh/typescript)
|
||||
- [C++ Roadmap](https://roadmap.sh/cpp)
|
||||
- [React Roadmap](https://roadmap.sh/react)
|
||||
- [Next.js Roadmap](https://roadmap.sh/nextjs)
|
||||
- [React Native Roadmap](https://roadmap.sh/react-native)
|
||||
- [Vue Roadmap](https://roadmap.sh/vue)
|
||||
- [Angular Roadmap](https://roadmap.sh/angular)
|
||||
|
||||
255
scripts/migrate-content-repo-to-database.ts
Normal file
@@ -0,0 +1,255 @@
|
||||
import fs from 'node:fs/promises';
|
||||
import path from 'node:path';
|
||||
import { fileURLToPath } from 'node:url';
|
||||
import type { OfficialRoadmapDocument } from '../src/queries/official-roadmap';
|
||||
import { parse } from 'node-html-parser';
|
||||
import { markdownToHtml } from '../src/lib/markdown';
|
||||
import { htmlToMarkdown } from '../src/lib/html';
|
||||
import matter from 'gray-matter';
|
||||
import type { RoadmapFrontmatter } from '../src/lib/roadmap';
|
||||
import {
|
||||
allowedOfficialRoadmapTopicResourceType,
|
||||
type AllowedOfficialRoadmapTopicResourceType,
|
||||
type SyncToDatabaseTopicContent,
|
||||
} from '../src/queries/official-roadmap-topic';
|
||||
|
||||
const __filename = fileURLToPath(import.meta.url);
|
||||
const __dirname = path.dirname(__filename);
|
||||
|
||||
const args = process.argv.slice(2);
|
||||
const secret = args
|
||||
.find((arg) => arg.startsWith('--secret='))
|
||||
?.replace('--secret=', '');
|
||||
if (!secret) {
|
||||
throw new Error('Secret is required');
|
||||
}
|
||||
|
||||
let roadmapJsonCache: Map<string, OfficialRoadmapDocument> = new Map();
|
||||
export async function fetchRoadmapJson(
|
||||
roadmapId: string,
|
||||
): Promise<OfficialRoadmapDocument> {
|
||||
if (roadmapJsonCache.has(roadmapId)) {
|
||||
return roadmapJsonCache.get(roadmapId)!;
|
||||
}
|
||||
|
||||
const response = await fetch(
|
||||
`https://roadmap.sh/api/v1-official-roadmap/${roadmapId}`,
|
||||
);
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error(
|
||||
`Failed to fetch roadmap json: ${response.statusText} for ${roadmapId}`,
|
||||
);
|
||||
}
|
||||
|
||||
const data = await response.json();
|
||||
if (data.error) {
|
||||
throw new Error(
|
||||
`Failed to fetch roadmap json: ${data.error} for ${roadmapId}`,
|
||||
);
|
||||
}
|
||||
|
||||
roadmapJsonCache.set(roadmapId, data);
|
||||
return data;
|
||||
}
|
||||
|
||||
export async function syncContentToDatabase(
|
||||
topics: SyncToDatabaseTopicContent[],
|
||||
) {
|
||||
const response = await fetch(
|
||||
`https://roadmap.sh/api/v1-sync-official-roadmap-topics`,
|
||||
{
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json',
|
||||
},
|
||||
body: JSON.stringify({
|
||||
topics,
|
||||
secret,
|
||||
}),
|
||||
},
|
||||
);
|
||||
|
||||
if (!response.ok) {
|
||||
const error = await response.json();
|
||||
throw new Error(
|
||||
`Failed to sync content to database: ${response.statusText} ${JSON.stringify(error, null, 2)}`,
|
||||
);
|
||||
}
|
||||
|
||||
return response.json();
|
||||
}
|
||||
|
||||
// Directory containing the roadmaps
|
||||
const ROADMAP_CONTENT_DIR = path.join(__dirname, '../src/data/roadmaps');
|
||||
const allRoadmaps = await fs.readdir(ROADMAP_CONTENT_DIR);
|
||||
|
||||
const editorRoadmapIds = new Set<string>();
|
||||
for (const roadmapId of allRoadmaps) {
|
||||
const roadmapFrontmatterDir = path.join(
|
||||
ROADMAP_CONTENT_DIR,
|
||||
roadmapId,
|
||||
`${roadmapId}.md`,
|
||||
);
|
||||
const roadmapFrontmatterRaw = await fs.readFile(
|
||||
roadmapFrontmatterDir,
|
||||
'utf-8',
|
||||
);
|
||||
const { data } = matter(roadmapFrontmatterRaw);
|
||||
|
||||
const roadmapFrontmatter = data as RoadmapFrontmatter;
|
||||
if (roadmapFrontmatter.renderer === 'editor') {
|
||||
editorRoadmapIds.add(roadmapId);
|
||||
}
|
||||
}
|
||||
|
||||
for (const roadmapId of editorRoadmapIds) {
|
||||
try {
|
||||
const roadmap = await fetchRoadmapJson(roadmapId);
|
||||
|
||||
const files = await fs.readdir(
|
||||
path.join(ROADMAP_CONTENT_DIR, roadmapId, 'content'),
|
||||
);
|
||||
|
||||
console.log(`🚀 Starting ${files.length} files for ${roadmapId}`);
|
||||
const topics: SyncToDatabaseTopicContent[] = [];
|
||||
|
||||
for (const file of files) {
|
||||
const isContentFile = file.endsWith('.md');
|
||||
if (!isContentFile) {
|
||||
console.log(`🚨 Skipping ${file} because it is not a content file`);
|
||||
continue;
|
||||
}
|
||||
|
||||
const nodeSlug = file.replace('.md', '');
|
||||
if (!nodeSlug) {
|
||||
console.error(`🚨 Node id is required: ${file}`);
|
||||
continue;
|
||||
}
|
||||
|
||||
const nodeId = nodeSlug.split('@')?.[1];
|
||||
if (!nodeId) {
|
||||
console.error(`🚨 Node id is required: ${file}`);
|
||||
continue;
|
||||
}
|
||||
|
||||
const node = roadmap.nodes.find((node) => node.id === nodeId);
|
||||
if (!node) {
|
||||
console.error(`🚨 Node not found: ${file}`);
|
||||
continue;
|
||||
}
|
||||
|
||||
const filePath = path.join(
|
||||
ROADMAP_CONTENT_DIR,
|
||||
roadmapId,
|
||||
'content',
|
||||
`${nodeSlug}.md`,
|
||||
);
|
||||
|
||||
const fileExists = await fs
|
||||
.stat(filePath)
|
||||
.then(() => true)
|
||||
.catch(() => false);
|
||||
if (!fileExists) {
|
||||
console.log(`🚨 File not found: ${filePath}`);
|
||||
continue;
|
||||
}
|
||||
|
||||
const content = await fs.readFile(filePath, 'utf8');
|
||||
const html = markdownToHtml(content, false);
|
||||
const rootHtml = parse(html);
|
||||
|
||||
let ulWithLinks: HTMLElement | undefined;
|
||||
rootHtml.querySelectorAll('ul').forEach((ul) => {
|
||||
const listWithJustLinks = Array.from(ul.querySelectorAll('li')).filter(
|
||||
(li) => {
|
||||
const link = li.querySelector('a');
|
||||
return link && link.textContent?.trim() === li.textContent?.trim();
|
||||
},
|
||||
);
|
||||
|
||||
if (listWithJustLinks.length > 0) {
|
||||
// @ts-expect-error - TODO: fix this
|
||||
ulWithLinks = ul;
|
||||
}
|
||||
});
|
||||
|
||||
const listLinks: SyncToDatabaseTopicContent['resources'] =
|
||||
ulWithLinks !== undefined
|
||||
? Array.from(ulWithLinks.querySelectorAll('li > a'))
|
||||
.map((link) => {
|
||||
const typePattern = /@([a-z.]+)@/;
|
||||
let linkText = link.textContent || '';
|
||||
const linkHref = link.getAttribute('href') || '';
|
||||
let linkType = linkText.match(typePattern)?.[1] || 'article';
|
||||
linkType = allowedOfficialRoadmapTopicResourceType.includes(
|
||||
linkType as any,
|
||||
)
|
||||
? linkType
|
||||
: 'article';
|
||||
|
||||
linkText = linkText.replace(typePattern, '');
|
||||
|
||||
if (!linkText || !linkHref) {
|
||||
return null;
|
||||
}
|
||||
|
||||
return {
|
||||
title: linkText,
|
||||
url: linkHref,
|
||||
type: linkType as AllowedOfficialRoadmapTopicResourceType,
|
||||
};
|
||||
})
|
||||
.filter((link) => link !== null)
|
||||
.sort((a, b) => {
|
||||
const order = [
|
||||
'official',
|
||||
'opensource',
|
||||
'article',
|
||||
'video',
|
||||
'feed',
|
||||
];
|
||||
return order.indexOf(a!.type) - order.indexOf(b!.type);
|
||||
})
|
||||
: [];
|
||||
|
||||
const title = rootHtml.querySelector('h1');
|
||||
ulWithLinks?.remove();
|
||||
title?.remove();
|
||||
|
||||
const allParagraphs = rootHtml.querySelectorAll('p');
|
||||
if (listLinks.length > 0 && allParagraphs.length > 0) {
|
||||
// to remove the view more see more from the description
|
||||
const lastParagraph = allParagraphs[allParagraphs.length - 1];
|
||||
lastParagraph?.remove();
|
||||
}
|
||||
|
||||
const htmlStringWithoutLinks = rootHtml.toString();
|
||||
const description = htmlToMarkdown(htmlStringWithoutLinks);
|
||||
|
||||
const updatedDescription =
|
||||
`# ${title?.textContent}\n\n${description}`.trim();
|
||||
|
||||
const label = node?.data?.label as string;
|
||||
if (!label) {
|
||||
console.error(`🚨 Label is required: ${file}`);
|
||||
continue;
|
||||
}
|
||||
|
||||
topics.push({
|
||||
roadmapSlug: roadmapId,
|
||||
nodeId,
|
||||
description: updatedDescription,
|
||||
resources: listLinks,
|
||||
});
|
||||
}
|
||||
|
||||
await syncContentToDatabase(topics);
|
||||
console.log(
|
||||
`✅ Synced ${topics.length} topics to database for ${roadmapId}`,
|
||||
);
|
||||
} catch (error) {
|
||||
console.error(error);
|
||||
process.exit(1);
|
||||
}
|
||||
}
|
||||
@@ -3,6 +3,7 @@ import path from 'node:path';
|
||||
import { fileURLToPath } from 'node:url';
|
||||
import { slugify } from '../src/lib/slugger';
|
||||
import type { OfficialRoadmapDocument } from '../src/queries/official-roadmap';
|
||||
import type { OfficialRoadmapTopicContentDocument } from '../src/queries/official-roadmap-topic';
|
||||
|
||||
const __filename = fileURLToPath(import.meta.url);
|
||||
const __dirname = path.dirname(__filename);
|
||||
@@ -19,36 +20,6 @@ if (!roadmapSlug || roadmapSlug === '__default__') {
|
||||
}
|
||||
|
||||
console.log(`🚀 Starting ${roadmapSlug}`);
|
||||
export const allowedOfficialRoadmapTopicResourceType = [
|
||||
'roadmap',
|
||||
'official',
|
||||
'opensource',
|
||||
'article',
|
||||
'course',
|
||||
'podcast',
|
||||
'video',
|
||||
'book',
|
||||
'feed',
|
||||
] as const;
|
||||
export type AllowedOfficialRoadmapTopicResourceType =
|
||||
(typeof allowedOfficialRoadmapTopicResourceType)[number];
|
||||
|
||||
export type OfficialRoadmapTopicResource = {
|
||||
_id?: string;
|
||||
type: AllowedOfficialRoadmapTopicResourceType;
|
||||
title: string;
|
||||
url: string;
|
||||
};
|
||||
|
||||
export interface OfficialRoadmapTopicContentDocument {
|
||||
_id?: string;
|
||||
roadmapSlug: string;
|
||||
nodeId: string;
|
||||
description: string;
|
||||
resources: OfficialRoadmapTopicResource[];
|
||||
createdAt: Date;
|
||||
updatedAt: Date;
|
||||
}
|
||||
|
||||
export async function roadmapTopics(
|
||||
roadmapId: string,
|
||||
|
||||
@@ -8,16 +8,20 @@ import { htmlToMarkdown } from '../src/lib/html';
|
||||
import {
|
||||
allowedOfficialRoadmapTopicResourceType,
|
||||
type AllowedOfficialRoadmapTopicResourceType,
|
||||
type OfficialRoadmapTopicContentDocument,
|
||||
type OfficialRoadmapTopicResource,
|
||||
} from './sync-content-to-repo';
|
||||
type SyncToDatabaseTopicContent,
|
||||
} from '../src/queries/official-roadmap-topic';
|
||||
|
||||
const __filename = fileURLToPath(import.meta.url);
|
||||
const __dirname = path.dirname(__filename);
|
||||
|
||||
const args = process.argv.slice(2);
|
||||
const allFiles = args?.[0]?.replace('--files=', '');
|
||||
const secret = args?.[1]?.replace('--secret=', '');
|
||||
const allFiles = args
|
||||
.find((arg) => arg.startsWith('--files='))
|
||||
?.replace('--files=', '');
|
||||
const secret = args
|
||||
.find((arg) => arg.startsWith('--secret='))
|
||||
?.replace('--secret=', '');
|
||||
|
||||
if (!secret) {
|
||||
throw new Error('Secret is required');
|
||||
}
|
||||
@@ -35,12 +39,16 @@ export async function fetchRoadmapJson(
|
||||
);
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error(`Failed to fetch roadmap json: ${response.statusText}`);
|
||||
throw new Error(
|
||||
`Failed to fetch roadmap json: ${response.statusText} for ${roadmapId}`,
|
||||
);
|
||||
}
|
||||
|
||||
const data = await response.json();
|
||||
if (data.error) {
|
||||
throw new Error(`Failed to fetch roadmap json: ${data.error}`);
|
||||
throw new Error(
|
||||
`Failed to fetch roadmap json: ${data.error} for ${roadmapId}`,
|
||||
);
|
||||
}
|
||||
|
||||
roadmapJsonCache.set(roadmapId, data);
|
||||
@@ -48,15 +56,15 @@ export async function fetchRoadmapJson(
|
||||
}
|
||||
|
||||
export async function syncContentToDatabase(
|
||||
topics: Omit<
|
||||
OfficialRoadmapTopicContentDocument,
|
||||
'createdAt' | 'updatedAt' | '_id'
|
||||
>[],
|
||||
topics: SyncToDatabaseTopicContent[],
|
||||
) {
|
||||
const response = await fetch(
|
||||
`https://roadmap.sh/api/v1-sync-official-roadmap-topics`,
|
||||
{
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json',
|
||||
},
|
||||
body: JSON.stringify({
|
||||
topics,
|
||||
secret,
|
||||
@@ -65,24 +73,30 @@ export async function syncContentToDatabase(
|
||||
);
|
||||
|
||||
if (!response.ok) {
|
||||
const error = await response.json();
|
||||
throw new Error(
|
||||
`Failed to sync content to database: ${response.statusText}`,
|
||||
`Failed to sync content to database: ${response.statusText} ${JSON.stringify(error, null, 2)}`,
|
||||
);
|
||||
}
|
||||
|
||||
return response.json();
|
||||
}
|
||||
|
||||
const files = allFiles.split(' ');
|
||||
console.log(`🚀 Starting ${files.length} files`);
|
||||
const files =
|
||||
allFiles
|
||||
?.split(',')
|
||||
.map((file) => file.trim())
|
||||
.filter(Boolean) || [];
|
||||
if (files.length === 0) {
|
||||
console.log('No files to sync');
|
||||
process.exit(0);
|
||||
}
|
||||
|
||||
console.log(`🚀 Starting ${files.length} files`);
|
||||
const ROADMAP_CONTENT_DIR = path.join(__dirname, '../src/data/roadmaps');
|
||||
|
||||
try {
|
||||
const topics: Omit<
|
||||
OfficialRoadmapTopicContentDocument,
|
||||
'createdAt' | 'updatedAt' | '_id'
|
||||
>[] = [];
|
||||
const topics: SyncToDatabaseTopicContent[] = [];
|
||||
|
||||
for (const file of files) {
|
||||
const isContentFile = file.endsWith('.md') && file.includes('content/');
|
||||
@@ -124,6 +138,15 @@ try {
|
||||
`${nodeSlug}.md`,
|
||||
);
|
||||
|
||||
const fileExists = await fs
|
||||
.stat(filePath)
|
||||
.then(() => true)
|
||||
.catch(() => false);
|
||||
if (!fileExists) {
|
||||
console.log(`🚨 File not found: ${filePath}`);
|
||||
continue;
|
||||
}
|
||||
|
||||
const content = await fs.readFile(filePath, 'utf8');
|
||||
const html = markdownToHtml(content, false);
|
||||
const rootHtml = parse(html);
|
||||
@@ -143,7 +166,7 @@ try {
|
||||
}
|
||||
});
|
||||
|
||||
const listLinks: Omit<OfficialRoadmapTopicResource, '_id'>[] =
|
||||
const listLinks: SyncToDatabaseTopicContent['resources'] =
|
||||
ulWithLinks !== undefined
|
||||
? Array.from(ulWithLinks.querySelectorAll('li > a'))
|
||||
.map((link) => {
|
||||
|
||||
@@ -1,45 +1,46 @@
|
||||
---
|
||||
import { DateTime } from 'luxon';
|
||||
import type { ChangelogFileType } from '../../lib/changelog';
|
||||
import ChangelogImages from '../ChangelogImages';
|
||||
import type { ChangelogDocument } from '../../queries/changelog';
|
||||
|
||||
interface Props {
|
||||
changelog: ChangelogFileType;
|
||||
changelog: ChangelogDocument;
|
||||
}
|
||||
|
||||
const { changelog } = Astro.props;
|
||||
const { frontmatter } = changelog;
|
||||
|
||||
const formattedDate = DateTime.fromISO(frontmatter.date).toFormat(
|
||||
const formattedDate = DateTime.fromISO(changelog.createdAt).toFormat(
|
||||
'dd LLL, yyyy',
|
||||
);
|
||||
---
|
||||
|
||||
<div class='relative mb-6' id={changelog.id}>
|
||||
<span
|
||||
class='absolute -left-6 top-2 h-2 w-2 shrink-0 rounded-full bg-gray-300'
|
||||
<div class='relative mb-6' id={changelog._id}>
|
||||
<span class='absolute top-2 -left-6 h-2 w-2 shrink-0 rounded-full bg-gray-300'
|
||||
></span>
|
||||
|
||||
<div class='mb-3 flex flex-col sm:flex-row items-start sm:items-center gap-0.5 sm:gap-2'>
|
||||
<div
|
||||
class='mb-3 flex flex-col items-start gap-0.5 sm:flex-row sm:items-center sm:gap-2'
|
||||
>
|
||||
<span class='shrink-0 text-xs tracking-wide text-gray-400'>
|
||||
{formattedDate}
|
||||
</span>
|
||||
<span class='truncate text-base font-medium text-balance'>
|
||||
{changelog.frontmatter.title}
|
||||
{changelog.title}
|
||||
</span>
|
||||
</div>
|
||||
|
||||
<div class='rounded-xl border bg-white p-6'>
|
||||
{frontmatter.images && (
|
||||
<div class='mb-5 hidden sm:block -mx-6'>
|
||||
<ChangelogImages images={frontmatter.images} client:load />
|
||||
</div>
|
||||
)}
|
||||
{
|
||||
changelog.images && (
|
||||
<div class='-mx-6 mb-5 hidden sm:block'>
|
||||
<ChangelogImages images={changelog.images} client:load />
|
||||
</div>
|
||||
)
|
||||
}
|
||||
|
||||
<div
|
||||
class='prose prose-sm prose-h2:mt-3 prose-h2:text-lg prose-h2:font-medium prose-p:mb-0 prose-blockquote:font-normal prose-blockquote:text-gray-500 prose-ul:my-0 prose-ul:rounded-lg prose-ul:bg-gray-100 prose-ul:px-4 prose-ul:py-4 prose-ul:pl-7 prose-img:mt-0 prose-img:rounded-lg [&>blockquote>p]:mt-0 [&>ul>li]:my-0 [&>ul>li]:mb-1 [&>ul]:mt-3'
|
||||
>
|
||||
<changelog.Content />
|
||||
</div>
|
||||
class='prose prose-sm [&_li_p]:my-0 prose-h2:mt-3 prose-h2:text-lg prose-h2:font-medium prose-p:mb-0 prose-blockquote:font-normal prose-blockquote:text-gray-500 prose-ul:my-0 prose-ul:rounded-lg prose-ul:bg-gray-100 prose-ul:px-4 prose-ul:py-4 prose-ul:pl-7 prose-img:mt-0 prose-img:rounded-lg [&>blockquote>p]:mt-0 [&>ul]:mt-3 [&>ul>li]:my-0 [&>ul>li]:mb-1'
|
||||
set:html={changelog.description}
|
||||
/>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
---
|
||||
import { getAllChangelogs } from '../lib/changelog';
|
||||
import { listChangelog } from '../queries/changelog';
|
||||
import { DateTime } from 'luxon';
|
||||
import AstroIcon from './AstroIcon.astro';
|
||||
const allChangelogs = await getAllChangelogs();
|
||||
const top10Changelogs = allChangelogs.slice(0, 10);
|
||||
|
||||
const changelogs = await listChangelog({ limit: 10 });
|
||||
---
|
||||
|
||||
<div class='border-t bg-white py-6 text-left sm:py-16 sm:text-center'>
|
||||
@@ -17,7 +17,7 @@ const top10Changelogs = allChangelogs.slice(0, 10);
|
||||
Actively Maintained
|
||||
</p>
|
||||
<p
|
||||
class='mb-2 mt-1 text-sm leading-relaxed text-gray-600 sm:my-2 sm:my-5 sm:text-lg'
|
||||
class='mt-1 mb-2 text-sm leading-relaxed text-gray-600 sm:my-5 sm:text-lg'
|
||||
>
|
||||
We are always improving our content, adding new resources and adding
|
||||
features to enhance your learning experience.
|
||||
@@ -25,27 +25,27 @@ const top10Changelogs = allChangelogs.slice(0, 10);
|
||||
|
||||
<div class='relative mt-2 text-left sm:mt-8'>
|
||||
<div
|
||||
class='absolute inset-y-0 left-[120px] hidden w-px -translate-x-[0.5px] translate-x-[5.75px] bg-gray-300 sm:block'
|
||||
class='absolute inset-y-0 left-[120px] hidden w-px translate-x-[5.75px] bg-gray-300 sm:block'
|
||||
>
|
||||
</div>
|
||||
<ul class='relative flex flex-col gap-4 py-4'>
|
||||
{
|
||||
top10Changelogs.map((changelog) => {
|
||||
changelogs.map((changelog) => {
|
||||
const formattedDate = DateTime.fromISO(
|
||||
changelog.frontmatter.date,
|
||||
changelog.createdAt,
|
||||
).toFormat('dd LLL, yyyy');
|
||||
return (
|
||||
<li class='relative'>
|
||||
<a
|
||||
href={`/changelog#${changelog.id}`}
|
||||
href={`/changelog#${changelog._id}`}
|
||||
class='flex flex-col items-start sm:flex-row sm:items-center'
|
||||
>
|
||||
<span class='shrink-0 pr-0 text-right text-sm tracking-wide text-gray-400 sm:w-[120px] sm:pr-4'>
|
||||
{formattedDate}
|
||||
</span>
|
||||
<span class='hidden h-3 w-3 shrink-0 rounded-full bg-gray-300 sm:block' />
|
||||
<span class='text-balance text-base font-medium text-gray-900 sm:pl-8'>
|
||||
{changelog.frontmatter.title}
|
||||
<span class='text-base font-medium text-balance text-gray-900 sm:pl-8'>
|
||||
{changelog.title}
|
||||
</span>
|
||||
</a>
|
||||
</li>
|
||||
@@ -55,7 +55,7 @@ const top10Changelogs = allChangelogs.slice(0, 10);
|
||||
</ul>
|
||||
</div>
|
||||
<div
|
||||
class='mt-2 flex flex-col gap-2 sm:flex-row sm:mt-8 sm:items-center sm:justify-center'
|
||||
class='mt-2 flex flex-col gap-2 sm:mt-8 sm:flex-row sm:items-center sm:justify-center'
|
||||
>
|
||||
<a
|
||||
href='/changelog'
|
||||
@@ -66,7 +66,7 @@ const top10Changelogs = allChangelogs.slice(0, 10);
|
||||
<button
|
||||
data-guest-required
|
||||
data-popup='login-popup'
|
||||
class='flex flex-row items-center gap-2 rounded-lg border border-black bg-white px-4 py-2 text-sm text-black transition-all hover:bg-black hover:text-white sm:rounded-full sm:pl-4 sm:pr-5 sm:text-base'
|
||||
class='flex flex-row items-center gap-2 rounded-lg border border-black bg-white px-4 py-2 text-sm text-black transition-all hover:bg-black hover:text-white sm:rounded-full sm:pr-5 sm:pl-4 sm:text-base'
|
||||
>
|
||||
<AstroIcon icon='bell' class='h-5 w-5' />
|
||||
Subscribe for Notifications
|
||||
|
||||
@@ -1,13 +1,14 @@
|
||||
import { ChevronLeft, ChevronRight } from 'lucide-react';
|
||||
import React, { useState, useEffect, useCallback } from 'react';
|
||||
import type { ChangelogImage } from '../queries/changelog';
|
||||
|
||||
interface ChangelogImagesProps {
|
||||
images: { [key: string]: string };
|
||||
images: ChangelogImage[];
|
||||
}
|
||||
|
||||
const ChangelogImages: React.FC<ChangelogImagesProps> = ({ images }) => {
|
||||
const [enlargedImage, setEnlargedImage] = useState<string | null>(null);
|
||||
const imageArray = Object.entries(images);
|
||||
const imageArray = images.map((image) => [image.title, image.url]);
|
||||
|
||||
const handleImageClick = (src: string) => {
|
||||
setEnlargedImage(src);
|
||||
@@ -63,10 +64,10 @@ const ChangelogImages: React.FC<ChangelogImagesProps> = ({ images }) => {
|
||||
alt={title}
|
||||
className="h-[120px] w-full object-cover object-left-top"
|
||||
/>
|
||||
<span className="absolute group-hover:opacity-0 inset-0 bg-linear-to-b from-transparent to-black/40" />
|
||||
<span className="absolute inset-0 bg-linear-to-b from-transparent to-black/40 group-hover:opacity-0" />
|
||||
|
||||
<div className="absolute font-medium inset-x-0 top-full group-hover:inset-y-0 flex items-center justify-center px-2 text-center text-xs bg-black/50 text-white py-0.5 opacity-0 group-hover:opacity-100 cursor-pointer">
|
||||
<span className='bg-black py-0.5 rounded-sm px-1'>{title}</span>
|
||||
<div className="absolute inset-x-0 top-full flex cursor-pointer items-center justify-center bg-black/50 px-2 py-0.5 text-center text-xs font-medium text-white opacity-0 group-hover:inset-y-0 group-hover:opacity-100">
|
||||
<span className="rounded-sm bg-black px-1 py-0.5">{title}</span>
|
||||
</div>
|
||||
</div>
|
||||
))}
|
||||
@@ -82,7 +83,7 @@ const ChangelogImages: React.FC<ChangelogImagesProps> = ({ images }) => {
|
||||
className="max-h-[90%] max-w-[90%] rounded-xl object-contain"
|
||||
/>
|
||||
<button
|
||||
className="absolute left-4 top-1/2 -translate-y-1/2 transform rounded-full bg-white/50 hover:bg-white/100 p-2"
|
||||
className="absolute top-1/2 left-4 -translate-y-1/2 transform rounded-full bg-white/50 p-2 hover:bg-white/100"
|
||||
onClick={(e) => {
|
||||
e.stopPropagation();
|
||||
handleNavigation('prev');
|
||||
@@ -91,7 +92,7 @@ const ChangelogImages: React.FC<ChangelogImagesProps> = ({ images }) => {
|
||||
<ChevronLeft size={24} />
|
||||
</button>
|
||||
<button
|
||||
className="absolute right-4 top-1/2 -translate-y-1/2 transform rounded-full bg-white/50 hover:bg-white/100 p-2"
|
||||
className="absolute top-1/2 right-4 -translate-y-1/2 transform rounded-full bg-white/50 p-2 hover:bg-white/100"
|
||||
onClick={(e) => {
|
||||
e.stopPropagation();
|
||||
handleNavigation('next');
|
||||
|
||||
@@ -151,6 +151,12 @@ const groups: GroupType[] = [
|
||||
type: 'skill',
|
||||
otherGroups: ['Web Development'],
|
||||
},
|
||||
{
|
||||
title: 'Next.js',
|
||||
link: '/nextjs',
|
||||
type: 'skill',
|
||||
otherGroups: ['Web Development'],
|
||||
},
|
||||
{
|
||||
title: 'Spring Boot',
|
||||
link: '/spring-boot',
|
||||
@@ -408,6 +414,11 @@ const groups: GroupType[] = [
|
||||
link: '/data-analyst',
|
||||
type: 'role',
|
||||
},
|
||||
{
|
||||
title: 'BI Analyst',
|
||||
link: '/bi-analyst',
|
||||
type: 'role',
|
||||
},
|
||||
{
|
||||
title: 'Data Engineer',
|
||||
link: '/data-engineer',
|
||||
|
||||
@@ -1,18 +0,0 @@
|
||||
---
|
||||
title: 'AI Agents, Red Teaming Roadmaps and Community Courses'
|
||||
description: 'New roadmaps for AI Agents and Red Teaming plus access to community-generated AI courses'
|
||||
images:
|
||||
'AI Agents': 'https://assets.roadmap.sh/guest/ai-agents-roadmap-min-poii3.png'
|
||||
'Red Teaming': 'https://assets.roadmap.sh/guest/ai-red-teaming-omyvx.png'
|
||||
'AI Community Courses': 'https://assets.roadmap.sh/guest/ai-community-courses.png'
|
||||
seo:
|
||||
title: 'AI Agents, Red Teaming Roadmaps and Community Courses'
|
||||
description: ''
|
||||
date: 2025-05-12
|
||||
---
|
||||
|
||||
We added new AI roadmaps for AI Agents and Red Teaming and made our AI Tutor better with courses created by the community.
|
||||
|
||||
- We just released a new [AI Agents Roadmap](https://roadmap.sh/ai-agents) that covers how to build, design, and run smart autonomous systems.
|
||||
- There's also a new [Red Teaming Roadmap](https://roadmap.sh/ai-red-teaming) for people who want to learn about testing AI systems for weaknesses and security flaws.
|
||||
- Our [AI Tutor](https://roadmap.sh/ai) now lets you use courses made by other users. You can learn from their content or share your own learning plans.
|
||||
@@ -1,25 +0,0 @@
|
||||
---
|
||||
title: 'AI Engineer Roadmap, Leaderboards, Editor AI, and more'
|
||||
description: 'New AI Engineer Roadmap, New Leaderboards, AI Integration in Editor, and more'
|
||||
images:
|
||||
"AI Engineer Roadmap": "https://assets.roadmap.sh/guest/ai-engineer-roadmap.png"
|
||||
"Refer Others": "https://assets.roadmap.sh/guest/invite-users.png"
|
||||
"Editor AI Integration": "https://assets.roadmap.sh/guest/editor-ai-integration.png"
|
||||
"Project Status": "https://assets.roadmap.sh/guest/project-status.png"
|
||||
"Leaderboards": "https://assets.roadmap.sh/guest/new-leaderboards.png"
|
||||
seo:
|
||||
title: 'AI Engineer Roadmap, Leaderboards, Editor AI, and more'
|
||||
description: ''
|
||||
date: 2024-10-04
|
||||
---
|
||||
|
||||
We have a new AI Engineer roadmap, Contributor leaderboards, AI integration in the editor, and more.
|
||||
|
||||
- [AI Engineer Roadmap](https://roadmap.sh/ai-engineer) is now live
|
||||
- You can now refer others to join roadmap.sh
|
||||
- AI integration [in the editor](https://draw.roadmap.sh) to help you create and edit roadmaps faster
|
||||
- New [Leaderboards](/leaderboard) for contributors and people who refer others
|
||||
- [Projects pages](/frontend/projects) now show the status of each project
|
||||
- Bug fixes and performance improvements
|
||||
|
||||
ML Engineer roadmap and team dashboards are coming up next. Stay tuned!
|
||||
@@ -1,20 +0,0 @@
|
||||
---
|
||||
title: 'AI Quiz Summaries, New Go Roadmap, and YouTube Videos'
|
||||
description: 'Personalized AI summaries for quizzes, completely redrawn Go roadmap, and new YouTube videos for AI features'
|
||||
images:
|
||||
'AI Quiz Summary': 'https://assets.roadmap.sh/guest/quiz-summary-gnwel.png'
|
||||
'New Go Roadmap': 'https://assets.roadmap.sh/guest/roadmapsh_golang-rqzoc.png'
|
||||
'YouTube Videos': 'https://assets.roadmap.sh/guest/youtube-videos-4kygb.jpeg'
|
||||
'Roadmap Editor': 'https://assets.roadmap.sh/guest/ai-inside-editor.png'
|
||||
seo:
|
||||
title: 'AI Quiz Summaries, New Go Roadmap, and YouTube Videos'
|
||||
description: ''
|
||||
date: 2025-07-23
|
||||
---
|
||||
|
||||
We've added new AI-powered features and improved our content to help you learn more effectively.
|
||||
|
||||
- [AI quizzes](/ai/quiz) now provide personalized AI-generated summaries at the end, along with tailored course and guide suggestions to help you continue learning.
|
||||
- The [Go roadmap](/golang) has been completely redrawn with better quality and a more language-focused approach, replacing the previous version that was too web development oriented.
|
||||
- We now have [8 new YouTube videos](https://www.youtube.com/playlist?list=PLkZYeFmDuaN38LRfCSdAkzWVtTXMJt11A) covering all our AI features to help you make the most of them.
|
||||
- [Roadmap editor](/account/roadmaps) now allows you to generate a base roadmap from a prompt.
|
||||
@@ -1,22 +0,0 @@
|
||||
---
|
||||
title: 'AI Roadmaps Improved, Schedule Learning Time'
|
||||
description: 'AI Roadmaps are now deeper and we have added a new feature to schedule learning time'
|
||||
images:
|
||||
"AI Roadmaps Depth": "https://assets.roadmap.sh/guest/3-level-roadmaps-lotx1.png"
|
||||
"Schedule Learning Time": "https://assets.roadmap.sh/guest/schedule-learning-time.png"
|
||||
"Schedule Learning Time Modal": "https://assets.roadmap.sh/guest/schedule-learning-time-2.png"
|
||||
seo:
|
||||
title: 'AI Roadmaps Improved, Schedule Learning Time'
|
||||
description: ''
|
||||
date: 2024-11-18
|
||||
---
|
||||
|
||||
We have improved our AI roadmaps, added a way to schedule learning time, and made some site wide bug fixes and improvements. Here are the details:
|
||||
|
||||
- [AI generated roadmaps](https://roadmap.sh/ai) are now 3 levels deep giving you more detailed information. We have also improved the quality of the generated roadmaps.
|
||||
- Schedule learning time on your calendar for any roadmap. Just click on the "Schedule Learning Time" button and select the time slot you want to block.
|
||||
- You can now dismiss the sticky roadmap progress indicator at the bottom of any roadmap.
|
||||
- We have added some new Project Ideas to our [Frontend Roadmap](/frontend/projects).
|
||||
- Bug fixes and performance improvements
|
||||
|
||||
We have a new Engineering Manager Roadmap coming this week. Stay tuned!
|
||||
@@ -1,18 +0,0 @@
|
||||
---
|
||||
title: 'AI Tutor, C++ and Java Roadmaps'
|
||||
description: 'We just launched our first paid SQL course'
|
||||
images:
|
||||
'AI Tutor': 'https://assets.roadmap.sh/guest/ai-tutor-xwth3.png'
|
||||
'Java Roadmap': 'https://assets.roadmap.sh/guest/new-java-roadmap-t7pkk.png'
|
||||
'C++ Roadmap': 'https://assets.roadmap.sh/guest/new-cpp-roadmap.png'
|
||||
seo:
|
||||
title: 'AI Tutor, C++ and Java Roadmaps'
|
||||
description: ''
|
||||
date: 2025-04-03
|
||||
---
|
||||
|
||||
We have revised the C++ and Java roadmaps and introduced an AI tutor to help you learn anything.
|
||||
|
||||
- We just launched an [AI Tutor](https://roadmap.sh/ai), just give it a topic, pick a difficulty level and it will generate a personalized study plan for you. There is a map view, quizzes an embedded chat to help you along the way.
|
||||
- [C++ roadmap](https://roadmap.sh/cpp) has been revised with improved content
|
||||
- We have also redrawn the [Java roadmap](https://roadmap.sh/java) from scratch, replacing the deprecated items, adding new content and improving the overall structure.
|
||||
@@ -1,23 +0,0 @@
|
||||
---
|
||||
title: 'Revamped roadmaps, AI Tutor, Guides, Roadmaps and more'
|
||||
description: 'Revamped roadmaps, AI Tutor, AI Guides and AI Roadmaps'
|
||||
images:
|
||||
'Roadmap AI Tutor': 'https://assets.roadmap.sh/guest/floating-ai-tutor-n1o4n.png'
|
||||
'AI Tutor on Roadmap': 'https://assets.roadmap.sh/guest/dedicated-roadmap-chat-page-qlbfw.png'
|
||||
'AI Tutor': 'https://assets.roadmap.sh/guest/global-chat-evm4v.png'
|
||||
'Topics AI Tutor': 'https://assets.roadmap.sh/guest/roadmap-ai-tutor-89if2.png'
|
||||
'AI Guides and Roadmaps': 'https://assets.roadmap.sh/guest/ai-guides-roadmaps-lxmm3.jpeg'
|
||||
seo:
|
||||
title: 'Revamped roadmaps, AI Tutor, AI Guides and AI Roadmaps'
|
||||
description: ''
|
||||
date: 2025-06-27
|
||||
---
|
||||
|
||||
We've revamped some of our older roadmaps and added new AI features to help you learn better.
|
||||
|
||||
- Roadmap pages now have a [floating AI Tutor](/frontend) that can help you learn anything while following the roadmap.
|
||||
- There is a new [dedicated AI Tutor page](/frontend/ai) for each roadmap, where you can learn any topic of the roadmap, save history and more.
|
||||
- With [global chat](/ai/chat), you can ask any question about your career, upload your resume, get guidance, tips, roadmap suggestions and more.
|
||||
- Topic pages of roadmaps now have a new [AI Tutor](/frontend) that can help you learn the topic, get quizzed on the topic and more.
|
||||
- Apart from courses, you can now [generate AI Guides and AI Roadmaps](/ai) for any topic.
|
||||
- [MongoDB](/mongodb), [Kubernetes](/kubernetes), [Spring Boot](/spring-boot), [Linux](/linux), [React Native](/react-native) and [GraphQL](/graphql) roadmaps have been updated.
|
||||
@@ -1,21 +0,0 @@
|
||||
---
|
||||
title: 'Cloudflare and ASP.NET Roadmaps, New Dashboard'
|
||||
description: 'We just launched our first paid SQL course'
|
||||
images:
|
||||
'New Dashboard': 'https://assets.roadmap.sh/guest/new-dashboard.png'
|
||||
'Cloudflare Roadmap': 'https://assets.roadmap.sh/guest/cloudflare-roadmap.png'
|
||||
'ASP.NET Roadmap Revised': 'https://assets.roadmap.sh/guest/aspnet-core-revision.png'
|
||||
seo:
|
||||
title: 'Cloudflare and ASP.NET Roadmaps, New Dashboard'
|
||||
description: ''
|
||||
date: 2025-02-21
|
||||
---
|
||||
|
||||
We have launched a new Cloudflare roadmap, revised ASP.NET Core roadmap and introduced a new dashboard design.
|
||||
|
||||
- Brand new [Cloudflare roadmap](https://roadmap.sh/cloudflare) to help you learn Cloudflare
|
||||
- [ASP.NET Core roadmap](https://roadmap.sh/aspnet-core) has been revised with new content
|
||||
- Fresh new dashboard design with improved navigation and performance
|
||||
- Bug fixes and performance improvements
|
||||
|
||||
|
||||
@@ -1,22 +0,0 @@
|
||||
---
|
||||
title: 'DevOps Project Ideas, Team Dashboard, Redis Content'
|
||||
description: 'New Project Ideas for DevOps, Team Dashboard, Redis Content'
|
||||
images:
|
||||
"DevOps Project Ideas": "https://assets.roadmap.sh/guest/devops-project-ideas.png"
|
||||
"Redis Resources": "https://assets.roadmap.sh/guest/redis-resources.png"
|
||||
"Team Dashboard": "https://assets.roadmap.sh/guest/team-dashboard.png"
|
||||
seo:
|
||||
title: 'DevOps Project Ideas, Team Dashboard, Redis Content'
|
||||
description: ''
|
||||
date: 2024-10-16
|
||||
---
|
||||
|
||||
We have added 21 new project ideas to our DevOps roadmap, added content to Redis roadmap and introduced a new team dashboard for teams
|
||||
|
||||
- Practice your skills with [21 newly added DevOps Project Ideas](https://roadmap.sh/devops)
|
||||
- We have a new [Dashboard for teams](https://roadmap.sh/teams) to track their team activity.
|
||||
- [Redis roadmap](https://roadmap.sh/redis) now comes with learning resources.
|
||||
- Watch us [interview Bruno Simon](https://www.youtube.com/watch?v=IQK9T05BsOw) about his journey as a creative developer.
|
||||
- Bug fixes and performance improvements
|
||||
|
||||
ML Engineer roadmap and team dashboards are coming up next. Stay tuned!
|
||||
@@ -1,27 +0,0 @@
|
||||
---
|
||||
title: 'New Dashboard, Leaderboards and Projects'
|
||||
description: 'New leaderboard page showing the most active users'
|
||||
images:
|
||||
"Personal Dashboard": "https://assets.roadmap.sh/guest/personal-dashboard.png"
|
||||
"Projects Page": "https://assets.roadmap.sh/guest/projects-page.png"
|
||||
"Leaderboard": "https://assets.roadmap.sh/guest/leaderboard.png"
|
||||
seo:
|
||||
title: 'Leaderboard Page - roadmap.sh'
|
||||
description: ''
|
||||
date: 2024-09-17
|
||||
---
|
||||
|
||||
Focus for this week was improving the user experience and adding new features to the platform. Here are the highlights:
|
||||
|
||||
- New dashboard for logged-in users
|
||||
- New leaderboard page
|
||||
- Projects page listing all projects
|
||||
- Ability to stop a started project
|
||||
- Frontend and backend content improvements
|
||||
- Bug fixes
|
||||
|
||||
[Dashboard](/) would allow logged-in users to keep track of their bookmarks, learning progress, project and more. You can still visit the [old homepage](https://roadmap.sh/home) once you login.
|
||||
|
||||
We also launched a new [leaderboard page](/leaderboard) showing the most active users, users who completed most projects and more.
|
||||
|
||||
There is also a [new projects page](/projects) where you can see all the projects you have been working on. You can also now stop a started project.
|
||||
@@ -1,21 +0,0 @@
|
||||
---
|
||||
title: 'PHP and System Design Roadmaps, Get Featured'
|
||||
description: 'New PHP Roadmap, System Design Roadmap Revamped, and more'
|
||||
images:
|
||||
"PHP Roadmap": "https://assets.roadmap.sh/guest/php-roadmap.png"
|
||||
"Engineering Manager Roadmap": "https://assets.roadmap.sh/guest/engineering-manager-roadmap.png"
|
||||
"System Design Roadmap": "https://assets.roadmap.sh/guest/system-design.png"
|
||||
"Feature Custom Roadmaps": "https://assets.roadmap.sh/guest/apply-for-feature.png"
|
||||
seo:
|
||||
title: 'PHP and System Design Roadmaps, Get Featured'
|
||||
description: ''
|
||||
date: 2024-12-21
|
||||
---
|
||||
|
||||
We have a new PHP roadmap, System Design roadmap has been revamped. You can also get your custom roadmaps featured.
|
||||
|
||||
- One of the most requested [PHP Roadmap](https://roadmap.sh/php) is now live
|
||||
- We have a new [Engineering Manager](https://roadmap.sh/engineering-manager) roadmap
|
||||
- We have revamped [System Design Roadmap](https://roadmap.sh/system-design)
|
||||
- Get your custom roadmaps featured on the [community roadmaps](/community)
|
||||
- Bug fixes and performance improvements
|
||||
@@ -1,25 +0,0 @@
|
||||
---
|
||||
title: 'Redis Roadmap, Dashboard Changes, Bookmarks'
|
||||
description: 'New leaderboard page showing the most active users'
|
||||
images:
|
||||
"Redis Roadmap": "https://assets.roadmap.sh/guest/redis-roadmap.png"
|
||||
"Bookmarks": "https://assets.roadmap.sh/guest/bookmark-roadmaps.png"
|
||||
"Dashboard": "https://assets.roadmap.sh/guest/dashboard-profile.png"
|
||||
"Cyber Security Content": "https://assets.roadmap.sh/guest/cyber-security-content.png"
|
||||
seo:
|
||||
title: 'Redis Roadmap, Dashboard, Bookmarks - roadmap.sh'
|
||||
description: ''
|
||||
date: 2024-09-23
|
||||
---
|
||||
|
||||
We have a new roadmap, some improvements to dashboard, bookmarks and more.
|
||||
|
||||
- [Redis roadmap](https://roadmap.sh/redis) is now live
|
||||
- Progress and Bookmarks on dashboard are merged into a single section which makes it easy if you have a lot of bookmarks.
|
||||
- Profile section on [dashboard](/) makes it easy to create profile
|
||||
- Roadmaps can now be [bookmarked from any page](/roadmaps) that shows roadmaps.
|
||||
- User profile now shows the projects you are working on.
|
||||
- [Cyber Security roadmap](/cyber-security) is now filled with new content and resources.
|
||||
- Buf fixes and improvements to some team features.
|
||||
|
||||
Next up, we are working on a new AI Engineer roadmap and teams dashboards.
|
||||
@@ -1,19 +0,0 @@
|
||||
---
|
||||
title: "Our first paid course about SQL is live"
|
||||
description: 'We just launched our first paid SQL course'
|
||||
images:
|
||||
"SQL Course": "https://assets.roadmap.sh/guest/course-environment-87jg8.png"
|
||||
"Course Creator Platform": "https://assets.roadmap.sh/guest/course-creator-platform.png"
|
||||
seo:
|
||||
title: 'SQL Course is Live'
|
||||
description: ''
|
||||
date: 2025-02-04
|
||||
---
|
||||
|
||||
After months of work, I am excited to announce our [brand-new SQL course](/courses/sql) designed to help you master SQL with a hands-on, practical approach!
|
||||
|
||||
For the past few months, we have been working on building a course platform that would not only help us deliver high-quality educational content but also sustain the development of roadmap.sh. This SQL course is our first step in that direction.
|
||||
|
||||
The course has been designed with a focus on practical learning. Each topic is accompanied by hands-on exercises, real-world examples, and an integrated coding environment where you can practice what you learn. The AI integration provides personalized learning assistance, helping you grasp concepts better and faster.
|
||||
|
||||
Check out the course at [roadmap.sh/courses/sql](https://roadmap.sh/courses/sql)
|
||||
@@ -1,198 +0,0 @@
|
||||
---
|
||||
title: 'Is Data Science a Good Career? Advice From a Pro'
|
||||
description: 'Is data science a good career choice? Learn from a professional about the benefits, growth potential, and how to thrive in this exciting field.'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/ai-data-scientist/career-path'
|
||||
seo:
|
||||
title: 'Is Data Science a Good Career? Advice From a Pro'
|
||||
description: 'Is data science a good career choice? Learn from a professional about the benefits, growth potential, and how to thrive in this exciting field.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/is-data-science-a-good-career-10j3j.jpg'
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2025-01-28
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Data science is one of the most talked-about career paths today, but is it the right fit for you?
|
||||
|
||||
With [data science](https://roadmap.sh/ai-data-scientist) at the intersection of technology, creativity, and impact, it can be a very appealing role. It definitely promises high and competitive salaries, and the chance to solve real-world problems. Who would say “no” to that?\!
|
||||
|
||||
But is it the right fit for your skills and aspirations?
|
||||
|
||||
In this guide, I’ll help you uncover the answer to that question by understanding the pros and cons of working as a data scientist. I’ll also look at what the data scientists’ salaries are like and the type of skills you’d need to have to succeed at the job.
|
||||
|
||||
Now sit down, relax, and read carefully, because I’m about to help you answer the question of “Is data science a good career for me?”.
|
||||
|
||||
## Pros of a Career in Data Science
|
||||
|
||||

|
||||
|
||||
There are plenty of “pros” when it comes to picking data science as your career, but let’s take a closer look at the main ones.
|
||||
|
||||
### High Demand and Job Security
|
||||
|
||||
The demand for data scientists has grown exponentially over the past few years and shows no signs of slowing down. According to the [U.S. Bureau of Labor Statistics](https://www.bls.gov/ooh/math/data-scientists.htm), the data science job market is projected to grow by 36% from 2023 to 2033, far outpacing the average for other fields.
|
||||
|
||||
This surge is partly due to the “explosion” of artificial intelligence, particularly tools like ChatGPT, in recent years, which have amplified the need for skilled data scientists to handle complex machine learning models and big data analysis.
|
||||
|
||||
### Competitive Salaries
|
||||
|
||||
One of the most appealing aspects of data science positions is the average data scientist’s salary. Reports from Glassdoor and Indeed highlight that data scientists are among the highest-paid professionals in the technology sector. For example, the national average salary for a data scientist in the United States is approximately $120,000 annually, with experienced professionals earning significantly more.
|
||||
|
||||
These salaries are a reflection of the reality: the high demand for [data science skills](https://roadmap.sh/ai-data-scientist/skills) and the technical expertise required for these roles are not easy to come by. What’s even more, companies in high-cost regions, such as Silicon Valley, New York City, and Seattle, tend to offer premium salaries to attract top talent.
|
||||
|
||||
The financial rewards in this field are usually complemented by additional benefits such as opportunities for professional development like research, publishing, patent registration, etc.
|
||||
|
||||
### Intellectual Challenge and Learning Opportunities
|
||||
|
||||
Data scientists work in a field that demands continuous learning and adaptation to emerging technologies. Their field is rooted in solving complex problems through a combination of technical knowledge, creativity, and critical thinking. In other words, they rarely have any time to get bored.
|
||||
|
||||
What makes data science important and intellectually rewarding, is its ability to address real-world problems. Whether it's optimizing healthcare systems, enhancing customer experiences in retail, or predicting financial risks, data science applications have a tangible impact on people.
|
||||
|
||||
This makes data science a good career for individuals who are passionate about lifelong learning and intellectual stimulation.
|
||||
|
||||
### Versatility
|
||||
|
||||
Data science is a good career choice for those who enjoy variety and flexibility. One of the unique aspects of a career in data science is its ability to reach across various industries and domains (I’m talking technology, healthcare, finance, e-commerce, and even entertainment to name a few). This means data scientists can apply their data science skills in almost any sector that generates or relies on data—which is virtually all industries today.
|
||||
|
||||
## Cons of a Career in Data Science
|
||||
|
||||

|
||||
|
||||
The data science job is not without its “cons”, after all, there is no “perfect” role out there. Let’s now review some of the potential challenges that come with the role.
|
||||
|
||||
### Steep Learning Curve
|
||||
|
||||
The steep learning curve in data science is one of the field’s defining characteristics. New data scientists have to develop a deep understanding of technical skills, including proficiency in programming languages like Python, R, and SQL, as well as tools for machine learning and data visualization.
|
||||
|
||||
On top of the already complex subjects to master, data scientists need to find ways of staying current with the constant advancements in the field. This is not optional; it’s a necessity for anyone trying to achieve long-term success in data science. This constant evolution can feel overwhelming, especially for newcomers who are also learning foundational skills.
|
||||
|
||||
Despite these challenges, the steep learning curve can be incredibly rewarding for those who are passionate about solving problems, making data-driven decisions, and contributing to impactful projects.
|
||||
|
||||
While it might sound harsh, it’s important to note that the dedication required to overcome these challenges often results in a fulfilling and (extremely) lucrative career in the world of data science.
|
||||
|
||||
### High Expectations
|
||||
|
||||
Data science positions come with high expectations from organizations. Data scientists usually have the huge responsibility of delivering actionable insights and ensuring these insights are both accurate and timely.
|
||||
|
||||
One of the key challenges data science professionals face is managing the pressure to deliver results under tight deadlines (they’re always tight). Stakeholders often expect instant answers to complex problems, which can lead to unrealistic demands.
|
||||
|
||||
To succeed in such environments, skilled data scientists need strong communication skills to explain their findings and set realistic expectations with stakeholders.
|
||||
|
||||
### Potential Burnout
|
||||
|
||||
The high demand for data science skills usually translates into heavy workloads and tight deadlines, particularly for data scientists working on high-stakes projects (working extra hours is also not an uncommon scenario).
|
||||
|
||||
Data scientists frequently juggle multiple complex responsibilities, such as modeling data, developing machine learning algorithms, and conducting statistical analysis—often within limited timeframes.
|
||||
|
||||
The intense focus required for these tasks, combined with overlapping priorities (and a small dose of poor project management), can lead to mental fatigue and stress.
|
||||
|
||||
Work-life balance can also be a challenge for data scientists giving them another reason for burnout. Combine that with highly active industries, like finance and you have a very hard-to-balance combination.
|
||||
|
||||
To mitigate the risk of burnout, data scientists can try to prioritize setting boundaries, managing workloads effectively (when that’s an option), and advocating for clearer role definitions (better separation of concerns).
|
||||
|
||||
## Skills Required for a Data Science Career
|
||||
|
||||

|
||||
|
||||
To develop a successful career in data science, not all of your [skills](https://roadmap.sh/ai-data-scientist/skills) need to be technical, you also have to look at soft skills, and domain knowledge and to have a mentality of lifelong learning.
|
||||
|
||||
Let’s take a closer look.
|
||||
|
||||
### Technical Skills
|
||||
|
||||
The field of data requires strong foundational technical skills. At the core of these skills is proficiency in programming languages such as Python, R, and SQL. Python is particularly useful and liked for its versatility and extensive libraries, while SQL is essential for querying and managing database systems. R remains a popular choice for statistical analysis and data visualization.
|
||||
|
||||
In terms of frameworks, look into TensorFlow, PyTorch, or Scikit-learn. They’re all crucial for building predictive models and implementing artificial intelligence solutions. Tools like Tableau, Power BI, and Matplotlib are fantastic for creating clear and effective data visualizations, which play a significant role in presenting actionable insights.
|
||||
|
||||
### Soft Skills
|
||||
|
||||
As I said before, it’s not all about technical skills. Data scientists must develop their soft skills, this is key in the field.
|
||||
|
||||
From problem-solving and analytical thinking to developing your communication skills and your ability to collaborate with others. They all work together to help you communicate complex insights and results to other, non-technical stakeholders, which is going to be a key activity in your day-to-day life.
|
||||
|
||||
### Domain Knowledge
|
||||
|
||||
While technical and soft skills are essential, domain knowledge often distinguishes exceptional data scientists from the rest. Understanding industry-specific contexts—such as healthcare regulations, financial market trends, or retail customer behavior—enables data scientists to deliver tailored insights that directly address business needs. If you understand your problem space, you understand the needs of your client and the data you’re dealing with.
|
||||
|
||||
Getting that domain knowledge often involves on-the-job experience, targeted research, or additional certifications.
|
||||
|
||||
### Lifelong Learning
|
||||
|
||||
Finally, if you’re going to be a data scientist, you’ll need to embrace a mindset of continuous learning. The field evolves rapidly, with emerging technologies, tools, and methodologies reshaping best practices. Staying competitive requires consistent professional development through online courses, certifications, conferences, and engagement with the broader data science community.
|
||||
|
||||
Lifelong learning is not just a necessity but also an opportunity to remain excited and engaged in a dynamic and rewarding career.
|
||||
|
||||
## How to determine if data science is right for you?
|
||||
|
||||

|
||||
|
||||
How can you tell if you’ll actually enjoy working as a data scientist? Even after reading this far, you might still have some doubts. So in this section, I’m going to look at some ways in which you can validate that you’ll enjoy the job of a data scientist before you go through the process of becoming one.
|
||||
|
||||
### Self-Assessment Questions
|
||||
|
||||
Figuring out whether data science is the right career path starts with introspection. Ask yourself the following:
|
||||
|
||||
* Do you enjoy working with numbers and solving complex problems?
|
||||
* Are you comfortable learning and applying programming skills like Python and SQL?
|
||||
* Are you excited by the idea of using algorithms to create data-driven insights and actionable recommendations?
|
||||
* Are you willing to commit to continuous learning in a fast-evolving field?
|
||||
|
||||
Take your time while you think about these questions. You don’t even need a full answer, just try to understand how you feel about the idea of each one. If you don’t feel like saying “yes”, then chances are, this might not be the right path for you (and that’s completely fine\!).
|
||||
|
||||
### Start with Small Projects
|
||||
|
||||
If self-assessment is not your thing, another great way to explore your interest in data science is to dive into small, manageable projects. Platforms like Kaggle offer competitions and publicly available data sets, allowing you to practice exploratory data analysis, data visualization, and predictive modeling. Working on these projects can help you build a portfolio, develop confidence in your skills, and validate that you effectively like working this way.
|
||||
|
||||
Online courses and certifications in data analytics, machine learning, and programming languages provide a structured way to build foundational knowledge. Resources like Coursera, edX, and DataCamp offer beginner-friendly paths to learning data science fundamentals.
|
||||
|
||||
### Network and Seek Mentorship
|
||||
|
||||
Another great way to understand if you would like to be a data scientist, is to ask other data scientists. It might sound basic, but it’s a very powerful way because you’ll get insights about the field from the source.
|
||||
|
||||
Networking, while not easy for everyone, is a key component of entering the data science field. Go to data science meetups, webinars, or conferences to expand your network and stay updated on emerging trends and technologies.
|
||||
|
||||
If you’re not into big groups, try seeking mentorship from data scientists already working in the field. This can accelerate your learning curve. Mentors can offer guidance on career planning, project selection, and skill development.
|
||||
|
||||
## Alternative career paths to consider
|
||||
|
||||

|
||||
|
||||
Not everyone who is interested in data science wants to pursue the full spectrum of technical skills or the specific responsibilities of a data scientist. Lucky for you, there are several related career paths that can still scratch your itch for fun and interesting challenges while working within the data ecosystem.
|
||||
|
||||
### Data-Adjacent Roles
|
||||
|
||||
* **Data Analyst**: If you enjoy working with data but prefer focusing on interpreting and visualizing it to inform business decisions, a data analyst role might be for you. Data analysts primarily work on identifying trends and providing actionable recommendations without diving deeply into machine learning or predictive modeling.
|
||||
* **Data Engineer**: If you’re more inclined toward building the infrastructure that makes data science possible, consider becoming a data engineer. These data professionals design, build, and maintain data pipelines, ensuring the accessibility and reliability of large data sets for analysis. The role requires expertise in database systems, data structures, and programming.
|
||||
|
||||
### Related Fields
|
||||
|
||||
* **Software Engineering**: For those who enjoy coding and software development but want to remain close to data-related projects, software engineering offers opportunities to build tools, applications, and systems that support data analysis and visualization.
|
||||
* **Cybersecurity**: With the increasing emphasis on data privacy and security, cybersecurity professionals play a critical role in protecting sensitive information. This field combines technical knowledge with policy enforcement, making it appealing to those interested in data protection and regulatory compliance.
|
||||
|
||||
### Non-Technical Roles in the Data Ecosystem
|
||||
|
||||
* **Data Governance**: If instead of transforming data and getting insights, you’d like to focus more on how the data is governed (accessed, controlled, cataloged, etc), then this might be the role for you. This role is essential for ensuring that an organization’s data assets are used effectively and responsibly.
|
||||
* **Data Privacy Office**: In a similar vein to a data governance officer, the data privacy officer cares for the actual privacy of the data. With the rise of AI, data is more relevant than ever, and controlling that you comply with regulations like GDPR and CCPA, is critical for organizations. This role focuses on data privacy strategies, audits, and risk management, making it an excellent fit for those interested in the legal and ethical aspects of data.
|
||||
|
||||
## Next steps
|
||||
|
||||

|
||||
|
||||
Data science is a promising career path offering high demand, competitive salaries, and multiple opportunities across various industries. Its ability to address real-world problems, combined with the intellectual challenge it presents, makes it an attractive choice for many. However, it also makes it a very difficult and taxing profession for those who don’t enjoy this type of challenge.
|
||||
|
||||
There are many potential next steps for you to take and answer the question of “Is data science a good career?”.
|
||||
|
||||
For example, you can reflect on your interests and strengths. Ask yourself whether or not you enjoy problem-solving, working with data sets, and learning new technologies. Use this reflection to determine if data science aligns with your career goals.
|
||||
|
||||
You can also consume resources like the [AI/Data Scientist roadmap](https://roadmap.sh/ai-data-scientist) and the [Data Analyst roadmap](https://roadmap.sh/data-analyst), as they offer a clear progression for developing essential skills, so check them out. These tools can help you identify which areas to focus on based on your current expertise and interests.
|
||||
|
||||
In the end, just remember: data science is rapidly evolving so make sure to stay engaged by reading research papers, following industry blogs, or attending conferences. Anything you can do will help, just figure out what works for you and keep doing it.
|
||||
@@ -1,200 +0,0 @@
|
||||
---
|
||||
title: "Data Science Lifecycle 101: A Beginners' Ultimate Guide"
|
||||
description: 'Discover the Data Science Lifecycle step-by-step: Learn key phases, tools, and techniques in this beginner-friendly guide.'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/ai-data-scientist/career-path'
|
||||
seo:
|
||||
title: "Data Science Lifecycle 101: A Beginners' Ultimate Guide"
|
||||
description: 'Discover the Data Science Lifecycle step-by-step: Learn key phases, tools, and techniques in this beginner-friendly guide.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-lifecycle-eib3s.jpg'
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2025-01-29
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Developing a data science project, from beginning to production is not a trivial task. It involves so many steps and so many complex tasks, that without some guardrails, releasing to production becomes ten times harder.
|
||||
|
||||
Here’s where the data science lifecycle comes into play. It brings a structured approach so that [data scientists](https://roadmap.sh/ai-data-scientist), data analysts, and others can move forward together from raw data to actionable insights.
|
||||
|
||||
In this guide, we’ll cover everything you need to know about the data science lifecycle, its many variants, and how to pick the right one for your project.
|
||||
|
||||
So let’s get going\!
|
||||
|
||||
## Core Concepts of a Lifecycle
|
||||
|
||||

|
||||
|
||||
To fully understand the concept of the lifecycle, we have to look at the core concepts inside this framework, and how they contribute to the delivery of a successful data science project.
|
||||
|
||||
### Problem Definition
|
||||
|
||||
Every data science project begins with a clear definition of the problem to be solved. This involves collaborating with key stakeholders to identify objectives and desired outcomes. Data scientists must understand the context and scope of the project to ensure that the goals align with business or research needs.
|
||||
|
||||
### Data Collection
|
||||
|
||||
In the data collection phase, data scientists and data engineers work together and gather relevant data from diverse data sources. This includes both structured and unstructured data, such as historical records, new data, or data streams.
|
||||
|
||||
The process ensures the integration of all pertinent data, creating a robust dataset for the following stages. Data acquisition tools and strategies play a critical role in this phase.
|
||||
|
||||
### Data Preparation
|
||||
|
||||
This stage addresses the quality of raw data by cleaning and organizing it for analysis. Tasks such as treating inaccurate data, handling missing values, and converting raw data into usable formats are central to this stage. This stage prepares the data for further and more detailed analysis.
|
||||
|
||||
### Exploratory Data Analysis (EDA)
|
||||
|
||||
The exploratory data analysis stage is where the “data processing” happens. This stage focuses on uncovering patterns, trends, and relationships within the data. Through data visualization techniques such as bar graphs and statistical models, data scientists perform a thorough data analysis and gain insights into the data’s structure and characteristics.
|
||||
|
||||
Like every stage so far, this one lays the foundation for the upcoming stages. In this particular case, after performing a detailed EDA, data scientists have a much better understanding of the data they have to work with, and a pretty good idea of what they can do with it now.
|
||||
|
||||
### Model Building and Evaluation
|
||||
|
||||
The model building phase involves developing predictive or machine learning models tailored to the defined problem. Data scientists experiment with various machine learning algorithms and statistical models to determine the best approach. Here’s where data modeling happens, bridging the insights gained during the exploratory data analysis (EDA) phase with actionable predictions and outcomes used in the deployment phase.
|
||||
|
||||
Model evaluation follows, where the performance and accuracy of these models are tested to ensure reliability.
|
||||
|
||||
### Deployment and Monitoring
|
||||
|
||||
The final stage of this generic data science lifecycle involves deploying the model into a production environment. Here, data scientists, machine learning engineers, and quality assurance teams ensure that the model operates effectively within existing software systems.
|
||||
|
||||
After this stage, continuous monitoring and maintenance are essential to address new data or changing conditions, which can impact the performance and accuracy of the model.
|
||||
|
||||
## Exploring 6 Popular Lifecycle Variants
|
||||
|
||||

|
||||
|
||||
The data science lifecycle offers various frameworks tailored to specific needs and contexts. Below, we explore six prominent variants:
|
||||
|
||||
### CRISP-DM (Cross Industry Standard Process for Data Mining)
|
||||
|
||||
CRISP-DM is one of the most widely used frameworks in data science projects, especially within business contexts.
|
||||
|
||||
It organizes the lifecycle into six stages: Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, and Deployment.
|
||||
|
||||
This iterative approach allows teams to revisit and refine previous steps as new insights emerge. CRISP-DM is ideal for projects where aligning technical efforts with business goals is very important.
|
||||
|
||||
**Example use case**: A retail company wants to improve customer segmentation for targeted marketing campaigns. Using CRISP-DM, the team starts with business understanding to define segmentation goals, gathers transaction and demographic data, prepares and cleans it, builds clustering models, evaluates their performance, and deploys the best model to group customers for personalized offers.
|
||||
|
||||
### KDD (Knowledge Discovery in Databases)
|
||||
|
||||
The KDD process focuses on extracting useful knowledge from large datasets. Its stages include Selection, Preprocessing, Transformation, Data Mining, and Interpretation/Evaluation.
|
||||
|
||||
KDD emphasizes the academic and research-oriented aspects of data science, making it an ideal choice for experimental or exploratory projects in scientific domains. It offers a systematic approach to discovering patterns and insights in complex datasets.
|
||||
|
||||
**Example use case:** A research institute analyzes satellite data to study climate patterns. They follow KDD by selecting relevant datasets, preprocessing to remove noise, transforming data to highlight seasonal trends, applying data mining techniques to identify long-term climate changes, and interpreting results to publish findings.
|
||||
|
||||
### Data Analytics Lifecycle
|
||||
|
||||
This specific data science lifecycle is tailored for enterprise-level projects that prioritize actionable insights. It’s composed of six stages: Discovery, Data Preparation, Model Planning, Model Building, Communicating Results, and Operationalizing.
|
||||
|
||||
The framework’s strengths lie in its alignment with business objectives and readiness for model deployment, making it ideal for organizations seeking to integrate data-driven solutions into their operations.
|
||||
|
||||
**Example use case:** A financial institution uses the Data Analytics Lifecycle to detect fraudulent transactions. They discover patterns in historical transaction data, prepare it by cleaning and normalizing, plan predictive models, build and test them, communicate results to fraud prevention teams, and operationalize the model to monitor real-time transactions.
|
||||
|
||||
### SEMMA (Sample, Explore, Modify, Model, Assess)
|
||||
|
||||
SEMMA is a straightforward and tool-centric framework developed by SAS. It focuses on sampling data, exploring it for patterns, modifying it for analysis, modeling it for predictions, and assessing the outcomes.
|
||||
|
||||
This lifecycle is particularly useful for workflows involving specific analytics tools. Its simplicity and strong emphasis on data exploration make it an excellent choice for teams prioritizing rapid insights.
|
||||
|
||||
**Example use case:** A healthcare organization predicts patient readmission rates using SEMMA. They sample data from hospital records, explore patient histories for trends, modify features like patient age and diagnoses, build machine learning models, and assess their accuracy to choose the most effective predictor.
|
||||
|
||||
### Team Data Science Process (TDSP)
|
||||
|
||||
TDSP offers a collaborative and agile framework that organizes the lifecycle into four key stages: Business Understanding, Data Acquisition, Modeling, and Deployment.
|
||||
|
||||
Designed with team-based workflows in mind, TDSP emphasizes iterative progress and adaptability, ensuring that projects align with business needs while remaining flexible to changes. It’s well-suited for scenarios requiring close collaboration among data scientists, engineers, and stakeholders.
|
||||
|
||||
**Example use case:** A logistics company improves delivery route optimization. Using TDSP, the team collaborates to understand business goals, acquires data from GPS and traffic systems, develops routing models, and deploys them to dynamically suggest the fastest delivery routes.
|
||||
|
||||
### MLOps Lifecycle
|
||||
|
||||
MLOps focuses specifically on machine learning operations and production environments. Its stages include Data Engineering, Model Development, Model Deployment, and Monitoring.
|
||||
|
||||
This lifecycle is essential for projects involving large-scale machine learning systems that demand high scalability and automation.
|
||||
|
||||
MLOps integrates seamlessly with continuous integration and delivery pipelines, ensuring that deployed models remain effective and relevant as new data is introduced.
|
||||
|
||||
Each of these frameworks has its own strengths and is suited to different types of data science operations.
|
||||
|
||||
**Example use case:** An e-commerce platform deploys a recommendation engine using MLOps. They engineer data pipelines from user activity logs, develop collaborative filtering models, deploy them on the website, and monitor their performance to retrain models when new user data is added.
|
||||
|
||||
## How to Choose the Right Data Science Lifecycle
|
||||
|
||||

|
||||
|
||||
Determining the most suitable data science lifecycle for your data science project requires a systematic approach. After all, not all lifecycles are best suited for all situations.
|
||||
|
||||
You can follow these steps to identify the framework that aligns best with your goals and resources:
|
||||
|
||||
1. **Define your objectives:** Clearly identify the goals of your project. Are you solving a business problem, conducting academic research, or deploying a machine learning model? Understanding the end objective will narrow down your choices.
|
||||
2. **Assess project complexity:** Evaluate the scope and intricacy of your project. Simple projects may benefit from streamlined frameworks like SEMMA, while complex projects with iterative requirements might need CRISP-DM or TDSP.
|
||||
3. **Evaluate your team composition:** Consider the expertise within your team. A team with strong machine learning skills may benefit from MLOps, whereas a diverse team with varying levels of experience might prefer a more general framework like CRISP-DM.
|
||||
4. **Analyze industry and domain requirements:** Different industries may have unique needs. For example, business-driven projects often align with the Data Analytics Lifecycle, while academic projects might find KDD more suitable.
|
||||
5. **Examine available tools and resources:** Ensure that the tools, software, and infrastructure you have access to are compatible with your chosen lifecycle. Frameworks like SEMMA may require specific tools such as SAS.
|
||||
6. **Match to key stakeholder needs:** Align the lifecycle with the expectations and requirements of stakeholders. A collaborative framework like TDSP can be ideal for projects needing frequent input and iteration with business partners.
|
||||
7. **Run a trial phase:** If possible, test a smaller project or a subset of your current project with the selected framework. This will help you assess its effectiveness and make adjustments as needed.
|
||||
|
||||
Follow these steps and you can identify the lifecycle that not only suits your project but also ensures that your data science process is efficient and productive. Each project is unique, so tailoring the lifecycle to its specific demands is critical to success.
|
||||
|
||||
## Generic Framework for Beginners
|
||||
|
||||

|
||||
|
||||
While there are many different data science lifecycles and ways to tackle data science projects, if you’re just getting started and you’re trying to push your first project into production, relying on a beginner-friendly lifecycle might be a better idea.
|
||||
|
||||
A generic framework for beginners in data science simplifies the lifecycle into manageable steps, making it easier to understand and implement. You can follow these steps to define your new framework:
|
||||
|
||||
### 1\. Define the problem
|
||||
|
||||

|
||||
|
||||
Start by clearly identifying the problem you aim to solve. Consider the objectives and outcomes you want to achieve, and ensure these are aligned with the needs of any stakeholder. This will help focus your efforts during development and set the right expectations with your stakeholders.
|
||||
|
||||
### 2\. Collect and clean data
|
||||
|
||||

|
||||
|
||||
Gather data from reliable and relevant sources. During this stage, focus on ensuring data quality by treating inaccurate data, filling in missing values, validating and removing potential data biases and finally, converting raw data into usable formats.
|
||||
|
||||
### 3\. Analyze and visualize
|
||||
|
||||

|
||||
|
||||
Explore the data to uncover patterns, trends, and insights. Use simple data visualization techniques such as bar graphs and scatter plots, along with basic statistical methods, to gain a deeper understanding of the dataset’s structure and variables.
|
||||
|
||||
### 4\. Build and evaluate a model
|
||||
|
||||

|
||||
|
||||
Develop a basic predictive model using accessible machine learning or statistical tools. Test the model’s performance to ensure it meets the objectives defined earlier during step 1\. For beginners, tools with user-friendly interfaces like Python libraries or Excel can be highly effective.
|
||||
|
||||
### 5\. Share results and deploy
|
||||
|
||||

|
||||
|
||||
Present your findings to stakeholders in a clear and actionable format. If applicable, deploy the model into a small-scale production environment to observe its impact and gather feedback for further improvement.
|
||||
|
||||
**Tips for small projects:** Start with a problem you’re familiar with, such as analyzing personal expenses or predicting simple outcomes. Focus on learning the process rather than achieving perfect results. Use open-source tools and resources to experiment and build your confidence.
|
||||
|
||||
Use this framework if this is your first data science project, evaluate your results, and most importantly, reflect on your experience.
|
||||
|
||||
Take those insights into your next project and decide if for that one you would actually benefit from using one of the predefined standard lifecycles mentioned above.
|
||||
|
||||
## Conclusion
|
||||
|
||||
The data science lifecycle is a cornerstone of modern data science. By understanding its stages and principles, professionals can navigate the complexities of data science projects with confidence.
|
||||
|
||||
Regardless of what you’re doing, dealing with unstructured data, creating models, or deploying machine learning algorithms, the lifecycle provides a roadmap for success.
|
||||
|
||||
As data science experts and teams continue to explore and refine their approaches, the lifecycle framework remains a key tool for achieving excellence in any and all operations.
|
||||
|
||||
Finally, remember that if you’re interested in developing your data science career, you have our [data scientist](https://roadmap.sh/ai-data-scientist) and [data analyst](https://roadmap.sh/data-analyst) roadmaps at your disposal. These roadmaps will help you focus your learning time on the really important and relevant topics.
|
||||
@@ -1,197 +0,0 @@
|
||||
---
|
||||
title: 'Top 11 Data Science Skills to Master in @currentYear@'
|
||||
description: 'Looking to excel in data science? Learn the must-have skills for @currentYear@ with our expert guide and advance your data science career.'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/ai-data-scientist/skills'
|
||||
seo:
|
||||
title: 'Top 11 Data Science Skills to Master in @currentYear@'
|
||||
description: 'Looking to excel in data science? Learn the must-have skills for @currentYear@ with our expert guide and advance your data science career.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-skills-to-master-q36qn.jpg'
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2025-01-28
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Data science is becoming more relevant as a field and profession by the day. Part of this constant change is the mind-blowing speed at which AI is evolving these days. Every day a new model is released, every week a new product is built around it, and every month OpenAI releases an earth-shattering change that pushes the field even further than before.
|
||||
|
||||
Data scientists sit at the core of that progress, but what does it take to master the profession?
|
||||
|
||||
Mastering the essential data scientist skills goes beyond just solving complex problems. It includes the ability to handle data workflows, build machine learning models, and interpret data trends effectively.
|
||||
|
||||
In this guide, we'll explore the top 10 skills that future data scientists must work on to shine brighter than the rest in 2025, setting a foundation for long-term success.
|
||||
|
||||
These are the data scientist skills covered in the article:
|
||||
|
||||
* Programming proficiency with **Python, R, and SQL**
|
||||
* Data manipulation and analysis, including **data wrangling** and **exploratory data analysis**
|
||||
* Mastery of **machine learning** and **AI techniques**
|
||||
* Strong statistical and **mathematical** **foundations**
|
||||
* Familiarity with **big data technologies**
|
||||
* Data engineering for infrastructure and **ETL pipelines**
|
||||
* Expertise in **data visualization** with tools like **Plotly** and **D3.js**
|
||||
* **Domain knowledge** for aligning data science projects with business goals
|
||||
* **Soft skills** for communication, collaboration, and creativity
|
||||
* **Feature engineering** and selection for **model optimization**.
|
||||
* Staying current with trends like **MLOps** and **Generative AI.**
|
||||
|
||||
## **Understanding Data Science**
|
||||
|
||||
[Data science](https://roadmap.sh/ai-data-scientist) is an interdisciplinary field that combines multiple disciplines to make sense of data and drive actionable insights. It integrates programming, statistical analysis, and domain knowledge to uncover patterns and trends in both structured and unstructured data. This powerful combination enables data professionals to solve a variety of challenges, such as:
|
||||
|
||||
* Building predictive models to forecast sales or identify customer churn.
|
||||
* Developing optimization techniques to streamline supply chains or allocate resources more effectively.
|
||||
* Leveraging automation and artificial intelligence to create personalized recommendations or detect fraudulent activity in massive datasets.
|
||||
|
||||
At its core, data science empowers organizations to turn raw data into actionable insights. By interpreting data effectively and applying statistical models, data scientists support data-driven decision-making, ensuring businesses maintain a competitive edge.
|
||||
|
||||
The data science field requires a unique mix of technical skills, analytical prowess, and creativity to handle the vast array of complex data sets encountered in real-world scenarios. In other words, being a data scientist is not for everyone.
|
||||
|
||||
**1\. Programming Proficiency**
|
||||
|
||||

|
||||
|
||||
Programming remains a cornerstone of the data science field, forming the foundation for nearly every task in data science projects. Mastery of programming languages like Python, R, and SQL is crucial for aspiring data scientists to handle data workflows effectively.
|
||||
|
||||
Python is the undisputed leader in data science, thanks to its extensive libraries and frameworks. Pandas, NumPy, and Scikit-learn are essential for tasks ranging from data wrangling and numerical analysis to building machine learning models. Deep learning tools such as TensorFlow and PyTorch make Python indispensable for tackling advanced challenges like developing artificial neural networks for image recognition and natural language processing (NLP).
|
||||
|
||||
R excels in statistical analysis and visualization. Its specialized libraries, like ggplot2 for data visualization and caret for machine learning models, make it a preferred choice for academics and data analysis tasks that require interpreting data trends and creating statistical models.
|
||||
|
||||
SQL is the backbone of database management, which is essential for extracting, querying, and preparing data from structured databases. A strong command of SQL allows data professionals to manage massive datasets efficiently and ensure smooth integration with analytical tools.
|
||||
|
||||
## **2\. Data Manipulation and Analysis**
|
||||
|
||||

|
||||
|
||||
The ability to manipulate and analyze data lies at the heart of data science skills. These tasks involve transforming raw data into a format suitable for analysis and extracting insights through statistical concepts and exploratory data analysis (EDA).
|
||||
|
||||
Data wrangling is a critical skill for cleaning and preparing raw data, addressing missing values, and reshaping complex data sets. For example, consider a dataset containing customer transaction records with incomplete information. Using tools like Pandas in Python, a data scientist can identify missing values, impute or drop them as appropriate, and restructure the data to focus on specific variables like transaction frequency or total purchase amounts. This process ensures the dataset is ready for meaningful analysis.
|
||||
|
||||
Tools like Pandas, PySpark, and Dask are invaluable for handling unstructured data or working with massive datasets efficiently. These tools allow data scientists to transform complex data sets into manageable and analyzable forms, which is foundational for building machine learning models or conducting advanced statistical analysis.
|
||||
|
||||
Performing exploratory data analysis allows data scientists to identify patterns, correlations, and anomalies within structured data. Visualization libraries like Matplotlib and Seaborn, combined with Python scripts, play a significant role in understanding data insights before building predictive models or statistical models.
|
||||
|
||||
**3\. Machine Learning and AI**
|
||||
|
||||

|
||||
|
||||
Machine learning is a driving force in the data science industry, enabling data-driven decisions across sectors and revolutionizing how organizations interpret data and make predictions. Mastering machine learning algorithms and frameworks are among the top data science skills for aspiring data scientists who wish to excel in analyzing data and creating impactful solutions.
|
||||
|
||||
Data scientists commonly tackle supervised learning tasks, such as predicting housing prices through regression models or identifying fraudulent transactions with classification algorithms. For example, using Scikit-learn, a data scientist can train a decision tree to categorize customer complaints into predefined categories for better issue resolution. Additionally, unsupervised techniques like clustering are applied in market segmentation to group customers based on purchasing patterns, helping businesses make data-driven decisions.
|
||||
|
||||
Deep learning represents the cutting edge of artificial intelligence, utilizing artificial neural networks to manage unstructured data and solve highly complex problems. Frameworks like TensorFlow and PyTorch are essential tools for developing advanced solutions, such as NLP models for chatbot interactions or generative AI for creating realistic images. These tools empower data scientists to push the boundaries of innovation and unlock actionable insights from vast and complex datasets.
|
||||
|
||||
## **4\. Statistical and Mathematical Foundations**
|
||||
|
||||

|
||||
|
||||
Statistical concepts and mathematical skills form the backbone of building robust data models and interpreting data insights. These foundational skills are indispensable for anyone aiming to succeed in the data science field.
|
||||
|
||||
Probability theory and hypothesis testing play a vital role in understanding uncertainty in data workflows. For instance, a data scientist might use hypothesis testing to evaluate whether a new marketing strategy leads to higher sales compared to the current approach, ensuring data-driven decision-making.
|
||||
|
||||
Linear algebra and calculus are crucial for developing and optimizing machine learning algorithms. Techniques like matrix decomposition and gradient descent are used to train neural networks and enhance their predictive accuracy. These mathematical tools are the engine behind many advanced algorithms, making them essential data scientist skills.
|
||||
|
||||
Advanced statistical analysis, including A/B testing and Bayesian inference, helps validate predictions and understand relationships within complex datasets. For example, A/B testing can determine which website design yields better user engagement, providing actionable insights to businesses.
|
||||
|
||||
## **5\. Big Data Technologies**
|
||||
|
||||

|
||||
|
||||
While big data skills are secondary for most data scientists, understanding big data technologies enhances their ability to handle massive datasets efficiently. Familiarity with tools like Apache Spark and Hadoop allows data scientists to process and analyze distributed data, which is especially important for projects involving millions of records. For example, Apache Spark can be used to calculate real-time metrics on user behavior across e-commerce platforms, enabling businesses to personalize experiences dynamically.
|
||||
|
||||
Cloud computing skills, including proficiency with platforms like AWS or GCP, are also valuable for deploying machine learning projects at scale. A data scientist working with GCP's BigQuery can query massive datasets in seconds, facilitating faster insights for time-sensitive decisions. These technologies, while not the core of a data scientist's responsibilities, are crucial for ensuring scalability and efficiency in data workflows.
|
||||
|
||||
## **6\. Data Engineering**
|
||||
|
||||

|
||||
|
||||
Data engineering complements data science by creating the infrastructure required to analyze data effectively. This skill set ensures that data flows seamlessly through pipelines, enabling analysis and decision-making.
|
||||
|
||||
Designing ETL (Extract, Transform, Load) pipelines is a critical part of data engineering. For instance, a data engineer might create a pipeline to collect raw sales data from multiple sources, transform it by standardizing formats and handling missing values, and load it into a database for further analysis. These workflows are the backbone of data preparation.
|
||||
|
||||
Using tools like Apache Airflow, those workflows can be streamlined, while managing real-time data streaming using Kafka ensures that real-time data—such as social media feeds or IoT sensor data—is processed without delay. For example, a Kafka pipeline could ingest weather data to update forecasts in real-time.
|
||||
|
||||
Finally, storing and querying complex data sets in cloud computing with tools like Snowflake or BigQuery allows data scientists to interact with massive datasets effortlessly.
|
||||
|
||||
These platforms support scalable storage and high-performance queries, enabling faster analysis and actionable insights.
|
||||
|
||||
## **7\. Data Visualization**
|
||||
|
||||

|
||||
|
||||
Data visualization is a cornerstone of the data science field, as it enables data professionals to present data and communicate findings effectively. While traditional tools like Tableau and Power BI are widely used, aspiring data scientists should prioritize programming-based tools like Plotly and D3.js for greater flexibility and customization.
|
||||
|
||||
For example, using Plotly, a data scientist can create an interactive dashboard to visualize customer purchase trends over time, allowing stakeholders to explore the data dynamically. Similarly, D3.js offers unparalleled control for designing custom visualizations, such as heatmaps or network graphs, that convey complex relationships in a visually compelling manner.
|
||||
|
||||
Applying storytelling techniques further enhances the impact of visualizations. By weaving data insights into a narrative, data scientists can ensure their findings resonate with stakeholders and drive actionable decisions. For instance, a well-crafted story supported by visuals can explain how seasonal demand patterns affect inventory management, bridging the gap between technical analysis and strategic planning.
|
||||
|
||||
## **8\. Business and Domain Knowledge**
|
||||
|
||||

|
||||
|
||||
Domain knowledge enhances the relevance of data science projects by aligning them with organizational goals and addressing unique industry-specific challenges. Understanding the context in which data is applied allows data professionals to make their analysis more impactful and actionable.
|
||||
|
||||
For example, in the finance industry, a data scientist with domain expertise can design predictive models that assess credit risk by analyzing complex data sets of customer transactions, income, and past credit behavior. These models enable financial institutions to make data-driven decisions about lending policies.
|
||||
|
||||
In healthcare, domain knowledge allows data scientists to interpret medical data effectively, such as identifying trends in patient outcomes based on treatment history. By leveraging data models tailored to clinical needs, data professionals can help improve patient care and operational efficiency in hospitals.
|
||||
|
||||
This alignment ensures that insights are not only technically robust but also directly applicable to solving real-world problems, making domain knowledge an indispensable skill for data professionals seeking to maximize their impact.
|
||||
|
||||
## **9\. Soft Skills**
|
||||
|
||||

|
||||
|
||||
Soft skills are as essential as technical skills in the data science field, bridging the gap between complex data analysis and practical implementation. These skills enhance a data scientist's ability to communicate findings, collaborate with diverse teams, and approach challenges with innovative solutions.
|
||||
|
||||
**Communication** is critical for translating data insights into actionable strategies. For example, a data scientist might present the results of an exploratory data analysis to marketing executives, breaking down statistical models into simple, actionable insights that drive campaign strategies. The ability to clearly interpret data ensures that stakeholders understand and trust the findings.
|
||||
|
||||
**Collaboration** is equally vital, as data science projects often involve cross-functional teams. For instance, a data scientist might work closely with software engineers to integrate machine learning models into a production environment or partner with domain experts to ensure that data-driven decisions align with business objectives. Effective teamwork ensures seamless data workflows and successful project outcomes.
|
||||
|
||||
**Creativity** allows data scientists to find innovative ways to address complex problems. A creative data scientist might devise a novel approach to handling unstructured data, such as using natural language processing (NLP) techniques to extract insights from customer reviews, providing actionable insights that improve product development.
|
||||
|
||||
These critical soft skills complement technical expertise, making data professionals indispensable contributors to their organizations.
|
||||
|
||||
## 10\. Feature engineering and selection for model optimization
|
||||
|
||||

|
||||
|
||||
For machine learning models to interpret and use any type of data, that data needs to be turned into features. And that is where feature engineering and selection comes into play. These are two critical steps in the data science workflow because they directly influence the performance and accuracy of the models. If you think about it, the better the model understands what data to focus on, the better it'll perform.
|
||||
|
||||
These processes involve creating, selecting, and transforming raw data into useful features loaded with meaning that help represent the underlying problem for the model.
|
||||
|
||||
For example, imagine building a model to predict house prices. Raw data might include information like the size of the house in square meters, the number of rooms, and the year it was built. Through feature engineering, a data scientist could create new features, such as "price per square meter" or "age of the house," which make the data more informative for the model. These features can highlight trends that a model might otherwise miss.
|
||||
|
||||
Feature selection, on the other hand, focuses on optimizing the use and dependency on features by identifying the most relevant ones and removing the redundant or irrelevant features. For example, let's consider a retail scenario where a model is predicting customer churn, here it might benefit from focusing on features like "purchase frequency" and "customer feedback sentiment", while ignoring less impactful ones like "the time of day purchases are made". This helps to avoid the model getting overwhelmed by noise, improving both its efficiency and accuracy.
|
||||
|
||||
If you're looking to improve your data science game, then focusing on feature engineering and selection can definitely have that effect.
|
||||
|
||||
## 11\. Staying Current
|
||||
|
||||

|
||||
|
||||
The data science field evolves at an unprecedented pace, driven by advancements in artificial intelligence, machine learning, and data technologies. Staying current with emerging trends is essential for maintaining a competitive edge and excelling in the industry.
|
||||
|
||||
Joining **data science communities**, such as forums or online groups, provides a platform for exchanging ideas, discussing challenges, and learning from peers. For instance, platforms like Kaggle or GitHub allow aspiring data scientists to collaborate on data science projects and gain exposure to real-world applications.
|
||||
|
||||
Attending **data science conferences** is another effective way to stay informed. Events like NeurIPS, Strata Data Conference, or PyData showcase cutting-edge research and practical case studies, offering insights into the latest advancements in machine learning models, big data technologies, and cloud computing tools.
|
||||
|
||||
Engaging in **open-source projects** not only sharpens technical skills but also helps data professionals contribute to the broader data science community. For example, contributing to an open-source MLOps framework might provide invaluable experience in deploying and monitoring machine learning pipelines.
|
||||
|
||||
Embracing trends like **MLOps** for operationalizing machine learning, **AutoML** for automating model selection, and **Generative AI** for creating synthetic data ensures that data scientists remain at the forefront of innovation. These emerging technologies are reshaping the data science field, making continuous learning a non-negotiable aspect of career growth.
|
||||
|
||||
**Summary**
|
||||
|
||||
Mastering these essential data scientist skills—from programming languages and machine learning skills to interpreting data insights and statistical models—will future-proof your [career path in data science](https://roadmap.sh/ai-data-scientist/career-path). These include the core skills of data manipulation, statistical analysis, and data visualization, all of which are central to the data science field.
|
||||
|
||||
In addition, while big data technologies and data engineering skills are not the central focus of a data scientist's role, they serve as valuable, data science-adjacent competencies. Familiarity with big data tools like Apache Spark and cloud computing platforms can enhance scalability and efficiency in handling massive datasets, while data engineering knowledge helps create robust pipelines to support analysis. By building expertise in these areas and maintaining adaptability, you can excel in this dynamic, data-driven industry.
|
||||
|
||||
Check out our [data science roadmap](https://roadmap.sh/ai-data-scientist) next to discover what your potential learning path could look like in this role.
|
||||
|
||||
@@ -1,313 +0,0 @@
|
||||
---
|
||||
title: 'Data Science Tools: Our Top 11 Recommendations for @currentYear@'
|
||||
description: 'Master your data science projects with our top 11 tools for 2025! Discover the best platforms for data analysis, visualization, and machine learning.'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/ai-data-scientist/tools'
|
||||
seo:
|
||||
title: 'Data Science Tools: Our Top 11 Recommendations for @currentYear@'
|
||||
description: 'Master your data science projects with our top 11 tools for 2025! Discover the best platforms for data analysis, visualization, and machine learning.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-tools-1a9w1.jpg'
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2025-01-28
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
In case you haven't noticed, the data science industry is constantly evolving, potentially even faster than the web industry (which says a lot\!).
|
||||
|
||||
And 2025 is shaping up to be another transformative year for tools and technologies. Whether you're exploring machine learning tools, predictive modeling, data management, or data visualization tools, there's an incredible array of software to enable [data scientists](https://roadmap.sh/ai-data-scientist) to analyze data efficiently, manage data effectively, and communicate insights.
|
||||
|
||||
In this article, we dive into the essential data science tools you need to know for 2025, complete with ratings and expert picks to help you navigate the options.
|
||||
|
||||
## What is Data Science?
|
||||
|
||||
Data science is an interdisciplinary field that combines mathematics, statistics, computer science, and domain expertise to extract meaningful insights from data. It involves collecting, cleaning, and analyzing large datasets to uncover patterns, trends, and actionable information. At its core, data science aims to solve complex problems through data-driven decision-making, using techniques such as machine learning, predictive modeling, and data visualization.
|
||||
|
||||
The data science process typically involves:
|
||||
|
||||
* **Data Collection**: Gathering data from various sources, such as databases, APIs, or real-time sensors.
|
||||
* **Data Preparation**: Cleaning and transforming raw data into a usable format for analysis.
|
||||
* **Exploratory Data Analysis (EDA):** Identifying trends, correlations, and outliers within the dataset.
|
||||
* **Modeling**: Using algorithms and statistical methods to make predictions or classify data.
|
||||
* **Interpretation and Communication**: Visualizing results and presenting insights to stakeholders in an understandable manner.
|
||||
|
||||
Data science plays a key role in various industries, including healthcare, finance, marketing, and technology, driving innovation and efficiency by leveraging the power of data.
|
||||
|
||||
## Criteria for Ratings
|
||||
|
||||
We rated each of the best data science tools on a 5-star scale based on:
|
||||
|
||||
* **Performance:** How efficiently the tool handles large and complex datasets. This includes speed, resource optimization, and reliability during computation.
|
||||
* **Scalability:** The ability to scale across big data and multiple datasets. Tools were evaluated on their capability to maintain performance as data sizes grow.
|
||||
* **Community and Ecosystem:** Availability of resources, support, and integrations. Tools with strong community support and extensive libraries received higher ratings.
|
||||
* **Learning Curve:** Ease of adoption for new and experienced users. Tools with clear documentation and intuitive interfaces were rated more favorably.
|
||||
|
||||
## Expert Recommendations
|
||||
|
||||
Picking the best tools for your project is never easy, and it's hard to make an objective decision if you don't have experience with any of them.
|
||||
|
||||
So to make your life a bit easier, here's my personal recommendation, you can take it or leave it, it's up to you, but at least you'll know where to start:
|
||||
|
||||
While each tool has its strengths, my favorite pick among them is **TensorFlow**. Its perfect scores in performance, scalability, and community support (you'll see them in a second in the table below), combined with its relatively moderate learning curve, make it an amazing choice for building advanced neural networks and developing predictive analytics systems. You can do so much with it, like image recognition, natural language processing, and recommendation systems cementing its position as the leading choice (and my personal choice) in 2025\.
|
||||
|
||||
Now, to help you understand and compare the rest of the tools from this guide, the table below summarizes their grades across key criteria: performance, scalability, community support, and learning curve. It also highlights the primary use cases for these tools.
|
||||
|
||||
| Tool | Performance | Scalability | Community | Learning Curve | Best For |
|
||||
| ----- | ----- | ----- | ----- | ----- | ----- |
|
||||
| TensorFlow | 5 | 5 | 5 | 4 | Advanced neural networks, predictive analytics |
|
||||
| Apache Spark | 5 | 5 | 5 | 3 | Distributed analytics, real-time streaming |
|
||||
| Jupyter Notebooks | 4 | 4 | 5 | 5 | Exploratory analysis, education |
|
||||
| Julia | 4 | 4 | 4 | 3 | Simulations, statistical modeling |
|
||||
| NumPy | 4 | 3 | 5 | 5 | Numerical arrays, preprocessing workflows |
|
||||
| Polars | 5 | 4 | 4 | 4 | Data preprocessing, ETL acceleration |
|
||||
| Apache Arrow | 5 | 5 | 4 | 3 | Interoperability, streaming analytics |
|
||||
| Streamlit | 4 | 4 | 5 | 5 | Interactive dashboards, rapid deployment |
|
||||
| DuckDB | 4 | 4 | 4 | 5 | SQL queries, lightweight warehousing |
|
||||
| dbt | 4 | 4 | 5 | 4 | SQL transformations, pipeline automation |
|
||||
| Matplotlib | 4 | 3 | 5 | 4 | Advanced visualizations, publication graphics |
|
||||
|
||||
Let's now deep dive into each of these tools to understand in more detail, why they're in this guide.
|
||||
|
||||
## Data science tools for ML & Deep learning tools
|
||||
|
||||
### TensorFlow
|
||||
|
||||

|
||||
|
||||
TensorFlow remains one of the top data science tools for deep learning models and machine learning applications. Developed by Google, this open-source platform excels in building neural networks, predictive analytics, and natural language processing models.
|
||||
|
||||
* **Performance (★★★★★):** TensorFlow achieves top marks here due to its use of GPU and TPU acceleration, which allows seamless handling of extremely large models. Its ability to train complex networks without compromising on speed solidifies its high-performance ranking.
|
||||
* **Scalability (★★★★★):** TensorFlow scales from single devices to distributed systems effortlessly, enabling use in both prototyping and full-scale production.
|
||||
* **Community and Ecosystem (★★★★★):** With an active developer community and comprehensive support, TensorFlow offers unmatched resources and third-party integrations.
|
||||
* **Learning Curve (★★★★):** While it offers immense power, mastering TensorFlow's advanced features requires time, making it slightly less accessible for beginners compared to simpler frameworks.
|
||||
|
||||
**Strengths:** TensorFlow is a powerhouse for performance and scalability in the world of machine learning. Its GPU and TPU acceleration allow users to train and deploy complex models faster than many competitors. The massive community ensures constant innovation, with frequent updates, robust third-party integrations, and an ever-growing library of resources. The inclusion of TensorFlow Lite and TensorFlow.js makes it versatile for both edge computing and web applications.
|
||||
|
||||
**Best For:** Developing advanced neural networks for image recognition, natural language processing pipelines, building recommendation systems, and creating robust predictive analytics tools for a wide array of industries.
|
||||
|
||||
**Used by:** Google itself uses TensorFlow extensively for tasks like search algorithms, image recognition, and natural language processing. Similarly, Amazon employs TensorFlow to power recommendation systems and optimize demand forecasting.
|
||||
|
||||
## Data science tools for big data processing
|
||||
|
||||
### Apache Spark
|
||||
|
||||

|
||||
|
||||
An Apache Software Foundation project, Apache Spark is a powerhouse for big data processing, enabling data scientists to perform batch processing and streaming data analysis. It supports a wide range of programming languages, including Python, Scala, and Java, and integrates well with other big data tools like Hadoop and Kafka.
|
||||
|
||||
* **Performance (★★★★★):** Spark excels in processing speed thanks to its in-memory computing capabilities, making it a leader in real-time and batch data processing.
|
||||
* **Scalability (★★★★★):** Designed for distributed systems, Spark handles petabytes of data with ease, maintaining efficiency across clusters.
|
||||
* **Community and Ecosystem (★★★★★):** Spark's widespread adoption and integration with tools like Kafka and Hadoop make it a staple for big data workflows.
|
||||
* **Learning Curve (★★★):** Beginners may find distributed computing concepts challenging, though excellent documentation helps mitigate this.
|
||||
|
||||
**Strengths:** Spark stands out for its lightning-fast processing speed and flexibility. Its in-memory computation ensures minimal delays during large-scale batch or streaming tasks. The compatibility with multiple programming languages and big data tools enhances its integration into diverse tech stacks.
|
||||
|
||||
**Best For:** Executing large-scale data analytics in distributed systems, real-time stream processing for IoT applications, running ETL pipelines, and data mining for insights in industries like finance and healthcare.
|
||||
|
||||
**Used by:** Apache Spark has been adopted by companies like Uber and Shopify. Uber uses Spark for real-time analytics and stream processing, enabling efficient ride-sharing logistics. Shopify relies on Spark to process large volumes of e-commerce data, supporting advanced analytics and business intelligence workflows.
|
||||
|
||||
## Exploratory & Collaborative tools
|
||||
|
||||
### Jupyter Notebooks
|
||||
|
||||

|
||||
|
||||
Jupyter Notebooks are an essential data science tool for creating interactive and shareable documents that combine code, visualizations, and narrative text. With support for over 40 programming languages, including Python, R, and Julia, Jupyter facilitates collaboration and exploratory data analysis.
|
||||
|
||||
* **Performance (★★★★):** Jupyter is designed for interactivity rather than computational intensity, which makes it highly effective for small to medium-scale projects but less suitable for high-performance tasks.
|
||||
* **Scalability (★★★★):** While Jupyter itself isn't designed for massive datasets, its compatibility with scalable backends like Apache Spark ensures it remains relevant for larger projects.
|
||||
* **Community and Ecosystem (★★★★★):** Jupyter's open-source nature and extensive community-driven extensions make it a powerhouse for versatility and support.
|
||||
* **Learning Curve (★★★★★):** Its simple and intuitive interface makes it one of the most accessible tools for beginners and professionals alike
|
||||
|
||||
**Strengths:** Jupyter's flexibility and ease of use make it indispensable for exploratory analysis and education. Its ability to integrate code, output, and explanatory text in a single interface fosters collaboration and transparency.
|
||||
|
||||
**Best For:** Creating educational tutorials, performing exploratory data analysis, prototyping machine learning models, and sharing reports that integrate code with rich visualizations.
|
||||
|
||||
**Used by:** Jupyter Notebooks have become a staple for exploratory analysis and collaboration. Delivery Hero uses Jupyter to enhance delivery logistics through data analysis and visualization, while Intuit leverages the tool to facilitate financial data analysis in collaborative projects.
|
||||
|
||||
## Data science tools for statistical computing
|
||||
|
||||
### Julia
|
||||
|
||||

|
||||
|
||||
Julia is an emerging open-source programming language tailored for statistical computing and data manipulation. It combines the performance of low-level languages like C with the simplicity of high-level languages like Python. Julia's strengths lie in its speed for numerical computation and its dynamic type system, making it highly suitable for big data applications and machine learning models. The Julia ecosystem is rapidly growing, offering libraries for data visualization, optimization, and deep learning.
|
||||
|
||||
* **Performance (★★★★):** Julia's design prioritizes speed for numerical and statistical computing, placing it ahead of many high-level languages in terms of raw performance.
|
||||
* **Scalability (★★★★):** With built-in support for parallel computing, Julia scales well for tasks requiring significant computational power, although its ecosystem is still catching up to Python's.
|
||||
* **Community and Ecosystem (★★★★):** Julia's growing community and the increasing availability of libraries make it a solid choice, though it's not yet as robust as more established ecosystems.
|
||||
* **Learning Curve (★★★):** Julia's unique syntax, while designed for simplicity, presents a learning barrier for those transitioning from other languages like Python or R.
|
||||
|
||||
**Strengths:** Julia's ability to execute complex numerical tasks at high speed positions it as a top contender in scientific computing. Its built-in support for parallelism allows it to scale efficiently, while its clear syntax lowers barriers for domain experts transitioning from MATLAB or R.
|
||||
|
||||
**Best For:** Performing advanced statistical analysis, numerical optimization, developing simulations in physics and finance, and implementing machine learning models for high-performance environments.
|
||||
|
||||
**Used by:** The high-performance capabilities of Julia make it a favorite for statistical computing in industries like finance. For example, Capital One uses Julia for risk analytics and modeling, and Aviva employs it to improve actuarial computations and financial modeling processes.
|
||||
|
||||
### NumPy
|
||||
|
||||

|
||||
|
||||
A foundational library in the Python ecosystem, NumPy provides powerful tools for managing data structures, numerical computations, and statistical analysis. It is widely used for data preparation, enabling operations on large multi-dimensional arrays and matrices.
|
||||
|
||||
* **Performance (★★★★):** NumPy's optimized C-based implementation allows it to handle numerical operations with high efficiency, but it relies on integration with other tools for larger or distributed workloads.
|
||||
* **Scalability (★★★):** As a single-machine library, NumPy is best suited for datasets that fit in memory, though it integrates well with scalable tools like Dask for extended use.
|
||||
* **Community and Ecosystem (★★★★★):** NumPy's foundational role in Python's data science ecosystem means extensive resources and near-universal compatibility.
|
||||
* **Learning Curve (★★★★★):** Its straightforward API and clear documentation make NumPy an essential and approachable tool for data preparation and numerical computing.
|
||||
|
||||
**Strengths:** NumPy's versatility and efficiency underpin its widespread adoption in the Python ecosystem. Its array manipulation capabilities—from slicing and reshaping to broadcasting—make it a cornerstone for numerical operations.
|
||||
|
||||
**Best For:** Handling numerical arrays for preprocessing, matrix algebra in physics and engineering, foundational operations for machine learning pipelines, and performing basic statistical analysis efficiently.
|
||||
|
||||
**Used by:** NumPy serves as the foundation for many Python-based workflows. Spotify uses NumPy for numerical computations within its recommendation algorithms, and Airbnb employs it to optimize pricing strategies and improve customer experience through data analysis.
|
||||
|
||||
## **Data science tools for data manipulation & preprocessing tools**
|
||||
|
||||
### Polars
|
||||
|
||||

|
||||
|
||||
Polars is a lightning-fast data processing & manipulation library that enables data scientists to handle complex datasets. Unlike traditional libraries, Polars is written in Rust, offering exceptional performance and low memory usage. Its DataFrame API is intuitive and supports multi-threaded operations, making it a strong choice for large-scale data preprocessing and manipulation tasks.
|
||||
|
||||
* **Performance** (★★★★★): Polars' Rust-based architecture ensures exceptional speed and memory efficiency, positioning it as a leading tool for high-performance data manipulation.
|
||||
* **Scalability** (★★★★): While optimized for larger datasets, its scalability is limited to environments supported by multi-threading rather than distributed systems.
|
||||
* **Community and Ecosystem** (★★★★): Though its ecosystem is still growing, Polars' strong integration with Python and intuitive API provide a solid foundation.
|
||||
* **Learning Curve** (★★★★): With a user-friendly interface inspired by Pandas, Polars is easy to adopt for those familiar with similar tools, though Rust concepts may pose challenges for some.
|
||||
|
||||
**Strengths:** Polars stands out due to its unparalleled speed, derived from its Rust-based architecture. Its ability to process data in parallel ensures efficiency even with large datasets, reducing bottlenecks in ETL pipelines. The intuitive API and support for lazy evaluation make it both user-friendly and powerful.
|
||||
|
||||
**Best For:** Processing complex datasets for data cleaning, reshaping large-scale tables, and accelerating ETL pipelines in environments requiring high-speed operations.
|
||||
|
||||
**Used by:** Polars is gaining traction for its exceptional speed in data preprocessing and ETL workflows. Zillow uses Polars for efficient data preprocessing in real estate market analysis, while Stripe adopts it to accelerate ETL processes for handling financial transaction data.
|
||||
|
||||
### Apache Arrow
|
||||
|
||||

|
||||
|
||||
Apache Arrow is revolutionizing how data is stored and transferred for big data applications. Its in-memory columnar format accelerates data processing and integration between multiple datasets and tools. Apache Arrow also acts as a bridge between various programming languages and frameworks, improving the interoperability of data science workflows.
|
||||
|
||||
* **Performance (★★★★★):** Apache Arrow's in-memory columnar format delivers unmatched speed for data processing and transfer between tools.
|
||||
* **Scalability (★★★★★):** Its design supports seamless scalability across distributed systems, making it ideal for large-scale workflows.
|
||||
* **Community and Ecosystem (★★★★):** Arrow's adoption by major data tools ensures growing support, though its standalone ecosystem remains limited compared to broader frameworks.
|
||||
* **Learning Curve (★★★):** Understanding columnar data formats and workflows may require extra effort for beginners but pays off in advanced scenarios.
|
||||
|
||||
**Strengths:** Apache Arrow's columnar format provides a significant boost in performance and compatibility. Its seamless interoperability between tools such as Pandas, Spark, and TensorFlow eliminates data transfer inefficiencies. The library also supports multi-language workflows, making it indispensable for teams leveraging diverse tech stacks.
|
||||
|
||||
**Best For:** Ensuring efficient interoperability between data tools, accelerating data lake operations, and supporting real-time data analytics in distributed systems.
|
||||
|
||||
**Used by:** Google BigQuery integrates Arrow to enhance data interchange and query performance, and AWS Athena relies on Arrow's in-memory format to facilitate faster query responses and real-time analytics.
|
||||
|
||||
## Data science tools for application development
|
||||
|
||||
### Streamlit
|
||||
|
||||

|
||||
|
||||
Streamlit is an open-source framework for creating custom data science applications and dashboards. It simplifies the process of building interactive apps by using Python scripts, making it accessible even for those with minimal web development experience. Streamlit's API enables rapid prototyping of machine learning tools and visualizations.
|
||||
|
||||
* **Performance (★★★★):** Optimized for real-time application development, Streamlit is fast for small to medium-scale projects.
|
||||
* **Scalability (★★★★):** Streamlit scales reasonably well but isn't designed for massive applications.
|
||||
* **Community and Ecosystem (★★★★★):** Its active community and constant updates ensure excellent support for users.
|
||||
* **Learning Curve (★★★★★):** With a simple API and Python-centric design, Streamlit is easy for both developers and non-developers.
|
||||
|
||||
**Strengths:** Streamlit's simplicity and speed make it ideal for crafting interactive dashboards with minimal effort. Its integration with popular Python libraries like Pandas and Matplotlib allows users to transform raw data into meaningful insights quickly.
|
||||
|
||||
**Best For:** Creating interactive dashboards for sharing machine learning predictions, visualizing complex datasets with minimal development effort, and rapidly deploying prototypes for stakeholder feedback.
|
||||
|
||||
**Used by:** Streamlit simplifies the creation of interactive dashboards and data applications. Companies like Snowflake use Streamlit to build client-facing data apps, while Octopus Energy employs it to create dashboards that visualize energy consumption data for their customers.
|
||||
|
||||
### DuckDB
|
||||
|
||||

|
||||
|
||||
DuckDB is an open-source analytics database that simplifies structured queries on raw data. Designed to operate within analytical workflows, it supports SQL-based queries without the need for a dedicated database server. Its efficient storage model makes it ideal for querying structured and unstructured data in ad hoc analysis scenarios, making it highly favored for lightweight data warehousing tasks.
|
||||
|
||||
* **Performance (★★★★):** DuckDB delivers impressive speeds for ad hoc analytics, optimized for single-machine workflows.
|
||||
* **Scalability (★★★★):** Suitable for lightweight to medium-scale tasks, DuckDB integrates well into Python and R environments.
|
||||
* **Community and Ecosystem (★★★★):** Growing adoption and strong SQL compatibility make it increasingly popular.
|
||||
* **Learning Curve (★★★★★):** Its SQL-based interface ensures a smooth learning experience for most users.
|
||||
|
||||
**Strengths:** DuckDB's efficiency and ease of use make it a go-to tool for analysts. Its ability to operate without infrastructure overhead allows rapid deployment, and its SQL compatibility ensures accessibility for non-programmers.
|
||||
|
||||
**Best For:** Running interactive SQL queries in development workflows, performing data warehousing tasks without infrastructure overhead, and integrating ad hoc analyses directly into Python-based projects.
|
||||
|
||||
**Used by:** DuckDB's lightweight and efficient SQL analytics have found applications in various industries. MotherDuck integrates DuckDB to enable fast, in-process analytical queries, and SeMI Technologies leverages DuckDB within its Weaviate platform for high-speed vector search analytics.
|
||||
|
||||
### dbt (Data Build Tool)
|
||||
|
||||

|
||||
|
||||
dbt is a development framework for transforming data in warehouses. It allows analysts and engineers to write modular SQL-based transformations and manage data workflows efficiently. With its focus on collaboration and version control, dbt has become an essential tool for teams working on data pipelines.
|
||||
|
||||
* **Performance (★★★★):** dbt's modular approach allows for efficient and scalable SQL transformations.
|
||||
* **Scalability (★★★★):** Designed for modern data warehouses, dbt handles increasing workloads effectively.
|
||||
* **Community and Ecosystem (★★★★★):** Its thriving community and vendor support make it indispensable for data pipeline management.
|
||||
* **Learning Curve (★★★★):** Familiarity with SQL simplifies adoption, though pipeline concepts may require additional learning.
|
||||
|
||||
**Strengths:** dbt's modularity and focus on collaboration streamline complex SQL transformations. Its integration with version control systems ensures reproducibility, while the ability to test and document transformations within the tool fosters better collaboration among data teams.
|
||||
|
||||
**Best For:** Automating SQL transformations for analytics, managing data warehouse workflows with version control, and creating reusable and modular pipelines for team collaboration.
|
||||
|
||||
**Used by:** dbt has become essential for transforming and managing data workflows. JetBlue uses dbt to optimize their data warehouse for improved analytics, and GitLab adopts it to transform raw data into actionable insights, streamlining their analytics operations.
|
||||
|
||||
## Data science tools for data visualization
|
||||
|
||||
### Matplotlib
|
||||
|
||||

|
||||
|
||||
Matplotlib is a widely used data visualization library in Python that allows users to create static, animated, and interactive visualizations. Known for its flexibility, Matplotlib supports detailed customization, making it suitable for complex visualizations required in data science projects.
|
||||
|
||||
* **Performance (★★★★):** Matplotlib handles visualization tasks efficiently for small to medium datasets but may lag with complex or large-scale rendering.
|
||||
* **Scalability (★★★):** Designed for single-threaded use, it integrates with scalable tools for extended capabilities.
|
||||
* **Community and Ecosystem (★★★★★):** A veteran library with vast resources and tutorials ensures comprehensive support.
|
||||
* **Learning Curve (★★★★):** Accessible for beginners, though mastering advanced features takes effort.
|
||||
|
||||
**Strengths:** Matplotlib's extensive customization options allow it to cater to diverse visualization needs, from simple plots to publication-grade graphics. Its compatibility with libraries like NumPy ensures seamless data integration, while the active community provides extensive tutorials and third-party tools. Despite being a veteran library, Matplotlib remains relevant by adapting to modern visualization demands.
|
||||
|
||||
**Best For:** Creating publication-quality figures, animating time-series data, developing exploratory charts, and embedding visualizations into data-driven applications.
|
||||
|
||||
**Used by:** NASA uses Matplotlib to plot and visualize space mission data, while CERN relies on it for visualizing complex results from particle physics experiments.
|
||||
|
||||
## How to Pick the Right Data Science Tool?
|
||||
|
||||
Choosing the right data science tool can be a daunting task given the vast array of options available. The best tool for your project will depend on several factors, which can be broadly categorized into the evaluation criteria and the context of your specific project.
|
||||
|
||||
### Importance of Evaluation Criteria
|
||||
|
||||
1. **Performance**: This determines how well the tool handles large and complex datasets. Tools that offer fast computation, reliable processing, and efficient use of resources are ideal for high-performance environments.
|
||||
2. **Scalability**: As data grows, the ability to maintain consistent performance is critical. Tools that scale across big data frameworks or distributed systems ensure longevity and adaptability.
|
||||
3. **Community and Ecosystem**: A strong community provides valuable resources such as tutorials, documentation, and support. An extensive ecosystem ensures compatibility with other tools and libraries, making integration seamless.
|
||||
4. **Learning Curve**: A tool's usability can make or break its adoption. Tools with intuitive interfaces and comprehensive documentation enable faster onboarding for teams with diverse expertise.
|
||||
|
||||
### Considering Project Context
|
||||
|
||||
While evaluation criteria provide a standardized way to compare tools, the context of your project ultimately determines the best fit. Key considerations include:
|
||||
|
||||
Tech Stack: The tools should integrate smoothly with your existing technologies and workflows.
|
||||
|
||||
Team Expertise: The skill levels and experience of your team play a significant role in adoption. A tool with a steep learning curve may not be ideal for a team of beginners.
|
||||
|
||||
Project Deadlines: Time constraints can affect the choice of tools. A tool with extensive setup requirements may not suit a project with tight deadlines.
|
||||
|
||||
Data Complexity and Size: The nature and volume of your data should align with the tool's capabilities.
|
||||
|
||||
By balancing these evaluation criteria with the unique needs of your project, you can ensure that the chosen tool maximizes efficiency and effectiveness while minimizing challenges.
|
||||
|
||||
## Final Thoughts
|
||||
|
||||
Data science is an exciting and ever-evolving field, and the tools we've explored here represent the state-of-the-art of innovation for 2025\. Each tool has its own strengths, from high performance and scalability to user-friendly interfaces and robust community support. Whether you're just starting out in data science or managing complex, large-scale projects, there's a tool out there that's just right for you.
|
||||
|
||||
However, choosing that tool isn't just about star ratings or feature lists—it's about finding what works best for your specific context.
|
||||
|
||||
And remember, data science is as much about the journey as it is about the results. Exploring new tools, learning from community resources, and iterating on your processes will make you a better data scientist and help your projects thrive.
|
||||
|
||||
Check out our [data scientist roadmap](https://roadmap.sh/ai-data-scientist) to get a full view of your potential journey ahead\!
|
||||
@@ -1,174 +0,0 @@
|
||||
---
|
||||
title: "Data Science vs. AI: How I Would Choose My Path"
|
||||
description: "If you love working with data, should you become a data scientist or an AI engineer? Here's how I made my choice."
|
||||
authorId: william
|
||||
excludedBySlug: '/ai-data-scientist/vs-ai'
|
||||
seo:
|
||||
title: "Data Science vs. AI: How I Would Choose My Path"
|
||||
description: "If you love working with data, should you become a data scientist or an AI engineer? Here's how I made my choice."
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-vs-artificial-intelligence-w7gl5.jpg'
|
||||
isNew: true
|
||||
type: 'textual'
|
||||
date: 2025-03-24
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Choosing between specializing in data science and AI comes down to what you like and the problems you want to solve. If you enjoy analyzing data, uncovering insights, and making data-driven decisions, data science might be for you. But artificial intelligence is the way to go if you're into creating systems that can learn, adapt, and make decisions on their own.
|
||||
|
||||
When I first got into tech, I wasn't sure which path to take. I spent late nights researching, feeling both excited and overwhelmed. Data science and AI seemed so similar that telling them apart felt impossible, especially since many jobs required skills in both. But as I dug deeper, I realized they have distinct focuses despite their overlap.
|
||||
|
||||
Data science focuses on extracting meaningful insights from data. As a data scientist, you'll be responsible for designing datasets, building models to analyze data, identifying patterns, and solving complex problems to help businesses make better decisions. You'll do this using statistical analysis and several machine learning techniques like supervised and unsupervised learning.
|
||||
|
||||
In contrast, artificial intelligence is about developing intelligent systems that can perform tasks that typically require human intelligence. These tasks include pattern recognition, predictive analysis, and language translation. You'll design algorithms to learn and solve problems without constant human intervention.
|
||||
|
||||
If you don't know much about data science and AI, don't worry about it. Check out our beginner's guide on [data science](https://roadmap.sh/ai-data-scientist) and [AI](https://roadmap.sh/ai-engineer) to get a good overview of both fields. In this guide, I'll show you what each field is about, the skills you need, and the opportunities they offer. By the end, you'll know which career path suits you best based on your interests, skills, and goals.
|
||||
|
||||
## Data science vs. AI: What are the key differences?
|
||||
|
||||
When discussing data science and AI, many people often mix them up. While they share similarities, their purposes, tools, and techniques differ. The table below summarizes the key differences between data science and AI:
|
||||
|
||||
| Characteristics | Data science | Artificial intelligence |
|
||||
| ---------------- | ---------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------- |
|
||||
| Primary focus | Extracting insights from data | Building intelligent systems that mimic human intelligence to perform tasks |
|
||||
| Responsibilities | Data collection, data cleaning, data analysis, data modeling, data visualization, and building predictive models | Building and training machine learning models, machine learning algorithms, and artificial intelligence applications |
|
||||
| Tools | Python, R, SQL, Pandas, Hadoop, TensorFlow, Tableau | Java, Python, PyTorch, OpenCV, spaCy, GPUs, AWS and Keras |
|
||||
| Educational path | Bachelor's in computer science, statistics, or mathematics; master's in data science | Bachelor's in computer science, mathematics, or engineering; master's in AI or related field |
|
||||
| Career paths | Data analyst, data scientist, business analyst, machine learning engineer | AI engineer, machine learning engineer, AI product manager, NLP enginner, AI research scientist |
|
||||
| Applications | Predictive analytics, fraud detection, customer segmentation, healthcare analytics and more | Self-driving cars, chatbots, robotics, predictive maintenance, medical imaging analysis and more |
|
||||
|
||||
## Primary focus
|
||||
|
||||
One big difference between data science and AI is what they focus on the most. Data science focuses on uncovering insights and solving problems through data analytics. It uses structured data like customer databases to identify patterns and solve complex problems. You'll use advanced tools and machine learning techniques like computer vision to work with unstructured data like videos and images.
|
||||
|
||||
If you choose data science, you'll work on extracting valuable insights from data. For example, a data scientist working in finance will use anomaly detection to analyze transactional data. This helps with fraud detection and risk assessment, e.g., unusual login attempts.
|
||||
|
||||

|
||||
|
||||
In contrast, if you choose artificial intelligence, you'll focus on building systems that mimic human intelligence, like learning, reasoning, and solving problems. It uses structured and unstructured data to enable machines to perform tasks like pattern recognition in images and speech and natural language processing. For example, AI virtual assistants like Siri can listen and reply to what you're saying. They use natural language processing models to recognize and understand your voice (human language). It makes it easy for you to ask and get answers to questions just by talking.
|
||||
|
||||
## Daily responsibilities
|
||||
|
||||
Data scientists and AI engineers have different responsibilities that show their focus areas. As a data scientist, your daily duties will include:
|
||||
|
||||
- **Data collection**: This is often the first thing you do when extracting insights from data. Your job will be to collect large volumes of data from several sources, such as databases. For example, a healthcare data scientist will collect and analyze patient data to create models to help in diagnosing diseases. It'll make it easier to predict patient outcomes and make treatment plans better.
|
||||
- **Data cleaning**: After you collect all the data, the next step is to clean the data. Doing this means removing errors from the raw data to prepare it for data analysis.
|
||||
- **Data analysis**: After cleaning, you'll analyze data to identify patterns and trends. You'll do this using statistical analysis and machine learning techniques like clustering.
|
||||
- **Building models**: You'll create predictive models to make future predictions based on historical data. A company like Netflix, for example, uses predictive models to suggest TV shows and movies to you. The data scientist will analyze your past data to see what shows you've watched, how you rated them, and more. Then, they will use this data to build a model that suggests similar shows you'll like.
|
||||
- **Data visualization**: Visualizing data is about presenting complex data in a visual format. As a data scientist, you'll use data visualization tools like Tableau and Power BI to present data in a way that every team member will understand.
|
||||
|
||||

|
||||
|
||||
On the flip side, AI involves various responsibilities like designing, training, and testing AI models. As an AI engineer, your daily responsibilities will include:
|
||||
|
||||
- **Data preparation**: You'll collect, clean, analyze, and work with large amounts of data to train and test AI models (i.e., machine learning models). Yes, as an AI engineer, you'll also analyze data, although it is the primary duty of the data scientists. Doing this lets you check if the data is good for the AI model and spot any problems that could mess up the training.
|
||||
- **Model training**: You'll be responsible for developing algorithms that enable machines to learn from data using machine learning techniques like computer vision and neural networks. For example, automotive industries use artificial intelligence to create self-driving cars. They use AI algorithms to analyze sensor data from cameras, radar, and lasers to see what's around them.
|
||||
- **Review models**: You'll test and make sure that the models provide reliable results. Imagine you've developed a model to identify diseases from analyzing medical images. You'll use images the model hasn't seen before to test its accuracy at spotting diseases. If it misses something, that's your cue to tweak it until it gets better.
|
||||
- **Implementation**: Once you create a model, you need to make sure it works well with other systems. It's like having a chatbot on a website to handle customer inquiries, using a fraud detection system in a bank to analyze transactions, or incorporating GPS functionality in self-driving cars for navigation. Additionally, you'll monitor and maintain its performance and update it when needed.
|
||||
|
||||
## The tools you'll use
|
||||
|
||||
One important thing to consider when choosing between data science and AI is the tools you'll use. In data science, you'll work with programming languages like [Python](https://roadmap.sh/python), R, and [SQL](https://roadmap.sh/sql) to extract insights and analyze data. You'll use Python libraries like Pandas to manipulate data and NumPy to make math calculations.
|
||||
|
||||
As a data scientist, you'll also use big data technologies like Hadoop to work with large volumes of data. Machine learning libraries like TensorFlow will help you develop advanced machine learning models. Also, you'll use data visualization tools like Tableau and Power BI when sharing your results.
|
||||
|
||||

|
||||
|
||||
On the flip side, artificial intelligence needs more advanced tools to work its magic. You'll use programming languages like [Java](https://roadmap.sh/java) and [Python](https://roadmap.sh/python), like in data science, but you'll focus on AI frameworks like PyTorch to train deep learning models, especially neural networks. These frameworks can do various machine learning tasks, such as supervised learning (e.g., image classification), unsupervised learning (e.g., anomaly detection), and reinforcement learning (e.g., game playing) when needed.
|
||||
|
||||
Tools like OpenCV will help with computer vision tasks, and libraries like NLTK and spaCy will help with natural language processing. As an AI engineer, you'll also work with specialized hardware like graphics processing units (GPUs) and tensor processing units (TPUs). These tools provide the computational power to train large neural networks well. Finally, you'll work with cloud platforms like [AWS](https://roadmap.sh/aws) and Google Cloud AI Platform to deploy and manage your AI models.
|
||||
|
||||
## How do the skills you need differ?
|
||||
|
||||
Now that you know the differences between data science and artificial intelligence, let's look at the skills you need. As a data scientist, it's important to build a solid understanding in the following areas:
|
||||
|
||||
- Proficient in programming skills like [Python](https://roadmap.sh/python) and [SQL](https://roadmap.sh/sql) for data analysis and manipulation.
|
||||
- Strong understanding of statistics and mathematics to analyze and interpret data.
|
||||
- Good in data wrangling for cleaning and organizing datasets before analysis.
|
||||
- Proficient in data mining to extract useful patterns and insights from large datasets.
|
||||
- Strong data visualization techniques to present valuable insights through tools such as Matplotlib or Tableau.
|
||||
- Basic understanding of machine learning principles and algorithms to apply predictive analytics and solve business problems.
|
||||
- Good critical thinking skills to analyze data and provide solutions to business problems using data.
|
||||
|
||||

|
||||
|
||||
In contrast, as an AI engineer, you'll create complex AI systems using the following skills:
|
||||
|
||||
- In-depth knowledge of advanced machine learning concepts, including neural networks, to create models for tasks like image recognition or natural language processing.
|
||||
- Proficiency in programming skills ([Python](https://roadmap.sh/python), [C++](https://roadmap.sh/c-plus-plus), [Java](https://roadmap.sh/java)) for creating complex algorithms.
|
||||
- Understanding mathematics, e.g., linear algebra and calculus for algorithm development.
|
||||
- Experience with frameworks like TensorFlow and PyTorch for building and deploying AI models.
|
||||
- Knowledge of computer vision and natural language processing to create intelligent systems that understand and interact with data.
|
||||
|
||||
## The educational pathway to data science and artificial intelligence career
|
||||
|
||||
A very good educational foundation is necessary to start a career as a data scientist. The first step is getting your bachelor's degree in computer science, data science, or artificial intelligence. These fields cover topics like algorithms, machine learning, and software development.
|
||||
|
||||

|
||||
|
||||
On the other hand, artificial intelligence often requires higher educational qualifications, such as a bachelor's, master's, or Ph.D., due to its technically complex and research-oriented nature. You'll first need a bachelor's degree in computer science, data science, or artificial intelligence to start a career in this field. This will give you a good understanding of machine learning, mathematics, and statistics. You'll go into detail on topics like algebra and calculus and learn languages like [Python](https://roadmap.sh/python) and [Java](https://roadmap.sh/java). Some AI engineers may pursue a master's degree if they aim for senior or research positions, but it's not always necessary.
|
||||
|
||||
Also, you don't always have to attend a university to learn. Some people who want to become data scientists and AI engineers go to boot camps, take online courses, or get certifications instead. Platforms like [roadmap.sh](https://roadmap.sh) offer detailed [data science](https://roadmap.sh/ai-data-scientist) and [AI courses](https://roadmap.sh/ai-engineer) to help you learn. The platforms are more flexible and focus on practical projects, so you can create a portfolio to showcase your skills.
|
||||
|
||||
## Which field offers better career prospects?
|
||||
|
||||
Data science and artificial intelligence both look promising in terms of job opportunities. Both fields are in high demand, so there are plenty of job opportunities out there for you. However, artificial intelligence jobs usually pay better because they need more advanced skills and technical knowledge in machine learning and algorithm development.
|
||||
|
||||

|
||||
|
||||
Data science is a recognized field with many uses in industries like finance, healthcare, and marketing. If you're interested in data science, you could work as a [data analyst](https://roadmap.sh/data-analyst), business analyst, or data scientist. According to [Indeed](https://www.indeed.com/career/data-scientist/salaries?from=top_sb), the average salary for a data scientist in the United States (USA) across all industries is $125,495.
|
||||
|
||||

|
||||
|
||||
On the other hand, artificial intelligence is in high demand in industries like robotics, automotive, and tech startups. If you're interested in artificial intelligence, you can work as a machine learning or AI engineer. [According to Indeed](https://www.indeed.com/career/machine-learning-engineer/salaries?from=top_sb), engineers working in machine learning in the USA make an average of $162,735 annually.
|
||||
|
||||

|
||||
|
||||
While salary is important when choosing between data science and artificial intelligence, it shouldn't be your only factor. For me, it's less about which field pays more and more about what excites you daily. You'll enjoy success and work satisfaction when you choose a job that matches your interests.
|
||||
|
||||
## Do data science and artificial intelligence overlap?
|
||||
|
||||
Yes, data science and artificial intelligence overlap. Data science is like the backbone of AI. It supplies the data and insights needed to train and improve artificial intelligence models.
|
||||
|
||||
Many skills overlap between data science and artificial intelligence. For instance, being good at coding in [Python](https://roadmap.sh/python), R, and [SQL](https://roadmap.sh/sql) is important in both fields. Both fields also need machine learning, statistics, and data visualization knowledge. Switching from data science to AI or vice versa is straightforward because they share many similarities in skills and tools.
|
||||
|
||||
## Will AI replace data science?
|
||||
|
||||
Will AI replace data science? This is a common concern among many data scientists since there's been a lot of buzz about AI. The simple answer is no: AI is not replacing data science.
|
||||
|
||||
Artificial intelligence tools can make it easier for data scientists to analyze data and predict trends faster. But we humans make sense of all that data, put it into context, and use it to make decisions for the company. Instead of seeing AI as a rival, think of it as a helpful tool that can help you get better at data science.
|
||||
|
||||
## Next steps to find your fit
|
||||
|
||||
If you're still trying to figure out which path to take, here are a few steps to help you find what feels right for you:
|
||||
|
||||
### Know your strengths
|
||||
|
||||
To find out which path is right for you, consider what you're good at and what excites you. Data science might be a good fit if you love analyzing data and finding out hidden stories behind numbers.
|
||||
|
||||
On the other hand, artificial intelligence might be better if you're into technology, algorithms, and creating systems that imitate human intelligence.
|
||||
|
||||
### Connect with others
|
||||
|
||||
Talk to some data science and artificial intelligence professionals and get their advice. Start by attending conferences or joining [online communities](https://roadmap.sh/discord) to connect with others.
|
||||
|
||||
You can ask questions, share your thoughts, and learn from others as a community member. When you chat with other professionals, ask them what they enjoy about their work, what their challenges are, and if they have any tips for newcomers. Listening to their stories can give you a better idea of what each job is really like.
|
||||
|
||||
### Don't be afraid to try
|
||||
|
||||
Don't be afraid to try new things and step out of your comfort zone. You might think you're into data science, but after taking some classes or working on projects, you could realize that artificial intelligence is where your true passion lies. It is completely normal and is part of the learning journey.
|
||||
|
||||
## What next?
|
||||
|
||||
Artificial intelligence and data science have changed how businesses work and make decisions. Both fields have great job opportunities, but the skills needed for each are different. Understanding the basics of these fields will help you pick the right path for you.
|
||||
|
||||
It's not about figuring out which field is better than the other—it's about choosing the one that fits your goals, interests, and skills. So relax and take some time to figure out what you're really into before making any big decisions.
|
||||
|
||||
For continuous learning, visit the roadmap.sh [data science](https://roadmap.sh/ai-data-scientist) and [artificial intelligence](https://roadmap.sh/ai-engineer) guides. Both guides have all the resources you need to start your journey as a data scientist or AI engineer.
|
||||
@@ -1,189 +0,0 @@
|
||||
---
|
||||
title: "Data Science vs Business Analytics: How I'd Choose My Path"
|
||||
description: "I once struggled to choose between data science and business analytics. If you're in the same boat, I'll guide you to find the right fit."
|
||||
authorId: ekene
|
||||
excludedBySlug: '/ai-data-scientist/vs-business-analytics'
|
||||
seo:
|
||||
title: "Data Science vs Business Analytics: How I'd Choose My Path"
|
||||
description: "I once struggled to choose between data science and business analytics. If you're in the same boat, I'll guide you to find the right fit."
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-and-business-analytics-zxubk.jpg'
|
||||
isNew: true
|
||||
type: 'textual'
|
||||
date: 2025-03-24
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
If you enjoy coding, working with algorithms, and solving mathematical problems, you'll likely thrive in [data science](https://roadmap.sh/ai-data-scientist). However, if you prefer analyzing trends, making strategic decisions, and communicating insights, business analytics is a better fit.
|
||||
|
||||
When I was deciding between the two, I kept getting lost in job descriptions and salary comparisons. But what really mattered was how I wanted to work with data. Did I want to build models and predict future trends? Or did I want to interpret existing data to solve business problems?
|
||||
|
||||
If you're facing the same dilemma, the best way to decide is by understanding what each role actually does and how it fits your strengths. In this guide, I'll walk you through the key differences, career paths, and real-world examples, so by the end, you'll have clarity on the right choice for you.
|
||||
|
||||
Before diving in, here's a quick comparison:
|
||||
|
||||
| | Data Science | Business Analytics |
|
||||
| ------------ | ------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Key role | Building data models and using math and programming to analyze complex data and extract insights. | Analyzing data and digging for insights to solve specific business problems and presenting them to inform strategy. |
|
||||
| Skills | Machine learning, advanced mathematics, programming, business intelligence, data analytics, and data visualization. | Data analysis using Excel or Sheets, SQL, visualization, basic statistical modeling, business intelligence, communication, presentation, and problem-solving. |
|
||||
| Tools | Python, R, SQL, Tableau, PyTorch, Power BI, Tensorflow. | SQL, Excel, business acumen, data visualization tools, and communication. |
|
||||
| Career paths | Data scientist, AI researcher, data engineer, machine learning engineer. | Business analyst, data scientist, operation analyst, data analyst, product analyst, marketing analyst. |
|
||||
|
||||
Now, let’s get into the meat. If I were in your shoes, the first step I'd take is to understand the differences and similarities between business analytics and data science.
|
||||
|
||||
## Data science vs. business analytics: What sets them apart?
|
||||
|
||||
The difference between data science and business analytics comes down to how you want to work with data.
|
||||
|
||||
When I was making this decision, I had to ask myself: Do I enjoy coding, working with algorithms, and solving mathematical problems? If so, data science was the better fit. Or do I prefer analyzing trends, making strategic decisions, and communicating insights? In that case, business analytics made more sense.
|
||||
|
||||
If you go the data science route, you'll take a highly technical approach that blends [computer science](https://roadmap.sh/computer-science), mathematics, and business knowledge. You'll work with business analysts to understand key challenges, then clean, explore, and mine unstructured and structured data to improve its quality.
|
||||
|
||||
Once the data is ready, you'll build and test predictive models using machine learning algorithms to uncover hidden patterns. These models help businesses make data-driven predictions, optimize processes, and automate decision-making.
|
||||
|
||||
When I looked at these responsibilities, I realized data science was all about solving complex problems, discovering trends, and forecasting what's next. If that excites you, it might be the right path.
|
||||
|
||||

|
||||
|
||||
Business analytics might be a better fit if you don't fancy data science. You'll sit at the intersection of business, data, and operations. You are responsible for evaluating the business's overall health, identifying gaps, and recommending solutions to improve business operations.
|
||||
|
||||
You'll also perform basic data cleaning and transformation using tools like [SQL](https://roadmap.sh/sql) and Excel. However, your primary focus is analyzing data to uncover insights, create reports, and present findings to stakeholders.
|
||||
|
||||
Beyond analysis, I realized that business analysts also take action. You'll recommend strategic next steps based on data insights and collaborate with decision-makers to execute them. This means being involved in change strategy and ensuring that insights lead to tangible business improvements.
|
||||
|
||||
For example, imagine you work for an energy company and notice a drop in residential electricity usage due to increased solar panel adoption. A data scientist will build predictive models to forecast energy demand, optimize distribution, and detect anomalies. A business analyst, meanwhile, will interpret these insights, develop strategies like solar buyback programs, and lead their implementation to drive impact.
|
||||
|
||||
## What Are Their Similarities?
|
||||
|
||||
Although data science and business analytics have differences, after working in both fields, I realized that they share the same goal. Both disciplines focus on transforming raw data into valuable insights that drive business decisions.
|
||||
|
||||

|
||||
|
||||
Think of them as two sides of the same coin. Both fields involve data mining, statistical analysis, data visualization, [SQL](https://roadmap.sh/sql) usage, problem-solving, and stakeholder collaboration. They work together to help businesses make sense of their data, but their approach and execution set them apart.
|
||||
|
||||
The next step to take is to understand what daily tasks may look like and which one you’d prefer.
|
||||
|
||||
## What Would Your Day-to-Day Look Like?
|
||||
|
||||
Your day-to-day life as a data scientist or business analyst depends on the size of your company and team, industry, and project focus. I’ll break down the primary responsibilities of both fields to give you a clearer picture.
|
||||
|
||||
What are the key responsibilities of a data scientist?
|
||||
A data scientist analyzes complex data to extract insights, build predictive models, and support data-driven decision-making.
|
||||
|
||||
**Primary tasks:**
|
||||
|
||||
- **Business understanding**: Understand the why behind what you're building. You'll often work with stakeholders to define project and business requirements that guide data usage and model development.
|
||||
- **Data ingestion**: Gather raw data from systems. This data is obtained from databases, APIs, IoT sensors, Excel sheets, etc. A data scientist collects all the relevant data needed to solve the current business problem.
|
||||
- **Data processing, migration, and storage**: You'll spend most of your time cleaning, transforming, and migrating structured and unstructured raw data. The goal is to convert data into suitable formats and structures for analysis and accessibility.
|
||||
- **Data analysis**: Data scientists identify patterns in data behavior using visualization tools and statistical techniques such as Bayesian Inference, A/B testing, and K-means clustering.
|
||||
- **Building machine learning models**: You'll define the appropriate modeling approach based on business objectives, data characteristics, and analytical requirements. Then, you'll build, train, validate, and fine-tune the model using historical data to predict future trends or automate workflows. Depending on the use case, you may also leverage pre-trained models or transfer learning for faster deployment.
|
||||
- **Deploying and testing predictive models**: You'll test your model against business requirements and deploy it to production.
|
||||
- **Reporting**: You also need to present model results to stakeholders using visualizations and clear, concise explanations.
|
||||
|
||||
Data scientists collaborate closely with data engineers to build data extraction and transformation pipelines. You'll also work with business analysts and other stakeholders to set business requirements and align the model with them.
|
||||
|
||||
You'd perform these responsibilities using tools like TensorFlow, Pandas, Jupyter Notebooks, Scikit-learn, Apache Spark, Hadoop, [Docker](https://roadmap.sh/docker), [GitHub/Git](https://roadmap.sh/git-github), SQL, Tableau, and cloud platforms ([AWS],(https://roadmap.sh/aws) Google Cloud, Azure)
|
||||
|
||||
### What Are the Key Responsibilities of a Business Analyst?
|
||||
|
||||
As a business analyst, you'll bridge the gap between business needs and technical solutions by analyzing data and processes and using these insights to drive strategic decisions. Your primary tasks involve:
|
||||
|
||||
- **Data manipulation and analysis**: While business analysts don't need to be expert programmers, you need SQL and Excel for querying databases and lightly analyzing unstructured and structured data. Some business analysts also pick up Python for deeper analysis.
|
||||
- **Business acumen**: You'd need to know how to perform holistic business analysis. This involves asking the right questions: How can I solve business problems with data? What processes benefit from data-driven insights? Do I have the right data? How can I start collecting this data? Understanding how different departments (marketing, sales, finance) operate is necessary to align data insights with business goals.
|
||||
- **Data visualization and reporting**: You'll create interactive dashboards and reports using visualization tools like Tableau, Power BI, and Google Data Studio.
|
||||
- **Communication and stakeholder management**: You'll be involved in clearly communicating complex data insights and providing simple and actionable business recommendations. You'll often present findings to executives who may have little or no technical skills.
|
||||
|
||||
As a business analyst, you'll perform these responsibilities using Tableau, Power BI, Salesforce, Excel, Google Analytics, [SQL](https://roadmap.sh/sql), Microsoft Power BI, Google Sheets, and Looker.
|
||||
|
||||

|
||||
|
||||
## Career Prospects: What Paths Are Available to You?
|
||||
|
||||
When choosing a path, I found it helpful to learn about the diverse and promising career options in each field.
|
||||
|
||||

|
||||
|
||||
### Data Science Career Paths
|
||||
|
||||
If data science is your focus, you have several options, but I'll focus on the three leading fields: data science, machine learning engineering, and artificial intelligence.
|
||||
|
||||
#### Data Scientist
|
||||
|
||||
This role involves developing machine learning algorithms, analyzing large datasets, and extracting actionable insights to support business decision-making. You'll work with structured and unstructured data, applying statistical methods and algorithms to uncover patterns, predict trends, and solve complex problems.
|
||||
|
||||
According to [Indeed](https://www.indeed.com/career/data-scientist/salaries), the average annual salary for a data scientist in the U.S. is $125,639, with a range between $79,587 and $198,339.
|
||||
|
||||

|
||||
|
||||
#### Machine Learning Engineer
|
||||
|
||||
Machine learning engineers design, optimize, and deploy machine learning algorithms in production environments. Unlike data scientists, you'll specialize in software engineering, ensuring models are scalable, efficient, and seamlessly integrated into real-world applications.
|
||||
|
||||
According to [Indeed](https://www.indeed.com/career/machine-learning-engineer/salaries?), Machine Learning Engineers earn an average salary of $163,390 per year in the U.S.
|
||||
|
||||

|
||||
|
||||
#### AI Specialist
|
||||
|
||||
AI specialists develop AI-driven solutions, lead artificial intelligence research, and manage business initiatives.
|
||||
|
||||
According to [Glassdoor](https://www.glassdoor.co.uk/Salaries/ai-specialist-salary-SRCH_KO0%2C13.htm?countryRedirect=true), the average salary for an AI Specialist in the U.S. is $134,500 per year.
|
||||
|
||||

|
||||
|
||||
A computer science or mathematics or data science/AI master's degree or PhD is often desired for data science career paths.
|
||||
|
||||
### Business Analytics Career Paths
|
||||
|
||||
If you choose business analytics instead, several career paths are available, but I'll discuss three leading ones: business analyst, business intelligence analyst, and operations analyst.
|
||||
|
||||
#### Business Analysts
|
||||
|
||||
In this role, you'll get to interpret data, identify business trends, and recommend strategies to optimize performance. You'll also work closely with stakeholders to assess business challenges and use data to drive process improvements and cost-saving measures.
|
||||
|
||||
According to [Indeed](https://www.indeed.com/career/business-analyst/salaries?), the average salary for a business analyst in the U.S. is $85,000 per year, with potential earnings exceeding $100,000 for senior-level professionals.
|
||||
|
||||

|
||||
|
||||
#### Business Intelligence Analysts
|
||||
|
||||
This role focuses on data visualization, reporting, and trend analysis. Working in this role involves developing dashboards, creating reports, and helping organizations monitor performance metrics in real-time.
|
||||
|
||||
According to [Indeed](https://www.indeed.com/career/business-intelligence-analyst/salaries?), Business intelligence analysts in the U.S. earn an average salary of $97,872 per year, with top earners making over $130,000.
|
||||
|
||||

|
||||
|
||||
#### Operations Analysts
|
||||
|
||||
Operations analysts focus on optimizing business workflows, improving efficiency, and reducing operational costs through data-driven analysis. This role is common in industries like logistics, finance, and retail, ensuring processes run smoothly and profitably.
|
||||
|
||||
According to [Indeed](https://www.indeed.com/career/operations-analyst/salaries?), the average salary for an operations analyst in the U.S. is $74,648 per year, with potential earnings exceeding $100,000 in industries like finance and technology.
|
||||
|
||||

|
||||
|
||||
Business analytics admission requirements for those interested in this field often include a bachelor's degree in business, economics, mathematics, or a related field, along with proficiency in statistics, data interpretation, and business intelligence tools.
|
||||
|
||||
## Why Choose One Over the Other?
|
||||
|
||||
I chose data science because I have loved mathematics since my early school years, and anything AI gives me life.
|
||||
|
||||
As I mentioned earlier, if you enjoy coding, solving technical and mathematical problems, and developing data-driven solutions, data science might be the right path for you—especially if AI, machine learning, and big data interest you. This field focuses on building models, algorithms, and predictive systems to extract meaningful insights from data.
|
||||
|
||||
On the other hand, if you prefer interpreting data, identifying trends, and using insights to drive strategic business decisions, business analytics is a better fit. This path is ideal for those who enjoy working closely with stakeholders to solve real-world business problems through data-driven strategies.
|
||||
|
||||
If you're still unsure, experimenting with small projects in both fields can help you determine which excites you more. Sometimes, hands-on experience is the best way to find the right path. Also, some business analytics programs focus on ML, allowing you to explore both fields simultaneously.
|
||||
|
||||
## Next Steps?
|
||||
|
||||
Once you've chosen between data science and business analytics, the best thing you can do is stop second-guessing and start learning. Follow our [Data Scientist Roadmap](https://roadmap.sh/ai-data-scientist) as your step-by-step guide from beginner to expert, tracking your progress along the way.
|
||||
|
||||
You can also start with [Python](https://roadmap.sh/python), explore data analysis, and learn machine learning basics. But, if your preference is business analytics, master Excel, learn visualization tools like Tableau or Looker, and practice creating dashboards.
|
||||
|
||||
The roadmap also helps you schedule learning time and block study time on your calendar to stay consistent. For a detailed overview of any specific role, join the [Discord community](https://roadmap.sh/discord) and stay informed!
|
||||
@@ -1,166 +0,0 @@
|
||||
---
|
||||
title: 'Data Science vs. Computer Science: Which Path to Choose'
|
||||
description: 'Data science or computer science? Learn the tools, roles, and paths in each field to decide which fits your strengths and career goals.'
|
||||
authorId: ekene
|
||||
excludedBySlug: '/ai-data-scientist/vs-computer-science'
|
||||
seo:
|
||||
title: 'Data Science vs. Computer Science: Which Path to Choose'
|
||||
description: 'Data science or computer science? Learn the tools, roles, and paths in each field to decide which fits your strengths and career goals.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-vs-computer-science-rudoc.jpg'
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2025-02-06
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
If you love uncovering patterns in data and using those insights to solve real-world problems, [data science](https://roadmap.sh/ai-data-scientist) might be the right fit for you. On the other hand, if you're drawn to creating systems, writing code, and building the tools that power today's technology, [computer science](https://roadmap.sh/computer-science) could be your path.
|
||||
|
||||
From my experience working on projects in both fields, I've seen how they overlap and where they differ. As a data scientist, you'll focus on analyzing complex data using math, programming, and problem-solving skills. Your work might include building models to extract meaningful insights from data, enabling you to identify patterns, predict trends, detect fraud, or improve recommendations.
|
||||
|
||||
Computer science, in contrast, focuses on understanding how computing systems work. You'll write code, design algorithms, and develop programs to solve problems. You might create web applications and software tools or even dive into artificial intelligence and cybersecurity.
|
||||
|
||||
Although these fields overlap in areas like programming, they cater to different interests and career goals. In this guide, I'll walk you through what each field involves, the skills you need, and the opportunities they offer. By the end, you'll have the clarity to make an informed choice about your future based on which path suits you best.
|
||||
|
||||
## Data science vs. computer science: What are the key differences?
|
||||
|
||||
First, let's look at this table that summarizes the differences. Then, we'll discuss each one in more detail.
|
||||
|
||||
| Characteristics | Data science | Computer science |
|
||||
| ----------------------------- | -------------------------------------------------------------------------- | -------------------------------------------------------------------------- |
|
||||
| Primary focus | Extracting insights from data | Building computer systems to perform tasks |
|
||||
| Industries | Finance, healthcare, marketing, e-commerce | cybersecurity, gaming, education |
|
||||
| Career paths | Data analysts, data scientists, machine learning engineers, data engineers | Software engineers, computer scientists, cybersecurity analyst |
|
||||
| Key areas and specializations | Machine learning, data mining, data visualization, statistical analysis | Data structures, software development, artificial intelligence |
|
||||
| Tools and technologies | Python (Pandas, NumPy), R, SQL, TensorFlow | Python, Java, C++, JavaScript, Git, Vs code, databases (MySQL and MongoDB) |
|
||||
| Educational background | Mathematics, economics, computer science, data science, physics | computer science, mathematics, electrical engineering |
|
||||
|
||||
**Your primary focus**
|
||||
The big difference between data science and computer science is their primary focus. If you choose data science, your role will involve extracting insights and helpful information from datasets. You'll use different tools and techniques to interpret and analyze data. The aim is to help businesses make data-driven decisions. Netflix, for example, uses machine learning and data science to learn your viewing history. Data scientists then analyze data to predict what shows you'll like and suggest movies.
|
||||
|
||||
In contrast, if you choose computer science, you'll focus on building computer systems to perform tasks. You'll create tools that make computers, web apps, data analysis, etc, work better. For example, a company like Google uses computer science to create algorithms that make search engines work. Computer scientists then create software systems and algorithms that will give you accurate results when you search online.
|
||||
|
||||
**Your career path**
|
||||
Computer science and data science have very different career paths. As a data science professional, you'll use data to help make decisions and solve business problems. You'll work in various industries, like finance and healthcare, and take on roles such as:
|
||||
|
||||
- **Data analyst**: Collect and analyze data to help businesses make intelligent decisions. For example, as a data analyst in healthcare, you would use data analysis to know which treatments work best for a specific illness.
|
||||
- **Data scientists**: Build predictive models to predict outcomes. As a data scientist in finance, you'll use data analysis to forecast how the stock market might go.
|
||||
- **Data engineers**: Build and maintain data systems that enable data analysis.
|
||||
- **Machine learning engineer**: Design and build machine learning models to solve everyday problems. As a machine learning engineer at a robotic car company, you'll create models to spot people, roads, traffic lights, and other cars. You'll be responsible for designing machine learning algorithms to help the car make fast decisions.
|
||||
|
||||

|
||||
|
||||
In contrast, as a computer science professional, you'll build the tools data engineers use to get work done. You'll also work in different industries, such as cybersecurity and gaming, and take on roles like:
|
||||
|
||||
- **Software engineers**: Build and maintain software systems, including gaming platforms like Steam.
|
||||
- **Computer scientists:** Study computer systems' theoretical and practical aspects to create applications.
|
||||
- **Cybersecurity analyst**: Monitor and address possible security threats like data breaches.
|
||||
|
||||
**Your key areas** **of** **specialization**
|
||||
Data science focuses on machine learning, data mining, statistical analysis, and more**.** As a data scientist, you'll use these specializations to understand trends and make better decisions.
|
||||
|
||||
In contrast, computer science focuses on artificial intelligence, [data structures](https://roadmap.sh/datastructures-and-algorithms), and software development. As a computer scientist, you'll study these fields to create the tools that data scientists use.
|
||||
|
||||
**The** **tools and technologies** **you'll** **use**
|
||||
Choosing data science requires using different tools and technologies to manipulate data. These tools include machine learning libraries **(TensorFlow)** and languages like [**Python**](https://roadmap.sh/python) **and R**. Python libraries like Pandas will help you with data manipulation and NumPy for math calculations. As a data scientist, you'll also use big data technologies like Hadoop to work with huge amounts of data.
|
||||
|
||||
On the other hand, computer science focuses on software development. As a computer scientist, you'll use programming languages like [Python](https://roadmap.sh/python), [C++](https://roadmap.sh/cpp), and [JavaScript](https://roadmap.sh/javascript) to create different web applications. You'll also use tools like [React](https://roadmap.sh/react), [Git](https://roadmap.sh/git-github), databases **(MySQL and** [**MongoDB**](https://roadmap.sh/mongodb)**)**, and IDEs **(VS code)** to write and test codes.
|
||||
|
||||
## What education do you need for computer and data science careers?
|
||||
|
||||
Getting a computer science degree gives you a solid foundation for software development. It will help you understand computer science principles and how to code and solve issues. Examples of these principles include programming languages, data structures, and operating systems. As a computer science graduate, you'll have a strong foundation that will help you land various tech jobs.
|
||||
|
||||

|
||||
|
||||
Many universities offer specializations in data science within their computer science programs. Others treat data science as a separate program, recognizing it as a field in its own right. They teach you all about machine learning, data visualization, statistics, and more. These data science programs combine ideas from computer science, mathematics, and other fields. At the end of the program, you'll get a data science degree and the necessary skills to get a tech job.
|
||||
|
||||
Studying at a university is not the only way to get a data and computer science education. Many computer science students and aspiring data scientists attend boot camps and learn via certifications or online tutorials. For instance, you can find many [data science courses](https://roadmap.sh/ai-data-scientist) on [roadmap.sh](http://roadmap.sh) and learn at your own pace.
|
||||
|
||||
Learning this way is more flexible and can work with all kinds of schedules and ways of learning. For instance, you can juggle work and study at the same time, which is much harder to do when you study at a university. If you go for a traditional degree like a data science degree, you'll need to invest more time, but you'll get a broad education.
|
||||
|
||||
With these educational paths in mind, a common question arises: **D\*\***o you need a computer science degree to pursue a career in data science?\*\* The answer is a simple no.
|
||||
|
||||
A computer science degree is not always required for computer and data science positions. It can help you start your career in data science, for example, by giving you a solid programming foundation. However, you can study other fields like mathematics, physics, and economics and still be a successful data scientist. You can also go through boot camps and online tutorials on data analysis, machine learning, and data visualization to gain the necessary skills.
|
||||
|
||||
Also, having some practical skills and constant practicing will give you more experience. When practicing, work on personal and open-source projects and build your portfolio to increase your chances of getting a job. Create time to attend meetups and [join online communities](https://discord.com/invite/cJpEt5Qbwa) to chat with other professionals.
|
||||
|
||||
## What are the essential skills you'll need?
|
||||
|
||||
Computer science and data science have a broad range of specialized skill sets. Some of these skills are relevant in both fields, and others are unique.
|
||||
|
||||

|
||||
|
||||
Even though computer science and data science are not the same, they do have some skills in common. These shared skills make it easy to switch between the two fields. Yes, it's true; you can transition from computer to data science and vice versa. The following are some examples of these shared skills:
|
||||
|
||||
- **Programming skills**: Programming skills are a crucial common ground for both fields. Knowing how to code to solve problems as a computer or data scientist is important. The process involves learning programming languages like [Python](https://roadmap.sh/python), having a deep understanding of data structures, and more. It lets you do software development **(computer science)** or data manipulation **(data science)**. However, it is worth noting that some tasks, like data visualization, do not require coding.
|
||||
- **Solving problems:** As a computer or data scientist, it is important to be able to solve problems. This helps you to create software, fix errors, and understand data.
|
||||
- **Mathematics and statistics**: Knowledge of mathematics and statistics will help you to solve problems in both fields. Computer science uses math principles in areas like algorithms and data structures. They will help you as a computer scientist make fast and better software and solve coding issues. As a data scientist, you use statistics to analyze data and machine learning.
|
||||
|
||||
### What skills do you need for computer science?
|
||||
|
||||
- **Programming languages:** Computer scientists use programming languages to give instructions to computers**.** Knowing one or more of these programming languages **(JavaScript, Java, etc.)** will help you to be successful in this field.
|
||||
- **System architecture:** Knowledge of system architecture will help you build reliable computer systems**.**
|
||||
- **Software development methodologies:** Software methodologies help you to plan and manage software projects. These methodologies **(agile, scrum, etc.)** will help you collaborate better with others when creating software.
|
||||
|
||||
### What skills do you need for data science?
|
||||
|
||||
- **Machine learning techniques**: Machine learning techniques are important skills in data science. A deep understanding of machine learning techniques will help you build prediction models. Among the many examples of these techniques are clustering and decision trees. They allow computers to make predictions and recognize patterns without instructions from anyone.
|
||||
- **Data analytics:** To get into the data science field, you must know data analytics. It is the starting point for many data science tasks, e.g., building machine learning models. Data analytics allows you to understand data, find patterns, and draw conclusions.
|
||||
- **Data visualization techniques**: These help present data results in clear visual stories. As a data scientist, they allow you to show patterns that might be hard to see in raw numbers in pictures or graphs. You do this using tools like Tableau, Matplotlib, or Power BI. Some examples of these techniques include bar charts, histograms, and scatter plots.
|
||||
|
||||
## How to choose between data science and computer science
|
||||
|
||||
Let's get into the details to help you decide which field fits you best. Choosing between both fields involves understanding your strengths, interests, and the job market.
|
||||
|
||||

|
||||
|
||||
**Your strengths and educational background**
|
||||
The path you choose boils down to what you're into, what you're good at, and your educational background. Computer science might be a good fit if you're into how computers work and creating software systems. An academic background in computer science or engineering also makes you a good fit.
|
||||
|
||||
If you like finding hidden patterns in data and solving problems, then data science could be for you. You'll also be a good fit if you've studied mathematics, economics, or computer science.
|
||||
|
||||
**Earning potential and industry demand**
|
||||
Many people ask: **Which pays more, data science or computer science?** Well, both fields pay high salaries and are in high demand in the industry.
|
||||
|
||||
Data scientists are in high demand across various sectors, like healthcare and finance. [According to Indeed](https://www.indeed.com/career/data-scientist/salaries?from=top_sb), the average salary for a data scientist in the United States (USA) across all industries is **$123,141.**
|
||||
|
||||

|
||||
|
||||
Computer science professionals like software engineers and software developers are also in demand. [According to Indeed](https://www.indeed.com/career/computer-scientist/salaries?from=top_sb), computer scientists in the USA make around $121,452 a year on average.
|
||||
|
||||

|
||||
|
||||
How much money you earn can depend on where you live, your field, and your skills. roadmap.sh provides [computer](https://roadmap.sh/computer-science) and [data science](https://roadmap.sh/ai-data-scientist) resources to help you improve in both fields.
|
||||
|
||||
## FAQ: Data science or computer science?
|
||||
|
||||
The following are answers to common questions to help you start your career as a computer and data scientist.
|
||||
|
||||

|
||||
|
||||
**Is data science harder than computer science?**
|
||||
Data science and computer science are challenging fields in their different ways. So, it is difficult to say one field is harder than another. The difficulty level varies based on personal viewpoints, interests, and capabilities.
|
||||
|
||||
**Is data science still in demand in 2025?**
|
||||
Yes, data science is still in demand in 2025. [The US Bureau of Labor Statistics](https://www.bls.gov/ooh/math/data-scientists.htm#:~:text=in%20May%202023.-,Job%20Outlook,on%20average%2C%20over%20the%20decade.) predicts a 36% increase in data science jobs from 2023 to 2033.
|
||||
|
||||
**How long does it take to complete most computer science programs?**
|
||||
Computer science programs like a bachelor's degree often take four years to complete. Master's programs take one to three years, depending on your pace or the school. Bootcamps and online certifications, however, may take less time.
|
||||
|
||||
**Is data science more focused on mathematics or computer science?**
|
||||
Both fields are important parts of data science—you can't have one without the other! It uses statistics and mathematical concepts to analyze data and computer science for handling data and building models. The balance may vary depending on the specific role, project, or focus within data science.
|
||||
|
||||
## What Next?
|
||||
|
||||
Deciding between data science and computer science does not need to be a difficult task. Figure out what works best for you by thinking about what you like, what you're good at, and what you want to achieve.
|
||||
|
||||
Also, you don't have to limit yourself to just one field. Many people use data and computer science skills to solve problems daily. So, it is very normal to be good in both fields.
|
||||
|
||||
However, if you're a beginner, focus on improving at one before learning another. [roadmap.sh](http://roadmap.sh) provides roadmap guides for you to learn [computer](https://roadmap.sh/computer-science) and [data science](https://roadmap.sh/ai-data-scientist). Both roadmaps contain resources and everything you need to get started.
|
||||
@@ -1,181 +0,0 @@
|
||||
---
|
||||
title: "Data Science vs. Cyber Security: Which Is Best for You?"
|
||||
description: "Cyber security fights threats. Data science uncovers insights. If you're deciding between them, here's a practical guide based on skills, job roles, and career growth."
|
||||
authorId: ekene
|
||||
excludedBySlug: '/ai-data-scientist/vs-cyber-security'
|
||||
seo:
|
||||
title: "Data Science vs. Cyber Security: Which Is Best for You?"
|
||||
description: "Cyber security fights threats. Data science uncovers insights. If you're deciding between them, here's a practical guide based on skills, job roles, and career growth."
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-vs-cybersecurity-xjcfh.jpg'
|
||||
isNew: true
|
||||
type: 'textual'
|
||||
date: 2025-04-14
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Data science and cyber security are two of the most in-demand career options in IT. Both career paths deal with analyzing complex data and come with various challenges. For beginners, a structured learning path in [data science](https://roadmap.sh/ai-data-scientist) or [cybersecurity](https://roadmap.sh/cyber-security) can be a great starting point. However, if you already have good knowledge of both fields but find it difficult to choose the right one for your career, this guide will definitely help.
|
||||
|
||||
If you want to analyze large volumes of data and uncover deep insights, data science is a great fit for you. On the other hand, if you are passionate about protecting digital assets, preventing cyber threats, and ensuring information security, cyber security might be the better path for you.
|
||||
|
||||
Data science vs. cyber security is a common debate among tech professionals when choosing a career path, as both fields offer high salaries, strong career growth, and essential roles in modern businesses. This results in confusion among career switchers and younger graduates struggling with the choice of cyber security or data science. So, let's compare the two based on these factors to make it easier for you to choose a career path.
|
||||
|
||||
In this guide, you'll learn the job responsibilities of cyber security and data science, the required skills, and career prospects.
|
||||
|
||||
## Differences between data science and cyber security
|
||||
|
||||
The following table provides a quick comparison between cyber security and data science.
|
||||
|
||||
| | **Data Science** | **Cyber Security** |
|
||||
| ---------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Key role** | Data Scientists use computer science and statistical analysis and organizational data to analyze and solve complex business problems. | Cyber security professionals use security tools, networking fundamentals, and incorporate risk management strategies to prevent security breaches and threats. |
|
||||
| **Industries** | Healthcare, technology, finance. | Software and SaaS companies, healthcare, government, etc. |
|
||||
| **Tools** | TensorFlow, Pandas, Jupyter Notebooks. | Firewalls, SIEM systems, intrusion detection tools, and encryption software. |
|
||||
| **Skills** | Expertise in programming, machine learning skills, statistics, data visualization, big data, natural language processing, data manipulation and data wrangling. | Knowledge of security protocols, networking fundamentals, risk management skills, incident response, penetration testing and ethical hacking. |
|
||||
| **Career paths** | Data scientists, machine learning engineer, AI analysts, data engineer, data analyst. | Security analyst, cyber security engineer, information security manager, network engineer, security auditor. |
|
||||
| **Salary range** | For the data science field, the salary ranges from $53,925 to $161,715 per year. | For cyber security professionals, the salary ranges from $91,123 to $136,104 per year. |
|
||||
|
||||
## What are data science and cyber security?
|
||||
|
||||
Data science is a multidisciplinary field focused on extracting knowledge and insights from data to solve business problems. It involves statistical methods, programming, machine learning, data analytics. and domain expertise to build models and analyze structured and unstructured data while ensuring data integrity. This field is widely applied across industries such as healthcare, tech, and finance.
|
||||
|
||||
Cyber security, on the other hand, focuses on protecting data and systems from cyber threats and unauthorized access. As a cybersecurity professional, you will use firewalls, intrusion detection systems, and encryption to secure systems and data while maintaining data integrity. Cyber security is crucial in software companies, SaaS platforms, healthcare, and government sectors.
|
||||
|
||||
Despite their differences, both data science and cyber security rely on data. For example, if you work as a data scientist in an eCommerce company, you may analyze consumer related data to recommend products and drive sales. If you are a cyber security expert in the same company, your job will be to detect and prevent fraud by analyzing transaction patterns for suspicious activity. While data science focuses on using secure data to generate insights, cybersecurity relies on large datasets to identify threats and vulnerabilities.
|
||||
|
||||
As data grows in volume and importance, the demand for data scientists and cyber security professionals will continue to rise. If you're considering a career in either field, you'll find plenty of opportunities.
|
||||
|
||||
Now, let's look at the skills you need to get started in each field.
|
||||
|
||||
## Data science vs. cyber security: Skills and tools required for each field
|
||||
|
||||
The data science role generally involves building predictive models based on the analyzed datasets, data cleaning, and visualizations. Cyber security, on the other hand, involves tasks like monitoring systems and performing risk assessments to protect digital assets.
|
||||
|
||||

|
||||
|
||||
Let's go into detail and explain the different skill sets and tools that aspiring data scientists and cyber security experts must have.
|
||||
|
||||
### Skills and tools for data science
|
||||
|
||||
The process of extracting data, which encompasses both structured and unstructured information, requires fundamental skills and tools that can handle the initial analysis and management challenges effectively. If you're preparing for a data science job, you must have the technical skills to perform analyses and the interpersonal skills to communicate your findings effectively to stakeholders and team members.
|
||||
|
||||
Some of the key skills an interviewer looks for in a data scientist profile include:
|
||||
|
||||
- **Expertise in programming languages:** A certified data scientist must be good at different programming languages, including [Python](https://roadmap.sh/python), R, SAS, and [SQL](https://roadmap.sh/sql). You must know the basics of these languages to sort, analyze, and manage large datasets easily.
|
||||
- **Machine learning skills:** You should be able to sort and synthesize data while making better predictions based on your collected data. Additionally, you should be able to implement appropriate algorithms to solve complex problems.
|
||||
- **Statistics:** The data scientist's role involves to build models based on analysis and draw actionable insights. You must know how to use statistical analysis concepts like probability distribution and linear regression to write high-quality models and algorithms for your project.
|
||||
- **Data visualization:** Apart from analyzing data, you must also learn skills on how to represent your work to stakeholders. So, to create charts and graphs, you must know how to use data visualization tools like Tableau and Power BI.
|
||||
- **Data wrangling:** Expertise in techniques like cleaning and organizing complex data and pattern recognition to ease the analysis process.
|
||||
|
||||
If you're applying for a data science role, you should have expertise in tools such as TensorFlow, Pandas, Jupyter Notebooks, and Tableau.
|
||||
|
||||
### Skills and tools for cybersecurity
|
||||
|
||||
As a cyber security expert, you must have the technical expertise and skills to identify and respond to threats in real time.
|
||||
|
||||
You must excel in the following cyber security skills and tools to qualify for different career opportunities within the cyber security field:
|
||||
|
||||
- **Networking:** You must deeply understand network protocols, operating systems, security concepts, and architectures to assess vulnerabilities before attackers exploit systems.
|
||||
- **Risk management:** Expertise in managing and mitigating cyber security risks is essential. These skills allow you to better assess the likelihood and impact of incoming known threats.
|
||||
- **Ethical hacking:** As an ethical hacker, you'll use the same tools and techniques as malicious hackers but with permission from the system owner. By knowing how they act and their strategies, you can improve your network security and overall security posture.
|
||||
- **Knowledge of security protocols:** A strong understanding of the various security protocols, like encryption protocols, network security protocols, authentication protocols, etc., is a must.
|
||||
|
||||
In addition, you must know how to use firewalls, security information and event management (SIEM) systems, intrusion detection tools, and encryption software to qualify for different career options in cybersecurity. Managing data security is not a simple task; it requires a sharp mind and analytical thinking to beat cyber threats and respond to security breaches.
|
||||
|
||||
Let's move forward to learn about the salary range for each job position to make it easier for you to compare and select based on your requirements.
|
||||
|
||||
## Career opportunities and salary insights
|
||||
|
||||
As more businesses use data to make decisions, the demand for data science professionals is high among different industries. Cyber security experts are also in constant demand with the introduction of new and advanced technologies like artificial intelligence (AI) and cloud computing.
|
||||
|
||||

|
||||
|
||||
Let's investigate the salary insights and career options available in both fields to identify your area of interest.
|
||||
|
||||
### Data science career paths and salary insights
|
||||
|
||||
Planning to proceed with the data science field? If yes, the following career options are available for consideration:
|
||||
|
||||
- Data scientist
|
||||
- Machine learning engineer
|
||||
- AI specialist
|
||||
|
||||
**Data scientist:** In this role, you'll find patterns in complex datasets, create algorithms and data models, deploy data tools, perform data analysis, and predict solutions to stakeholders based on the analysis. You can incorporate machine learning and deep learning practices to improve data quality and predict outcomes. As a data scientist, you must have a good command of your communication skills apart from technical skills and statistical modeling expertise.
|
||||
|
||||
The average salary of an employee pursuing a career as a senior data scientist in the United States is $123,069 per year.
|
||||
|
||||
**Machine learning engineer:** If you apply for this position, your task will be to research and build machine learning algorithms and artificial intelligence systems. Machine learning professionals are also responsible for optimizing frameworks and performing statistical analysis.
|
||||
|
||||
The average salary for this job role in the United States ranges around $161,715 annually.
|
||||
|
||||
**AI specialist:** Your role as an AI specialist is to develop and optimize AI systems. Hence, ensure you know the basics of AI concepts and programming. In addition, you might be responsible for AI system integration, designing AI strategies, and reinforcement learning.
|
||||
|
||||
According to ZipRecruiter, the average salary for an AI Specialist in the United States is $53,925 a year.
|
||||
|
||||
Data engineer, data analyst, and data architect are a few more job roles within data science that you can apply for.
|
||||
|
||||
### Cyber security career paths and salary insights
|
||||
|
||||
If you have an interest in cybersecurity, you can choose from the following career path options:
|
||||
|
||||
- Security analyst
|
||||
- Cyber security engineer
|
||||
- Information security manager
|
||||
|
||||
**Security analyst:** As a Cyber security analyst, your main role is to identify and troubleshoot problems within security systems and protect sensitive data. Security analyst professionals monitor systems and perform compliance control testing to minimize security risks. Based on their analysis, you can also recommend reducing risk and securing systems.
|
||||
|
||||
According to Indeed, the average salary of a cyber security analyst in the United States is $91,123 per year.
|
||||
|
||||
**Cyber security engineers:** Cyber security engineers are the front warriors who design and configure solutions against cyber criminals. You will have to act as an ethical hacker to strategize and identify vulnerabilities before attackers exploit them.
|
||||
|
||||
ZipRecruiter states that the average salary of an employee pursuing a career in this position in the United States is $122,890 per year.
|
||||
|
||||
**Information security manager:** In this role, your main focus will be on developing and implementing security policies. You will also handle incident response plans, threat monitoring, and the implementation of security best practices for protecting computer systems.
|
||||
|
||||
According to ZipRecruiter, the average salary of a Certified Information Security Manager in the United States is $136,104 per year.
|
||||
|
||||
Let's dive in and take a closer look at the work environment in both fields to help you decide which one is best for you.
|
||||
|
||||
## Work environment differences
|
||||
|
||||
The work environments in data science and cyber security differ significantly, appealing to distinct personalities and work styles.
|
||||
|
||||
Data science typically offers a more collaborative and research-oriented atmosphere. Imagine teams of data analysts, data science professionals, and researchers brainstorming, analyzing historical data, sharing insights, and working together to find solutions for complex datasets.
|
||||
|
||||
Flexibility is often a key feature, both in terms of working hours and location. While deadlines exist in data science, the project-based nature often allows for a more measured pace, with timelines that can stretch over weeks or months. This allows for deep dives into data, thorough data analysis, and the development of sophisticated models.
|
||||
|
||||
You will be more attracted to the data science field if you enjoy intellectual exploration and the satisfaction of uncovering hidden patterns. Data science is great if you like intellectual exploration, problem solving and finding hidden patterns. It's creative and encourages deep analysis of complex problems, so if you like structured but exploratory work, it's a good fit.
|
||||
|
||||
Cyber security, on the other hand, is a high-stakes, fast-paced world. The focus is on real-time threat prevention, monitoring security infrastructure, and rapid response to security incidents.
|
||||
|
||||
Security professionals need to be on high alert, anticipating and countering attacks on systems. It's intense work, with split second decisions and big consequences.
|
||||
|
||||
The nature of cyber security often demands irregular hours, especially during security crises. A major breach can require teams to work around the clock to contain the damage and restore systems. While this can be incredibly demanding, it can also be immensely rewarding for those who thrive in high-pressure situations and enjoy the thrill of the chase.
|
||||
|
||||
Whether you are planning for cyber security or data science, consider all aspects, including the work environment.
|
||||
|
||||
## Cyber security and data science: Which path is best for you?
|
||||
|
||||
It's best to keep your interests, skills, and personality in mind when selecting between cyber security and data science.
|
||||
|
||||

|
||||
|
||||
If you find yourself drawn to the world of data, enjoy the challenge of extracting meaning from raw data, and prefer coding and statistical analysis over other practices, data science might be the right path for you. Do you get excited about building predictive models, uncovering trends, and using data to solve real-world problems? If so, you'll likely find the intellectual challenges of data science stimulating.
|
||||
|
||||
On the other hand, if your passion lies in protecting systems, staying one step ahead of hackers, and responding to high-stakes challenges, cybersecurity could be a more fulfilling career choice. If you love understanding cybercriminals' psychology and preventing them from achieving their goals, this one could be your career goal.
|
||||
|
||||
If you still have questions about cyber security and data science, try taking online courses or doing small projects in each field to find your real interest. You can also work with datasets, experiment with different algorithms, connect with a data engineer, or explore basic cyber security concepts. This hands-on experience will give you valuable insights into your preferences.
|
||||
|
||||
## What's Next?
|
||||
|
||||
Cyber security or data science, whichever path you choose, make sure it fulfills your needs and interests. If working on numbers and models is your thing, data science is the right path for you. However, cyber security could be a better option if you are more inclined toward protecting systems and taking on challenges.
|
||||
|
||||
Choosing between cyber security and data science can be a difficult decision, but this guide has provided key insights to help you evaluate your interests. To further explore your options, check out [cyber security](https://roadmap.sh/cyber-security) and [data science](https://roadmap.sh/ai-data-scientist) roadmaps to gain deeper insights into each field. You can also join online courses and get relevant certifications or connect with our experts on the [Discord community](https://roadmap.sh/discord) to stay up-to-date!
|
||||
|
||||
@@ -1,174 +0,0 @@
|
||||
---
|
||||
title: 'Data Science vs. Data Analytics: Which is Right for You?'
|
||||
description: 'Data science vs. Data analytics? This guide breaks down roles, tools, and growth opportunities for aspiring data professionals.'
|
||||
authorId: william
|
||||
excludedBySlug: '/ai-data-scientist/vs-data-analytics'
|
||||
seo:
|
||||
title: 'Data Science vs. Data Analytics: Which is Right for You?'
|
||||
description: 'Data science vs. Data analytics? This guide breaks down roles, tools, and growth opportunities for aspiring data professionals.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-vs-data-analytics-3ol7o.jpg'
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2025-02-06
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
If you enjoy spotting patterns, analyzing trends, and driving business strategies, a career in [data analytics](https://roadmap.sh/data-analyst) might be your ideal fit. On the other hand, if algorithms, coding, and diving into uncharted territory excite you, a career in [data science](https://roadmap.sh/ai-data-scientist) could be the better path.
|
||||
|
||||
As someone whose work spans both fields and involves managing data to solve business challenges, I've seen how both data science and analytics shape business success.
|
||||
|
||||
Businesses rely heavily on insights, whether streamlining operations, predicting future trends, or crafting innovative strategies. Both data analytics and data science are pivotal to this process, but they approach problems differently.
|
||||
|
||||
As a data analyst, you'll focus on making sense of data through trends, visualizations, and actionable insights. As a data scientist, you'll work on building predictive data models and solving complex problems using advanced machine learning techniques.
|
||||
|
||||
But the big question is: Which path aligns with your goals?
|
||||
|
||||
The answer lies in your interests, strengths, and career aspirations. In this guide, I'll take you through the key differences between data science and data analytics and show you how they complement each other. You'll learn which skills are needed in each role and what career paths and opportunities they offer. By the end, you'll clearly know which role fits you best and how to start building your future.
|
||||
|
||||
The table below summarizes the key differences between data science and data analytics.
|
||||
|
||||
| | **Data Science** | **Data Analytics** |
|
||||
|---------------------|----------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **Key Role** | Uses statistical analysis and computational methods to gain insights from complex, structured and unstructured data. | Analyzes data collected from different sources, generates insights, and makes smart data-driven decisions. |
|
||||
| **Skills** | Machine learning, reinforcement learning techniques, data wrangling, big data technologies, cloud computing, and predictive analytics. | Proficient in data collection, SQL, knowledge of advanced Excel functions, data visualization, critical thinking, and create visual presentations. |
|
||||
| **Tools** | TensorFlow, PyTorch, Jupyter Notebooks, and GitHub/Git. | SQL, Excel, Tableau, Power BI, OpenRefine or Google Analytics |
|
||||
| **Career Paths** | Data Scientist > Machine Learning Engineer > AI Specialist | Data Analyst > Business Intelligence Manager > Chief Data Officer (CDO) |
|
||||
| **Salary Range** | For data scientist job positions, salary ranges from $119,040 to $158,747 per year. | For data analysis job positions, salary ranges from $82,000 to $86,200 per year. |
|
||||
|
||||
## What are data science and data analytics?
|
||||
|
||||
Data science and data analytics are two multidisciplinary fields that share the goal of helping organizations make smarter decisions, but they achieve this in different ways.
|
||||
|
||||
Data science uses advanced tools like machine learning and AI to extract insights from large, complex data sets. As a data scientist, your role is to uncover patterns and build predictive models that solve problems like fraud detection, ad optimization, and trend forecasting. Tools like [Python](https://roadmap.sh/python), Apache Spark, and [SQL](https://roadmap.sh/sql) are key to this work.
|
||||
|
||||
Data analytics, meanwhile, focuses on interpreting existing data to uncover trends and deliver actionable insights. As a data analyst, you'll use data analytics tools like Excel, Tableau, and Power BI to identify patterns, forecast sales, analyze customer behavior, and guide strategy. This work is grounded in understanding what has already happened to influence future business decisions.
|
||||
|
||||
By understanding the distinct purposes of these roles, we can examine how they interact to drive meaningful results.
|
||||
|
||||
## How do data science and data analytics complement each other?
|
||||
|
||||
For example, consider an ecommerce business whose sales have declined over the past quarter. A data analyst would start by examining historical sales data using tools like Excel or SQL to identify patterns and uncover potential causes, such as price changes or shifting customer demographics. These findings would then inform the data science team.
|
||||
|
||||
The data scientists would take this further by building predictive models to analyze future sales trends. They might incorporate additional features, like customer feedback or competitor pricing, to provide proactive recommendations that could reverse the decline, such as adjusting pricing strategies or launching targeted campaigns.
|
||||
|
||||
Therefore, data analytics helps you answer the "**what**,** why**, and **where**" questions. For example, you can use it to ask, "what caused past sales?" or "why did customer churn go up in Q1?" or "where is our main revenue coming from?" By looking at historical data, data analytics gives you the answers you need to improve and build better strategies.
|
||||
|
||||
The data science process takes it a step further by answering the "**why**" and **"how**" questions, like why sales went down and how to fix it. Data science leverages machine learning algorithms and predictive techniques to provide you with the right solutions to move forward.
|
||||
|
||||
Next, explore the specific job roles and responsibilities in data science and data analytics.
|
||||
|
||||
## **Data science vs. data analytics:** **Job role and responsibilities**
|
||||
|
||||
Here are the primary responsibilities that define the role of a data analyst and how they contribute to enabling data-informed business decisions.
|
||||
|
||||

|
||||
|
||||
**Key responsibilities of data scientist**
|
||||
As a data scientist, you'll work on complex tasks, such as building models, designing algorithms, and experimenting with data to uncover unknown outcomes. For example, to predict which customers are likely to cancel their subscriptions, you will analyze past customer behavior using predictive models to identify patterns.
|
||||
|
||||
Here is a quick overview of your key responsibilities as a data scientist:
|
||||
|
||||
- **Data collection and management:** Collect data from many sources, often dealing with structured and unstructured data. Your focus will be on getting the data for analysis, which can be simple to very complex, depending on the problem.
|
||||
- **Build predictive models:** Apply machine learning techniques to predict future behaviors, such as customer churn or sales demand.
|
||||
- **Design algorithms:** Develop new algorithms to optimize business operations, such as fraud detection systems or creating personalized recommendations for customers.
|
||||
- **Data experimentation:** Identify hidden patterns and extract meaningful insights from large and unstructured data sets.
|
||||
|
||||
**Key responsibilities of data analyst**
|
||||
As a data analyst, you focus on understanding structured data to answer specific business queries and make smart decisions. For example, to identify sales trends over the past year, you will perform the following tasks:
|
||||
|
||||
- **Data collection and processing:** Gather information from different sources and remove inaccuracies or unnecessary data. Use data-cleaning method to maintain accuracy and prepare data for analysis.
|
||||
- **Data analysis:** Interpret formatted and cleaned data using statistical tools and advanced modeling techniques.
|
||||
- **Data reporting:** Create clear and concise reports to share with business.
|
||||
- **Business recommendations:** Provide recommendations based on what you found to improve sales, efficiency, and performance.
|
||||
|
||||
Let's dig into the tools and skills needed for your selected job role.
|
||||
|
||||
## **Data science vs. data analytics: Skills and** **tools**
|
||||
|
||||
When you choose between becoming a data analyst or a data scientist, understanding the essential skills and tools for each role is crucial. Both positions demand analytical proficiency, but their technical requirements and focus areas differ significantly.
|
||||
|
||||

|
||||
|
||||
Let's explore the key skills and tools to help you make the right decision.
|
||||
|
||||
**Data scientist skills and tools**
|
||||
As a data scientist, you'll have technical, analytical, and problem-solving skills to handle large and complex datasets. Some of the main skills and tools that interviewers look for are:
|
||||
|
||||
- **Programming skills:** Mastery of Python and R is essential for data science tasks, including statistical analysis and machine learning model development.
|
||||
- **Machine learning expertise:** Knowledge of supervision and reinforcement learning techniques. Additionally, you should have an understanding of algorithms and clustering methods.
|
||||
- **Big data tools:** Hadoop and Apache Spark are a must for distributed storage and big data analysis.
|
||||
- **Mathematics and statistics**: Advanced knowledge of mathematics and statistics is essential for building models and deriving insights.
|
||||
|
||||
You should also focus on mastering tools like [TensorFlow](https://roadmap.sh/cpp/libraries/tensorflow), PyTorch, Jupyter Notebooks, [GitHub/Git](https://roadmap.sh/git-github), SQL, Apache Spark, Hadoop, [Docker](https://roadmap.sh/docker), [Kubernetes](https://roadmap.sh/kubernetes), and Tableau. Data visualization, Scikit-learn, and version control systems are also important for data science.
|
||||
|
||||
**Data analyst skills and tools**
|
||||
As a data analyst, your role focuses on data interpretation for business decisions. Some of the main skills and tool proficiencies you'll need to excel in this role are:
|
||||
|
||||
- **SQL (Structured Query Language):** Knowledge of SQL is necessary for querying, managing and retrieving data from databases.
|
||||
- **Advanced Excel skills:** Strong Excel skills, including pivot tables, VLOOKUP, and data analysis functions, are necessary to organize and analyze data.
|
||||
- **Data visualization:** Ability to create good-looking charts and dashboards using tools like Tableau and Power BI is a must for presenting insights in a clear and effective way.
|
||||
- **Critical thinking:** Strong analytical and critical thinking skills to identify trends and derive meaning from data.
|
||||
|
||||
Check out the [Data Scientist](https://roadmap.sh/ai-data-scientist) and [Data Analyst](https://roadmap.sh/data-analyst) roadmaps for a structured approach. These will help you decide what to learn and where to focus. By following them, you can prioritize what to learn, focus on high-demand areas, and not feel overwhelmed. Also, join local or online meetups to connect with professionals and participate in hackathons to get hands-on experience and add to your portfolio.
|
||||
|
||||
Let's move forward to understand different career trajectories that fall under data science and data analysis. Also, check out the salary ranges for each job profile.
|
||||
|
||||
## **Data science vs. data analytics: Career paths and salary insights**
|
||||
|
||||
If you're looking into data science or data analytics careers, you're entering a field with huge growth. Both have their own focus, but there's a lot of overlap in skills, tools, and methodologies, so it's easier to move between roles or expand your skills across both domains.
|
||||
|
||||

|
||||
|
||||
Here is a quick overview of role transitions, salary ranges, and the steps you can take to advance your career as a data scientist and data analyst.
|
||||
|
||||
**Data science career paths and salary insights**
|
||||
As a data scientist engineer, these are the roles that are typically available to you throughout your career:
|
||||
|
||||
- Data scientist
|
||||
- Machine learning engineer
|
||||
- AI specialist
|
||||
|
||||
**Data scientist:** As a data scientist, you will analyze large datasets, develop predictive data models, and implement algorithms to extract insights. Additionally, you must have knowledge of machine learning basics, structured data, statistical modeling, and communication skills.
|
||||
|
||||
In 2024, the [average salary](https://www.datacamp.com/blog/data-science-salaries) for a data scientist is $123,069 per year in the United States.
|
||||
|
||||
**Machine learning engineer:** In this role, you'll focus on developing and deploying machine learning models in production environments. This role requires technical expertise in software engineering, computer science, big data technologies, and scalable systems. You must have knowledge of advanced machine learning, computer science, cloud computing, and software development lifecycle (SDLC) knowledge.
|
||||
|
||||
According to [Indeed](https://www.indeed.com/career/machine-learning-engineer/salaries), the average salary for a machine learning engineer in the United States is $161,715 per year.
|
||||
|
||||
**AI specialist:** You'll focus on designing cutting-edge AI solutions, managing teams of data professionals, and driving strategic artificial intelligence initiatives for organizations. You even perform research on emerging spot trends and implement AI frameworks.
|
||||
|
||||
According to [Glassdoor,](https://www.glassdoor.co.in/Salaries/us-ai-specialist-salary-SRCH_IL.0,2_IN1_KO3,16.htm) the estimated salary of an AI specialist job profile in the US is $129,337 per year, with an average salary of $105,981 per year.
|
||||
|
||||
**Data analytics career paths and salary insights**
|
||||
If you're leaning towards data analytics, here are some common job titles for you, along with salary details for each role:
|
||||
|
||||
- Data analyst
|
||||
- Business intelligence manager
|
||||
- Chief data officer
|
||||
|
||||
**Data analyst:** This role involves collecting, cleaning, and analyzing data to generate actionable insights. You'll work on dashboards, reporting, and descriptive analytics using tools like Excel and Tableau. Additionally, you must have basic programming knowledge, data visualization, and data mining skills.
|
||||
|
||||
In 2024, the estimated [average salary](https://www.indeed.com/career/data-analyst/salaries) of a data analyst ranges around $80,811 per year depending on experience, location, and specific skills in demand.
|
||||
|
||||
**Business intelligence manager:** As a business intelligence manager, you'll lead data reporting and visualization strategies, manage data accuracy, and design scalable solutions. Communication skills and proficiency in business intelligence tools are key to this role.
|
||||
|
||||
[ZipRecruiter](https://www.ziprecruiter.com/Salaries/Business-Intelligence-Manager-Salary) reported that the salary of a business intelligence manager in the US ranges from $29,500 to $158,500.
|
||||
|
||||
**Chief data officer (CDO):** Responsible for an organization's data strategy, data governance, and data leveraging for competitive advantage. For this job role, you must have the necessary skills, such as data governance, data strategy, data engineering, and management of complex architecture.
|
||||
|
||||
In 2024, the estimated total pay for a chief [data officer](https://www.glassdoor.co.in/Salaries/us-chief-data-officer-salary-SRCH_IL.0,2_IN1_KO3,21.htm) is $373,952 per year in the US.
|
||||
|
||||
## **What** **Next**
|
||||
|
||||
Once you've decided to pursue a career in data science or data analytics, the next step is figuring out where to start. Our [AI-Data Scientist](https://roadmap.sh/ai-data-scientist) and [Data Analyst roadmap](https://roadmap.sh/data-analyst) are designed to help you with that by breaking down the skills, tools and concepts into smaller steps. Whether you are drawn to the complexity of algorithms or analyzing trends, both paths offer rewarding opportunities for personal and professional growth, these roadmaps will give you a clear structure to build a solid foundation and move forward with confidence.
|
||||
|
||||
Remember, the key to success in both fields is a commitment to continuous learning. For detailed overview of any specific role, join the [Discord community](https://roadmap.sh/discord) and stay informed!
|
||||
@@ -1,193 +0,0 @@
|
||||
---
|
||||
title: 'Data Science vs. Data Engineering: Lessons from My Journey'
|
||||
description: 'I’ve worked on both data science and data engineering projects - here’s what I’ve learned and how you can choose the best path for your career.'
|
||||
authorId: ekene
|
||||
excludedBySlug: '/ai-data-scientist/vs-data-engineering'
|
||||
seo:
|
||||
title: 'Data Science vs. Data Engineering: Lessons from My Journey'
|
||||
description: 'I’ve worked on both data science and data engineering projects - here’s what I’ve learned and how you can choose the best path for your career.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-vs-data-engineering-bychp.jpg'
|
||||
isNew: true
|
||||
type: 'textual'
|
||||
date: 2025-03-24
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Many aspiring professionals wonder about the difference between data science and data engineering. Although both fields involve working with data, they focus on different aspects of the data lifecycle.
|
||||
|
||||
When I started my tech career, I was torn between data science and data engineering. I spent weeks researching and experimenting with projects to find where my strengths fit best. Both fields are closely related but yet distinct.
|
||||
|
||||
If you love working with data, solving complex problems, and using data to guide decisions, you should consider [data science](https://roadmap.sh/ai-data-scientist), but if you enjoy building and maintaining data infrastructure and systems, I suggest you consider data engineering.
|
||||
|
||||
In this guide, I will share the key lessons I learned, the challenges I faced, and how you can decide which career is right for you.
|
||||
|
||||
The table below summarizes the differences between data science and data engineering.
|
||||
|
||||
## Differences between data science and data engineering
|
||||
|
||||
| | Data science | Data engineering |
|
||||
| ---------------------- | ------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
| Focus | Analyzing and interpreting data using statistical models, machine learning, and analytics to obtain value and make predictions. | Designing, building, and maintaining data pipelines and infrastructure for data storage and accessibility. |
|
||||
| Skills | Machine learning, statistics, data visualization, and predictive models. | Knowledge of data infrastructure, database management, and cloud tools. |
|
||||
| Tools | Python, R, SQL, Tableau, PyTorch, Power BI, Tensorflow. | Python, Scala, R, Java, Apache Spark, Kafka, Snowflake, Databricks. |
|
||||
| Educational background | Computer science, statistics, and mathematics. | Computer science, computer engineering, and software engineering. |
|
||||
| Career paths | Data scientist, [Data analyst](https://roadmap.sh/data-analyst), Machine learning engineer. | Data engineer, Big data engineer, Data architect. |
|
||||
|
||||
## What is data science and data engineering?
|
||||
|
||||
When I worked on my first data-driven project, I realized how much I enjoyed working with raw data. But I also saw how much effort went into setting up pipelines and structuring data before I could analyze it. That’s when I understood the fundamental difference: Data engineers build the highways, while data scientists drive on them to find insights.
|
||||
|
||||
Data science is a field that combines mathematics, statistics, analytics, artificial intelligence, and machine learning to analyze large amounts of data to detect hidden patterns, generate actionable insights, and predict trends. As a data scientist, you’ll analyze and interpret complex data to help organizations and businesses make informed decisions.
|
||||
|
||||
On the other hand, data engineering involves designing and building systems for aggregating, storing, and analyzing data. As a data engineer, you’ll build data warehouses to empower data-driven decisions. You will focus on developing pipelines to collect, clean, and transform data, ensuring it is accessible for analysis by the data science team.
|
||||
|
||||
## Key responsibilities of a data scientist
|
||||
|
||||
Your responsibilities as a data scientist will vary depending on the industry, company size, and project focus. To provide more context, I will explain the responsibilities of a data scientist using a project I worked on during my career. The project involved customer churn analysis for a client in the hospitality industry.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
1. **Business understanding:** As a data scientist, you’ll work closely with stakeholders to understand the context and gain business insights.
|
||||
In the customer churn analysis project, I worked closely with the client to understand the business context and gain insights. This provided an in-depth understanding of the hospitality sector and the different terms used. Without this, solving the business problem would have been almost impossible.
|
||||
|
||||
2. **Data ingestion:** Your work as a data scientist involves gathering raw data from different sources. It is your responsibility as a data scientist to collect all the relevant data to solve the current business problem.
|
||||
|
||||
When I worked on the customer churn analysis project, I had to pull data from multiple sources (customer transaction logs, website analytics, and CRM tools). But before I could even begin the analysis, the data engineers had to build ETL pipelines to collect and clean this data.
|
||||
|
||||
3. **Data processing and data storage:** This is one of your core responsibilities as a data scientist. It involves cleaning and transforming the ingested data into suitable formats for analysis and saving data storage systems.
|
||||
|
||||
In the customer churn analysis project, the data ingested were unusable and had to be cleaned so they could be used for analysis. I used tools like Python and NumPy to process the data and saved the processed data in a database.
|
||||
|
||||
4. **Data analysis:** As a data scientist, you’ll analyze processed data using statistical analysis and data visualization tools like Matplotlib, Seaborn, and Pandas. You’ll explore the data to understand relationships, hidden patterns, characteristics, and anomalies. You will use charts and graphs to make the data more understandable and easier to comprehend.
|
||||
|
||||
In the customer churning analysis project, I analyzed the data by identifying the number of returning customers, the customers who came only once, the day of the week with the most customers, and so on. With this analysis, I could identify a trend in the data, which helped in predictive model building.
|
||||
|
||||
5. **Model building:** As a data scientist, you’ll build predictive models and machine learning algorithms to forecast future trends. The machine learning algorithms you build can be categorized into two types:
|
||||
- Supervised learning: Examples include linear regression, decision trees, and k-nearest neighbors.
|
||||
- Unsupervised learning: Examples include clustering and dimensionality reduction.
|
||||
|
||||
6. **Reporting:** As a data scientist, it is your responsibility to interpret and communicate the results of data analysis and predictions. It is not enough to analyze and explore the data; you have to communicate them clearly so that the key stakeholders easily understand them, influence decision-making, and achieve business goals.
|
||||
|
||||
## Skills and tools needed to succeed as a data scientist
|
||||
|
||||
To succeed as a data scientist, you need to have a balance of technical and analytical skills. Some of these skills and tools I recommend include:
|
||||
|
||||

|
||||
|
||||
|
||||
1. **Programming languages:** As a data scientist, you should know some programming. The two most common programming languages data scientists use are [Python](https://roadmap.sh/python) and R.
|
||||
|
||||
2. **Mathematics and statistics:** To succeed as a data scientist, you must know mathematics and statistics. They help you understand your data and know which statistical model to apply. Knowledge of mathematical concepts like calculus, probability theory, and linear algebra are fundamental to your success as a data scientist.
|
||||
|
||||
3. **Data visualization:** This involves using graphs, charts, and maps to present data in an understandable and accessible format. It is important to know how to visualize data. Some of the tools used to create visualizations include Matplotlib, Seaborn, ggplot2, and Pandas.
|
||||
|
||||
4. **Database management systems:** Database management systems are applications that interact with users, other applications, and the database to fetch and analyze data. As a data scientist, you will interact a lot with databases, and you should know how to write queries to communicate with them.
|
||||
|
||||
[SQL](https://roadmap.sh/sql) is a programming language used to manage and communicate with relational databases. Examples of relational databases are MySQL, [PostgreSQL](https://roadmap.sh/postgresql-dba), and Microsoft Server SQL. There are also NoSQL databases that store unstructured data. Examples include [MongoDB](https://roadmap.sh/mongodb), Neo4j, and Cassandra.
|
||||
|
||||
5. **Machine learning and artificial intelligence:** As a data scientist, you should have an understanding of machine learning. Machine learning can be divided into supervised, unsupervised, deep, and reinforced learning. Some key tools used by data scientists include Scikit-learn, TensorFlow, and PyTorch.
|
||||
|
||||
## Key responsibilities of a data engineer
|
||||
|
||||
To explain the key responsibilities of a data engineer, I will use an IoT project I worked on to provide more context. The project involved developing an IoT data pipeline to transmit data from a customer’s IoT devices in the field to a storage system. Your key responsibilities as a data engineer include:
|
||||
|
||||

|
||||
|
||||
1. **Data pipeline development:** A data pipeline is a method of ingesting data from different data sources, transforming the data, and then transferring it to storage and processing systems. You are responsible for building and maintaining data pipelines as a data engineer. The different types of data pipelines include:
|
||||
- Batch processing pipelines
|
||||
- Data streaming pipelines
|
||||
- Data integration pipelines
|
||||
- Cloud-native data pipelines
|
||||
In the IoT project, the data engineers designed the data pipeline used to transmit data from the IoT devices to the data storage system. The pipeline was a messaging system into which the IoT devices published data, which was ingested and stored in a database.
|
||||
|
||||
2. **Data architecture design:** As a data engineer, you will build, design, and manage data lakes and warehouses for data storage and retrieval. You will work with cloud platforms ([AWS](https://roadmap.sh/aws), GCP, Azure) to develop scalable and reliable storage solutions.
|
||||
|
||||
3. **Database management:** As a data engineer, you’ll manage and optimize storage solutions, which include relational databases, document databases, and data lakes. These data storage solutions store big data for analysis and prediction for data integrity, performance, and accessibility.
|
||||
|
||||
4. **ETL processes development:** Extract, Transform, Load (ETL) is a process that cleans and organizes data from multiple data sources into a single and consistent data set for storage and further processing. As a data engineer, you are responsible for developing and maintaining the ETL process for proper data integration and onward passage of the data to be used by data scientists.
|
||||
|
||||
The data from the IoT devices was in different formats, so the data engineers had to build an ETL process to transform the data for onward processing and storage.
|
||||
|
||||
5. **Real-time data streaming:** Data engineers process real-time data from different data sources, which can be triggered via events or observers. As a data engineer, you design systems that respond to real-time data, and use tools like Google Publish and Subscribe and Azure Publish and Subscribe to transmit and process it.
|
||||
|
||||
The data sent from the IoT devices was real-time data, and the data engineers built the messaging system that streamed the data.
|
||||
|
||||
6. **Data governance and security:** Data engineers are responsible for compliance with data privacy laws. They implement data validation and integrity checks, which results in clean data and data reliability. They also make sure that sensitive user data is protected and not exposed without sufficient clearance.
|
||||
|
||||
## Skills and tools needed to succeed as a data engineer
|
||||
|
||||
To succeed as a data engineer, you need a combination of programming, data management, data pipelines, and cloud computing skills. I will explain the skills below.
|
||||
|
||||
|
||||
1. **Programming languages:** You should know programming and scripting. Python is one of the most common programming languages you will use as a data engineer. Python is used for data processing, creating ETL pipelines, and automation. Other programming languages used are [Java](https://roadmap.sh/java), [SQL](https://roadmap.sh/sql), and Scala. Bash scripting is also a necessary skill you should have for workflow automation.
|
||||
|
||||
2. **Databases:** As a data engineer, you are expected to know how to design and maintain database management systems. You will use relational databases and NoSQL databases to store and retrieve data. Examples of relational databases include PostgreSQL, MySQL, and Microsoft SQL Server. Examples of NoSQL databases include [MongoDB](https://roadmap.sh/mongodb), [Redis](https://roadmap.sh/redis), and DynamoDB. NoSQL databases are used to store unstructured data.
|
||||
|
||||
3. **Data warehouses:** A data warehouse is a system that gathers data from different sources and stores them in a central location. It help prepare data for data analytics, machine learning, and artificial intelligence.
|
||||
|
||||
As a data engineer, you should know how to work with data warehouses and also design and maintain them. There are cloud-based data warehouses and on-premise data warehouses. Cloud-based data warehouses are provided by cloud platforms and they include Amazon Redshift, Google BigQuery, and Azure Synapse Analytics. Examples of on-premise data warehouses include SAP BW/4HANA and IBM Db2 Warehouse.
|
||||
|
||||
4. **Data lakes:** Data engineers use data lakes to store structured and unstructured data in their original formats. They store various types of data in different formats and provide a central repository for data analysis workloads. Examples of data lakes include AWS S3, Azure Data Lake, and Google Cloud Storage.
|
||||
|
||||
5. **ETL processes:** Data engineers use ETL processes to automate the storage and retrieval of data in a database. The data is extracted from its source, transformed into the required format using automated scripts and programs, and then loaded to its destination. As a data engineer, you should know how to design ETL processes and build data pipelines.
|
||||
|
||||

|
||||
|
||||
## Data scientist vs. Data engineer: What career opportunities are available to you?
|
||||
|
||||
Both professionals are in high demand in several industries, including health care, tech, finance, and retail.
|
||||
|
||||
The typical career path in data science includes:
|
||||
|
||||
- Junior data scientist
|
||||
- Data scientist
|
||||
- Senior data scientist
|
||||
- Machine learning engineer
|
||||
|
||||
The career path of a data engineer is similar to that of a data scientist. A typical data engineering career path includes:
|
||||
|
||||
- Junior data engineer
|
||||
- Data engineer
|
||||
- Senior data engineer
|
||||
- Data architect
|
||||
- Senior data architect
|
||||
|
||||
## Salaries and job market trends
|
||||
|
||||
One thing that surprised me was how salaries vary depending on industry and specialization. In my experience, companies in finance and healthcare tend to pay data scientists more, while big tech firms offer strong compensation for data engineers working on large-scale infrastructure.
|
||||
|
||||
According to Indeed, the average annual [data scientist salary](https://www.indeed.com/career/data-scientist/salaries) in the US is $125,156 with a range between $79,612 and $196,755.
|
||||
|
||||

|
||||
|
||||
The average [data engineer salary](https://www.indeed.com/career/data-engineer/salaries) in the US is $125,758, with a range between $82,340 and $192,069.
|
||||
|
||||

|
||||
|
||||
Both data scientist and data engineer roles are in high demand with the rise in AI. Companies are constantly hiring data scientists and data engineers. On Indeed, there are more than 10,000 openings for data scientists and more than 5,000 in the US alone.
|
||||
|
||||
Data scientists and data engineers will also be very instrumental and in high demand in the future. According to the [US Bureau of Labour Statistics](https://www.bls.gov/ooh/math/data-scientists.htm), there will be 20,800 new openings for data scientists each year for the next decade.
|
||||
|
||||
## Data science vs. Data engineering: Which path fits you better?
|
||||
|
||||
Deciding whether to pursue data science or data engineering depends on your interests, strengths, and career goals.
|
||||
|
||||
If you enjoy solving analytical problems, working with algorithms, and guiding business decision processes, then you should consider data science. Do you enjoy building large-scale systems and data infrastructure and ensuring data pipelines run smoothly? Then, you should consider data engineering.
|
||||
|
||||
Do you understand statistics, mathematics, data analysis, and visualization well? Data science is well-suited for you. Data engineering is the right fit if you have strong programming skills and are knowledgeable in system design and architecture.
|
||||
|
||||
## Next steps
|
||||
|
||||
If I had to start over, I’d begin with small projects. My first real learning moment came when I built a basic recommendation system for movie ratings using [Python](https://roadmap.sh/python) and Pandas. If you're considering data engineering, setting up an ETL pipeline with Apache Airflow is a great starting point. Don't just read—build.
|
||||
|
||||
You should also follow a structured learning path. roadmap.sh provides you a structured [data science](https://roadmap.sh/ai-data-scientist) roadmap where you can track your progress and share it on your profile. You could also customize your roadmap based on your learning needs.
|
||||
@@ -1,181 +0,0 @@
|
||||
---
|
||||
title: 'Data Science vs Machine Learning: How are they different?'
|
||||
description: 'Excited about a career in data science or machine learning? Learn the differences, key skills, tools, and how to choose the role that aligns with your ambitions'
|
||||
authorId: ekene
|
||||
excludedBySlug: '/ai-data-scientist/vs-machine-learning'
|
||||
seo:
|
||||
title: 'Data Science vs Machine Learning: How are they different?'
|
||||
description: 'Excited about a career in data science or machine learning? Learn the differences, key skills, tools, and how to choose the role that aligns with your ambitions.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-vs-machine-learning-gaa7s.jpg'
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2025-02-06
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
If you're excited by the idea of extracting insights from data to guide decisions, a career in [data science](https://roadmap.sh/ai-data-scientist) might be for you. On the other hand, if you're drawn to creating the algorithms behind AI systems and building intelligent applications, machine learning could be your ideal path.
|
||||
|
||||
Both fields are at the forefront of innovation, driving transformative technologies like ChatGPT, DALL-E, and Gemini. These advancements, used across industries like healthcare, finance, and tech, owe their success to the growing collaboration between data science and machine learning. As AI becomes more accessible with tools from companies like OpenAI and AWS, the demand for experts in these fields is only increasing.
|
||||
|
||||
So, how do you choose between these high-demand, rewarding careers? As an ML Engineer with experience on projects that span across data science and machine learning, I have gained a deep understanding of the overlaps and differences between these fields. In this guide, I will explain the responsibilities of each role, highlight their key differences, and outline the essential skills for success. By the end, you'll be better equipped to pick the path that matches your interests, strengths, and career goals.
|
||||
|
||||
The table below summarizes the key differences between data science and machine learning you should consider to help you evaluate which one best fits your career goals:
|
||||
|
||||
| **Aspect** | **Data science** | **Machine learning** |
|
||||
| ------------------------------------- | ----------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------- |
|
||||
| **Ideal for you** **i\*\***f\***\*…** | You enjoy exploring and analyzing data to extract insights and inform decisions. | You are passionate about creating algorithms and systems that learn and improve automatically. |
|
||||
| **Educational background** | Strong foundation in statistics, data analysis, and visualization tools. | Strong foundation in mathematics, programming, and AI techniques. |
|
||||
| **Career opportunities** | Data scientist, [Data Analyst](https://roadmap.sh/data-analyst), Business Intelligence Analyst. | Machine learning Engineer, AI Researcher, Deep Learning Specialist. |
|
||||
| **Industries** | Healthcare, finance, marketing, e-commerce, and government sectors. | Technology, autonomous systems, robotics, fintech, and R&D labs. |
|
||||
| **Skills you'll need** | Data cleaning, exploratory analysis, storytelling, and domain expertise. | Proficiency in machine learning libraries, algorithm design, and optimization. |
|
||||
| **Growth potential** | Strong demand across industries as companies seek to become more data-driven. | High demand in tech-driven fields as AI adoption accelerates. |
|
||||
| **Creativity vs. technical** | Balances creativity in visualizations with technical skills in data processing. | Heavily focused on technical and mathematical skills for problem-solving and predictive analytics. |
|
||||
| **Long-term vision** | Perfect if you want to lead data-driven strategy or explore business analytics. | Ideal if you aim to innovate in AI, robotics, or advanced tech solutions. |
|
||||
|
||||
Before looking at these features in detail, let's take a closer look at these two fields.
|
||||
|
||||
## What is data science?
|
||||
|
||||
Data science is a field that combines techniques from statistics, domain knowledge, computer science, and data analysis to gain insights from structured and unstructured data. As a data scientist, you'll use tools, machine learning models, and algorithms to understand data and drive decision-making. You'll use these insights to help businesses increase profits, create innovative products and services, improve systems, and solve problems across various industries.
|
||||
|
||||
**Key Components of Data Science**
|
||||
The key components of data science involve the following processes:
|
||||
|
||||

|
||||
|
||||
1. **Data collection**: The first step is to gather raw data from various sources such as APIs, sensors, databases, and web scraping.
|
||||
2. **Data cleaning and preparation**: After collecting the raw data, it must be cleaned by removing inaccuracies, handling missing values, and formatting it for analysis.
|
||||
3. **Exploratory Data Analysis (EDA)**: Use statistical methods and visualization techniques to explore the data, identify trends, patterns, and anomalies, and gain a better understanding of the dataset.
|
||||
4. **Data modeling and machine learning**: Apply machine learning algorithms to build models that can identify patterns, predict outcomes, and automate processes.
|
||||
5. **Data visualization**: Use tools like charts, graphs, and dashboards to present insights and communicate findings clearly to stakeholders.
|
||||
6. **Deployment and monitoring**: Implement data models in real-world applications and continuously monitor their performance to ensure they remain accurate and effective.
|
||||
|
||||
### Essential Skills and Tools You Need for a Successful Data Science Career
|
||||
|
||||
To build a successful career in data science, knowledge of a programming language like [Python](https://roadmap.sh/python) is essential. Beyond that, as a data scientist, you'll need to develop expertise in the following skills and tools:
|
||||
|
||||
- **Programming languages**: You'll need proficiency in [SQL](https://roadmap.sh/sql), R, SAS, and others to collect, manipulate, and manage both structured and unstructured data.
|
||||
- **Mathematics, statistics, and probability**: A strong grasp of these concepts will enable you to build accurate models and make data-driven decisions with confidence.
|
||||
- **Data wrangling and visualization**: You'll be responsible for cleaning, transforming, and visualizing data using tools like Matplotlib, Seaborn, Power BI, and Tableau to present insights effectively.
|
||||
- **Machine learning and predictive modeling**: Knowledge of machine learning algorithms and techniques for building models that can make predictions and automate decision-making processes.
|
||||
- **Data analysis tools**: Familiarity with tools like Jupyter Notebooks, Pandas, NumPy, Apache Spark, and Scikit-learn will help you analyze and process data with ease.
|
||||
- **Cloud platforms**: Experience with cloud platforms such as [AWS](https://roadmap.sh/aws), Azure, and Google Cloud will enable you to leverage cloud resources for scalable computing and efficient model deployment.
|
||||
|
||||
## What is machine learning?
|
||||
|
||||
Machine learning is a branch of Artificial Intelligence (AI) that enables computers to learn from data and make predictions without being explicitly programmed. Rather than manually coding rules for every scenario, machine learning models learn from available data to perform tasks such as fraud detection, recommendation systems, natural language processing, and image recognition. It can be broadly categorized into the following types:
|
||||
|
||||

|
||||
|
||||
- **Supervised learning**: In supervised learning, you train a model labeled data to predict outcomes and identify patterns. For example, you can use a dataset with details like location, square footage, and other factors to teach the model how to predict house prices.
|
||||
- **Unsupervised learning**: In unsupervised learning, the model is trained on unlabeled data and discovers patterns or groupings on its own. For example, you can use it to segment customers based on their purchasing habits without specifying predefined categories.
|
||||
- **Reinforcement learning**: In reinforcement learning, you train a model through a trial-and-error process to achieve the best outcomes. For instance, self-driving cars use reinforcement learning by continuously learning to recognize obstacles, road signs, and blockages through repeated experiences.
|
||||
|
||||
### Key Components of Machine Learning
|
||||
|
||||
The key components of machine learning involve the following processes:
|
||||
|
||||
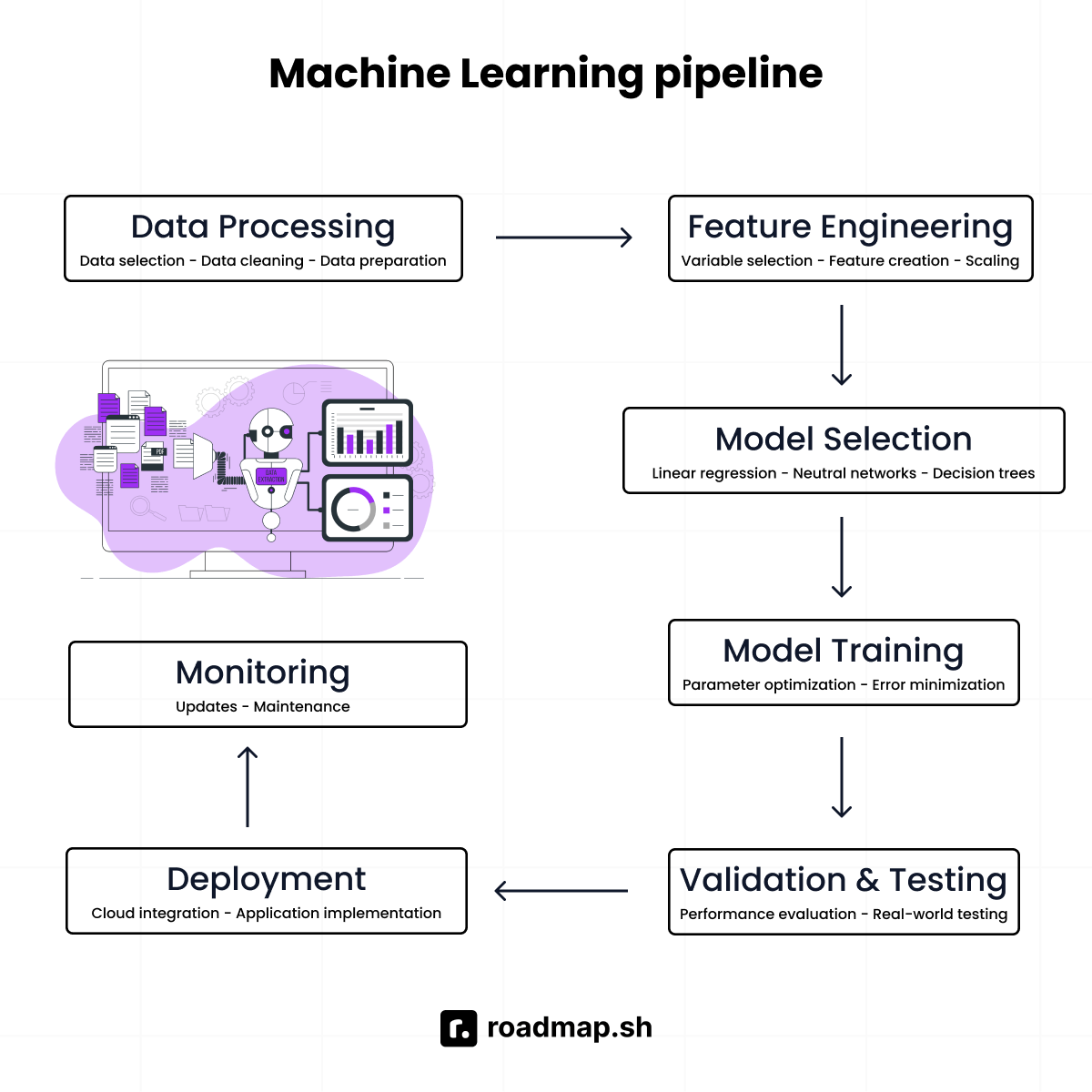
|
||||
|
||||
1. **Data processing**: The foundation of any machine learning system is data. For the model to work effectively, it requires selecting and preparing the right data for training.
|
||||
2. **Feature engineering**: This step involves selecting the right variables (features) that the model can use to make accurate predictions. For example, a housing price prediction model would need features like the number of bedrooms, square footage, and location to make reliable predictions.
|
||||
3. **Model selection**: Choosing the appropriate model for a specific task is crucial. For instance, a **Linear Regression** model is suitable for predicting continuous values, while **Neural Networks** are better suited for tasks like image recognition.
|
||||
4. **Model training**: In this process, the selected model is fed with training data to help it learn patterns. The model's internal parameters are adjusted to minimize prediction errors.
|
||||
5. **Validation and testing**: After training, the model's performance is evaluated using a separate validation dataset. A final test dataset is used to ensure the model performs well in real-world scenarios.
|
||||
6. **Deployment**: Once the model is ready, it is integrated into real-world applications or deployed on cloud platforms to be accessed by third party users.
|
||||
7. **Model monitoring and maintenance**: After deployment, the model must be regularly monitored and updated to maintain accuracy and adapt to changes over time.
|
||||
|
||||
### Essential Skills and Tools You Need for a Successful Machine Learning Career
|
||||
|
||||
To build a successful career in machine learning, you'll need to develop the following essential skills and become familiar with key tools:
|
||||
|
||||
- **Strong understanding of mathematics and statistics**: You'll need a solid understanding of linear algebra, calculus, probability, and statistics to grasp how machine learning algorithms function.
|
||||
- **Proficiency in programming languages**: Python and R are must-haves for implementing machine learning models and handling data efficiently.
|
||||
- **Data handling and preprocessing skills**: You need a solid understanding of how to clean, preprocess, and transform raw data into a format suitable for training models.
|
||||
- **Knowledge of machine learning algorithms**: Understanding algorithms like Linear Regression, Q-learning, and K-means and knowing when to apply them will help you tackle diverse challenges.
|
||||
- **Model evaluation and tuning**: You need to master techniques to evaluate model performance (e.g., accuracy, precision, recall) and fine-tune hyperparameters to improve results.
|
||||
- **Familiarity with libraries and frameworks**: Hands-on experience with Scikit-learn, TensorFlow, Keras, and other popular libraries and frameworks will help you build and deploy machine learning models efficiently.
|
||||
- **Cloud Platforms for Infrastructure**: Familiarity with cloud platforms like AWS, Google Cloud, and Azure will let you manage the infrastructure needed for large-scale machine learning projects.
|
||||
|
||||
While data science and machine learning share common skills, tools, and workflows, they differ significantly in their approaches, methodologies, and focus areas. The table below summarizes the key differences between machine learning and data science:
|
||||
|
||||
| **Category** | **Data science** | **Machine learning** |
|
||||
| ------------------------------ | ---------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------ |
|
||||
| **Mathematics and statistics** | Strong knowledge of statistics, probability, and linear algebra. | Deep understanding of calculus, linear algebra, and optimization techniques. |
|
||||
| **Programming languages** | Python, R, and SQL for data manipulation, statistical analysis, and visualization. | Python, [C++](https://roadmap.sh/cpp), and [Java](https://roadmap.sh/java) for implementing machine learning algorithms. |
|
||||
| **Data handling** | Data wrangling, data cleaning, and data visualization. | Data preprocessing, feature engineering, and handling large datasets. |
|
||||
| **Machine learning basics** | Basic understanding of supervised, unsupervised learning, and regression. | Advanced knowledge of machine learning algorithms, including deep learning. |
|
||||
| **Business acumen** | Ability to translate business problems into data solutions. | Focus on technical problem-solving without a primary business context. |
|
||||
| **Tools and frameworks** | Tableau, Excel, Hadoop, Pandas, Matplotlib, and Scikit-learn. | TensorFlow, PyTorch, Scikit-learn, Keras, and XGBoost. |
|
||||
| **Data visualization** | Building dashboards, reports, and storytelling through data. | Creating visualizations primarily for model performance evaluation. |
|
||||
| **Communication skills** | Strong emphasis on presenting insights to non-technical stakeholders. | Less focus on communication; more technical documentation. |
|
||||
| **Problem-solving approach** | Emphasis on interpreting data to guide decisions. | Emphasis on building models to automate decision-making. |
|
||||
| **Domain knowledge** | Domain expertise in industries like healthcare, finance, marketing, etc. | Less reliance on specific domain knowledge; more generalizable algorithms. |
|
||||
| **Software engineering** | Less focus on software engineering practices. | Strong focus on scalable system design and code optimization. |
|
||||
| **Algorithm understanding** | Basic knowledge of algorithms for data analysis. | Deep understanding of algorithms, including neural networks and gradient descent. |
|
||||
|
||||
Now that we've covered data science and machine learning regarding processes, tools, similarities, and differences, let's explore the key points you should consider to make the right career decision.
|
||||
|
||||
## Data science vs. machine learning: Which career path fits your background?
|
||||
|
||||
If you have a background in statistics, data analysis, and business intelligence, data science could be the perfect match for you. Data science is all about turning raw data into valuable insights that businesses can act on. Your familiarity with working with data makes it easier to spot patterns and trends, which is a key part of what data scientists do. It's a role that requires both creative problem-solving and analytical thinking.
|
||||
|
||||
Machine learning, on the other hand, is better suited for you if you have a strong foundation in mathematics, programming, and computer science. A machine learning expert builds algorithms that can learn from data without explicitly programming them. It requires a solid grasp of concepts like linear algebra, calculus, probability, and algorithm design. If these are skills you already have, this path is a natural fit for you.
|
||||
|
||||
## Data science vs. machine learning: Which path pays off in the long run?
|
||||
|
||||
Both machine learning and data science offer exciting and rewarding career paths, especially with the growing demand for AI across industries.
|
||||
|
||||
In data science, you typically start your career with entry-level positions like Data Analyst or Business Intelligence Analyst and can evolve into leadership roles like Chief Data Officer. This career path is appealing because it allows you to collaborate with both technical teams and business stakeholders, solving real-world problems with data-driven insights.
|
||||
|
||||
A typical career progression in data science involves:
|
||||
|
||||
- Data Analyst
|
||||
- Data Scientist
|
||||
- Senior Data Scientist
|
||||
- Analytics Manager
|
||||
- Chief Data Officer
|
||||
|
||||

|
||||
|
||||
Machine learning careers tend to offer slightly higher salaries due to the specialized skills in programming and algorithm design. A machine learning professional typically starts as a machine learning engineer and can progress to advanced roles like Head of AI/ML, focusing on developing intelligent systems and cutting-edge AI solutions.
|
||||
|
||||
A typical career progression in machine learning involves:
|
||||
|
||||
- Machine Learning Engineer
|
||||
- AI Specialist
|
||||
- Deep Learning Engineer
|
||||
- AI Research Scientist
|
||||
- Head of AI/ML
|
||||
|
||||

|
||||
|
||||
Both paths provide excellent growth opportunities, but your choice should align with your background and long-term career goals.
|
||||
|
||||
## Data science vs. machine learning: Which opportunities are available for you?
|
||||
|
||||
In terms of opportunities, data scientist are in higher demand across various industries that need data-driven insight to make decisions and improve their processes. These include companies within healthcare, finance, marketing, retail, and e-commerce. So, if your goal is to work in diverse industries that rely on data insights, then data science is an ideal choice.
|
||||
|
||||
Machine learning, on the other hand, is more likely to work in technology-focused sectors where prediction, automation, and intelligence systems are at the core of their operation. These include industries like robotics, research and development labs, and autonomous vehicles. As a result, opportunities in machine learning may be harder to come by compared to data science, as machine learning professionals often work in more specialized and focused environments. However, if you're drawn to tech-driven fields involving autonomous systems or AI research, machine learning could be an ideal path for you.
|
||||
|
||||
## Machine learning vs. data science: Which balances creativity and tech better?
|
||||
|
||||
Data science strikes a balance between technical expertise and creativity. It's all about taking complex data and transforming it into meaningful insights that non-technical stakeholders can easily understand. If you enjoy solving problems creatively and telling compelling stories with data, data science would be a great fit for you.
|
||||
|
||||
Machine learning, on the other hand, is more technical and involves developing algorithms. It involves designing, training, and optimizing models that enable machines to learn and make predictions. If you love tackling technical challenges like developing algorithms and building AI models from the ground up, then a career in machine learning would be ideal for you.
|
||||
|
||||
As a rule of thumb, use the decision tree table to choose between data science and machine learning:
|
||||
|
||||

|
||||
|
||||
Choosing between data science and machine learning ultimately depends on your interests and career goals. Both fields offer rewarding opportunities and career growth. The key is to understand what excites you most: extracting meaning from data or building intelligent systems.
|
||||
|
||||
If you're considering starting a career as a data scientist, explore our comprehensive [data science roadmap](https://roadmap.sh/ai-data-scientist) for actionable steps and valuable resources to get started.
|
||||
@@ -1,179 +0,0 @@
|
||||
---
|
||||
title: "Data Science vs Software Engineering: Which to Choose?"
|
||||
description: "Both software engineering and data science offer exciting opportunities, but they require different skill sets. This breakdown helps you find your ideal fit."
|
||||
authorId: william
|
||||
excludedBySlug: '/ai-data-scientist/vs-software-engineering'
|
||||
seo:
|
||||
title: "Data Science vs Software Engineering: Which to Choose?"
|
||||
description: "Both software engineering and data science offer exciting opportunities, but they require different skill sets. This breakdown helps you find your ideal fit."
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-vs-software-engineering-t7okw.jpg'
|
||||
isNew: true
|
||||
type: 'textual'
|
||||
date: 2025-04-14
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Software engineering and [data science](https://roadmap.sh/ai-data-scientist) aren't completely separate; they're more like two overlapping fields. They share similarities, but each has its own focus. Software engineering centers on creating functional products and systems, while data science focuses on extracting insights from data and building predictive models.
|
||||
|
||||
You might want to pick software over data science if you're good at or interested in building applications, solving engineering problems, and working on system architecture. Otherwise, you might want to go for data science if you're good at or interested in analyzing data, finding patterns, and developing models to make data-driven decisions.
|
||||
|
||||
So, how do you choose between these two exciting and in-demand careers? When I started my career, I constantly switched between writing software that powered applications and analyzing data to drive decisions. Both fields fascinated me, but they required different skill sets and ways of thinking. If you're torn between data science and software engineering, this guide will help you understand their key differences and choose the path that aligns with your strengths and interests.
|
||||
|
||||
## Data science vs software engineering
|
||||
|
||||
The table below highlights the major differences between software engineering and data science to help you evaluate which one might be the right fit for you:
|
||||
|
||||
| **Aspect** | **Software Engineering** | **Data Science** |
|
||||
| -------------------------- | ------------------------------------------------------------------------------------ | --------------------------------------------------------------------------------------- |
|
||||
| **Focus** | Software engineers focus on building, maintaining, and scaling software applications | Data scientists focus on analyzing data to extract insights and build predictive models |
|
||||
| **Key skills** | Programming, system design, DevOps, cloud computing | Statistics, machine learning, data visualization |
|
||||
| **Languages** | Python, Java, Go, JavaScript, C# | Python, R, SQL, Scala |
|
||||
| **Tools and frameworks** | Git, Docker, Kubernetes, React, Spring Boot | TensorFlow, PyTorch, Pandas, Jupyter, Spark |
|
||||
| **Primary goal** | Deliver reliable and scalable software systems | Extract meaningful insights from data |
|
||||
| **Work environment** | Agile development, collaboration with product teams | Research-oriented, collaboration with analysts and business teams |
|
||||
| **Mathematical intensity** | Moderate (algorithms, data structures) | High (statistics, probability, linear algebra) |
|
||||
| **Problem-solving type** | Debugging, optimizing performance, scalability | Pattern recognition, prediction, optimization |
|
||||
| **Typical output** | Websites, mobile apps, cloud platforms, APIs | Reports, machine learning models, dashboards |
|
||||
| **Career paths** | Backend Developer, Frontend Developer, DevOps Engineer | Data Analyst, Data Scientist, ML Engineer |
|
||||
| **Best for people who** | Enjoy building and improving systems that users interact with | Love working with data, uncovering patterns, and making predictions |
|
||||
|
||||
Before looking at these aspects in detail, let's take a closer look at these two fields.
|
||||
|
||||
## What is software engineering?
|
||||
|
||||
Software engineering is the process of designing, building, testing, and maintaining computer programs. It involves using structured methodologies, programming knowledge, and best practices to develop software that is reliable, efficient, and easy to maintain.
|
||||
|
||||
For example, when you work on an app like WhatsApp as a software engineer, you work on different parts, like handling how messages are sent, how the app looks and feels, and much more.
|
||||
|
||||
## Key components of software engineering
|
||||
|
||||
The key aspects of software engineering involve the following:
|
||||
|
||||

|
||||
|
||||
1. **Software development lifecycle (SDLC)**: Every application goes through several stages before it's ready for use:
|
||||
1. **Planning and requirements**: Define what the software should do and identify the necessary tools.
|
||||
2. **Design**: Outline how the software will function and how different parts will interact.
|
||||
3. **Coding**: Write the actual program using languages like [Java](https://roadmap.sh/java), [Python](https://roadmap.sh/python), or [JavaScript](https://roadmap.sh/javascript).
|
||||
4. **Testing**: Find and fix bugs before launching.
|
||||
5. **Deployment**: Release the software for users.
|
||||
6. **Maintenance**: Update and improve the software by adding features or fixing issues.
|
||||
2. **Software design and architecture**: This involves structuring the software and deciding how different components work together. It's like designing a building. You need a solid foundation and a layout that's organized and easy to navigate.
|
||||
3. **Programming and Development**: Writing code is a major part of software engineering. You'll use languages like Python, JavaScript, or Java to develop web, mobile, and backend applications.
|
||||
4. **Testing and Quality Assurance**: Before releasing software, testing helps identify and fix bugs so users don't run into problems.
|
||||
5. **Deployment and DevOps**: Once the software is ready, it needs to be deployed properly. This includes setting up **CI/CD pipelines** for automated testing and deployment, as well as monitoring systems to track performance and apply updates when needed.
|
||||
|
||||
## Essential skills you need for a successful software engineering career
|
||||
|
||||
To build a successful career in software engineering, you'll need a mix of technical and soft skills like:
|
||||
|
||||
- **Programming languages**: Coding is the heart of software engineering. A strong grasp of languages like JavaScript, Python, and Java will help you build both frontend and backend systems.
|
||||
- **System design**: This involves architecting software so that they are scalable, maintainable, and efficient. You'll make key decisions about databases, API structures, and how different services communicate within an application.
|
||||
- **Database management**: Data is an essential part of your application. You'll need to know how to structure it, optimize queries, and keep it secure. For example, in an **online banking system**, customer balances must be stored securely while still allowing fast retrieval for transactions.
|
||||
- **Cloud platforms**: Cloud computing enables businesses to run applications without managing physical servers. Familiarity with platforms like [AWS](https://roadmap.sh/aws), Google Cloud, or Azure will help you deploy and scale applications efficiently.
|
||||
- **Communication and teamwork**: You'll often need to explain technical concepts to non-technical stakeholders, write clear documentation, and collaborate with teams across different functions. Strong communication skills will help you work effectively and drive projects forward.
|
||||
|
||||
## What is data science?
|
||||
|
||||
Data science is the process of collecting, analyzing, and interpreting large amounts of data to find useful insights. It combines programming, statistics, and problem-solving to help businesses and organizations make better decisions.
|
||||
|
||||
For example, when Netflix suggests movies based on what you've watched before, it's using data science to predict what you might like.
|
||||
|
||||
## Key components of data science
|
||||
|
||||
The key aspects of data science involve the following:
|
||||
|
||||

|
||||
|
||||
1. **Data collection**: This is the first step in a data science project. As a data scientist, you'll gather information from sources like websites, databases, and sensors for further analysis. For example, in an e-commerce project, you'll collect data on products people buy to understand shopping trends.
|
||||
2. **Data cleansing and preparation**: The data you collect from various sources are raw and won't come in ready for analysis. You need to clean and organize the raw data to remove missing entries, duplicated items, and missing headers.
|
||||
3. **Data analysis and visualization**: This involves the use of charts and graphs to find patterns and trends. For example, you can analyze social media company data to see how many users are active at different times of the day.
|
||||
4. **Machine learning and predictions**: Beyond manually identifying trends and patterns, you'll also use machine learning algorithms to train computers to recognize patterns and make predictions. For instance, a data scientist working in a bank can use machine learning to detect fraud by spotting unusual transactions.
|
||||
|
||||
## Essential skills you need for a successful data science career
|
||||
|
||||
To build a successful career in data science, you'll need a mix of technical and soft skills like:
|
||||
|
||||
- **Programming languages**: A solid understanding of Python or R is essential for data analysis, machine learning, and automation. SQL is also crucial for retrieving and managing data from databases.
|
||||
- **Statistics and mathematics**: You need a strong grasp of probability, distributions, and calculus, as they come in handy when interpreting data and building accurate models.
|
||||
- **Data visualization and machine learning**: You need a solid understanding of how to transform complex numbers into easy-to-understand visuals like bar charts, line graphs, and heat maps. Beyond visualization, you also need a good understanding of how to build models that enable computers to recognize patterns and make predictions without being explicitly programmed.
|
||||
- **Big data tools**: You need a good knowledge of big data technologies like Hadoop and Spark that let businesses process and analyze large datasets quickly. For example, you can use Spark to analyze millions of users data on a social media platform to personalize content recommendations.
|
||||
- **Problem solving and critical thinking**: As a data scientist, you'll need to question data sources, uncover hidden insights, identify biases, and draw accurate conclusions from complex datasets.
|
||||
- **Communication and teamwork**: Even the best insights are useless if they aren't clearly communicated. You'll need to translate technical findings into actionable insights that business teams can understand and act on.
|
||||
|
||||
Now that we've covered software engineering and data science regarding processes, tools, and required skills, let's explore why software engineering might be a better option for you or if data science is better suited.
|
||||
|
||||
## What your day-to-day involves
|
||||
|
||||
If you're excited by how big tech companies like Uber or Netflix design, develop, and maintain mobile apps, backend systems, or large distributed systems, then software engineering might be a great fit for you. As a software engineer, you will focus on building functional and efficient digital products, using and developing the technical skills that interest you.
|
||||
|
||||
If you're more interested in extracting insights from data rather than building software systems, data science might be a better fit. As a data scientist, your core focus will be analyzing large datasets, applying machine learning models, and deriving actionable business insights. Unlike software engineering, this role involves more statistical modeling and data interpretation than designing or developing applications.
|
||||
|
||||
## What skills and background do you currently have?
|
||||
|
||||
Are you familiar with a programming language? Have you taken any courses related to computer science or how the Internet works?
|
||||
|
||||
If your answer to some of these questions is **"YES,"** and you enjoyed learning these skills, software engineering might be a great fit. Your existing knowledge and background will be valuable as you build your career in software development.
|
||||
|
||||
However, data science might be worth considering if you're more comfortable working with numbers, statistics, or data visualization rather than building software systems. A strong foundation in statistics, data analysis, and business intelligence is key in this field, making it a good fit for you as you enjoy working with data rather than writing application logic.
|
||||
|
||||
## Do you enjoy working in a collaborative environment?
|
||||
|
||||
As a software engineer, you will work in teams that include both technical (software developers, product managers, and designers) and non-technical (sales and marketing) stakeholders. A typical workday involves writing code, fixing bugs, reviewing pull requests, and discussing features. If you enjoy working collaboratively and like having teammates with whom to brainstorm ideas, then software engineering could be a great fit for you.
|
||||
|
||||
While data scientists also collaborate with other stakeholders, their teams are usually smaller, especially in startups or smaller companies. In many cases, a single person or a very lean team often handles data-related tasks, meaning the role may involve more independent research, analysis, and reporting rather than large-scale team collaboration. If you prefer deep, focused work with fewer distractions, data science might be the better choice.
|
||||
|
||||
## Data science vs software engineering: Where do you see yourself in the future?
|
||||
|
||||
Both software engineering and data science are rewarding career paths with diverse opportunities for growth and specialization.
|
||||
|
||||
In software engineering, you can work across various industries that continuously adapt and innovate with technology. You also have the flexibility to explore related career paths like:
|
||||
|
||||
- Frontend developer
|
||||
- Backend developer
|
||||
- Fullstack developer
|
||||
- DevOps engineer
|
||||
- Senior software engineer
|
||||
- Cloud engineer
|
||||
- Software architect
|
||||
|
||||
This broad range of roles increases your chances of landing a job, as there are many positions to apply for.
|
||||
|
||||
The average salary of a software engineer in the US is about [$105,596 per annum](https://www.indeed.com/career/software-engineer/salaries), and software engineers tend to earn even more with experience and specialized skills.
|
||||
|
||||

|
||||
|
||||
In data science, the career path is more specialized, with key roles like:
|
||||
|
||||
- Data analyst
|
||||
- Machine learning engineer
|
||||
- Business intelligence analyst
|
||||
- AI researcher
|
||||
|
||||
While the average salary for a data scientist may be slightly higher than that of a software engineer, software engineering offers greater career flexibility and a wider range of job opportunities. If you're unsure which path to take, consider whether you enjoy building systems (software engineering) or analyzing data to extract valuable insights (data science).
|
||||
|
||||
The average salary of a data scientist in the US is about [$123,111 per annum](https://www.indeed.com/career/data-scientist/salaries?from=top_sb).
|
||||
|
||||

|
||||
|
||||
While data science is leading in AI adoption, software engineering is just as important. Data scientists focus on tasks like collecting, cleaning, and preparing data and training machine learning (ML) models that power AI systems.
|
||||
|
||||
But AI isn't just about data science; software engineers play a key role too. They build the infrastructure and pipelines needed to deploy and manage these models, making it possible to run them efficiently on large datasets.
|
||||
|
||||
Plus, AI APIs have made it much easier for software engineers to integrate AI into applications without deep expertise in machine learning. So, if you're worried about missing out on the AI wave, don't be. You can still do amazing work in the space.
|
||||
|
||||
Ultimately, both software engineering and data science are rewarding careers. To determine which one suits you best, consider doing a litmus test:
|
||||
|
||||
- Try building a small application using version control and deploying it to see if software engineering interests you.
|
||||
- Analyze a dataset with Python, create visualizations, and experiment with basic machine learning to see if data science excites you.
|
||||
|
||||
If you're leaning toward software engineering, check out our software development roadmaps for [frontend](https://roadmap.sh/frontend), [backend](https://roadmap.sh/backend), or [full stack](https://roadmap.sh/full-stack) development. If data science resonates with you, explore our [data science roadmap](https://roadmap.sh/ai-data-scientist) to get started.
|
||||
|
||||
@@ -1,197 +0,0 @@
|
||||
---
|
||||
title: "Data Science vs Statistics: How do they compare?"
|
||||
description: "Not sure whether to pursue data science or statistics? This guide breaks down the key differences, career paths, and skills you need to make an informed choice."
|
||||
authorId: ekene
|
||||
excludedBySlug: '/ai-data-scientist/vs-statistics'
|
||||
seo:
|
||||
title: "Data Science vs Statistics: How do they compare?"
|
||||
description: "Not sure whether to pursue data science or statistics? This guide breaks down the key differences, career paths, and skills you need to make an informed choice."
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-science-vs-statistics-e3rtw.jpg'
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2025-03-24
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Data science and statistics are promising career paths that offer great opportunities to work with data to solve problems and guide decision-making in various industries. But how do you determine which one is a good career for you? If you're new to these fields, learning about their core concepts and career opportunities can help you get started. If you are a student or professional exploring data-driven careers, this guide will help clear up confusion and determine the path that aligns with your goals.
|
||||
|
||||
When choosing between the two, think about the types of problems you like to solve. If you're interested in understanding why and how an issue occurred, uncovering insights from raw data, and building models to predict future outcomes, data science may be the right fit for you. On the other hand, if you prefer analyzing and interpreting quantitative data, identifying patterns, and making statistical predictions, statistics could be the better path.
|
||||
|
||||
At first, data science and statistics might seem interchangeable. But as we dig deeper, you'll see how they differ. Statistics provides the foundation by defining methods, probabilities, and models. Data science builds on that foundation to extract insights from complex data and solve real-world problems.
|
||||
|
||||
In this guide, I'll explain where [data science](https://roadmap.sh/ai-data-scientist) and statistics connect and differ. You'll learn more about the skills and tools necessary for each role and gain more clarity into the career prospects and opportunities they offer. By the time you finish, you'll have a clear vision of your ideal role and the confidence to start shaping your future.
|
||||
|
||||
The following table provides a comparison of data science and statistics.
|
||||
|
||||
| | Data Science | Statistics |
|
||||
| --------------- | --------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------- |
|
||||
| Key role | Uses statistics, computer science, and domain expertise to interpret complex datasets. | Uses statistical methods to analyze and make predictions for small, structured datasets. |
|
||||
| Data processing | Handles large and complex datasets (big data). | Works with smaller datasets, emphasizes sampling techniques. |
|
||||
| Tools | Python, R, SQL, Hadoop, and TensorFlow. | Statistical software like SAS, R, SPSS, and mathematical models. |
|
||||
| Skills | Machine learning knowledge, programming skills, data mining, data visualization, business intelligence, and predictive analytics. | Proficient in probability, mathematical theory, statistical modeling, data analysis, and survey design. |
|
||||
| Career paths | Data scientist, machine learning engineer, data analysts. | Statistician, biostatistician, research analyst. |
|
||||
| Salary range | For data science career options, salary ranges from $81,273 to $161,715 per year. | For statistics career trajectories, salary ranges from $75,789 to $101,789 per year. |
|
||||
|
||||
Data science vs. statistics: What sets them apart?
|
||||
|
||||
Data science and statistics are two different areas of analytics, each with its role and methodology. Both use statistical methods, but the key difference lies in their application and purpose.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
Data science is a blend of statistics, computer science, and domain expertise. It focuses on analyzing large, complex datasets to uncover trends, predict outcomes, and drive business decisions. As a data scientist, you'll use machine learning, programming, and big data tools to solve real-world problems.
|
||||
|
||||
Statistics, on the other hand, is rooted in mathematical theory and inference. As a statistician, you'll design experiments, develop models, and test hypotheses to draw conclusions from structured datasets. You'll work in industries like finance, healthcare, government, and research.
|
||||
|
||||
The key difference is application. Statistics is theoretical and inference-driven, while data science applies statistical techniques in a computational, business-focused way.
|
||||
|
||||
To get a clearer picture of both roles, let's look at the day-to-day tasks involved in each field.
|
||||
|
||||
## Job roles and responsibilities
|
||||
|
||||
Both data science and statistics rely on statistical methods and tools, but your day-to-day activities in each field will differ significantly. As a statistician, you focus on collecting, analyzing, and interpreting data to uncover patterns. As a data scientist, you go beyond that by leveraging machine learning, big data technologies, and programming to extract actionable insights.
|
||||
|
||||
Now, let's take a closer look at their specific roles and responsibilities through a shared case study.
|
||||
|
||||
### Key responsibilities of data scientists
|
||||
|
||||
As a data scientist, you'll extract actionable insights from raw data to solve complex business problems. For example, imagine a pharmaceutical company is developing a new drug. As a data scientist, you might be analyzing clinical trial data to predict treatment efficacy for different patient groups. By applying machine learning models, you can find hidden patterns in patient responses, segment populations, and optimize treatment recommendations.
|
||||
|
||||
The following are some of your day-to-day responsibilities as a data scientist:
|
||||
|
||||
* Discovery: Understanding patient demographics, health conditions, and genetic factors to segment target groups.
|
||||
* Data collection: Gathering patient records, clinical trial results, and external medical research data for analysis.
|
||||
* Generate insights: Finding trends in treatment responses using advanced analytics and predictive modeling.
|
||||
* Model large data sets: Using machine learning to forecast drug effectiveness across different conditions.
|
||||
* Design algorithms: Building AI-driven models to personalize medication plans and optimize trial outcomes.
|
||||
|
||||
### Key responsibilities of a statistician
|
||||
|
||||
As a statistician, your focus is on designing experiments, analyzing data and applying statistical methods to evaluate results.
|
||||
|
||||
Using the same pharmaceutical company case, as a statistician, you might be responsible for ensuring the clinical trial design is statistically sound and the results are statistically valid before regulatory approval. You would be conducting hypothesis testing, confidence interval analysis, and regression models to confirm that the drug is effective and safe.
|
||||
|
||||
Your day-to-day responsibilities might include:
|
||||
|
||||
* Designing surveys and experiments: Design a clinical trial or questionnaires for the new drug to verify it is statistically sound
|
||||
* Testing hypotheses: Choosing the right statistical test based on the data type.
|
||||
* Analyzing structured datasets: Summarizing data, analyzing, and modeling relationships between variables to predict outcomes.
|
||||
* Data reporting: Using charts, graphs, and other visual aids to report complex information effectively.
|
||||
* Business recommendations: Provide valuable insight and production strategies based on trial results.
|
||||
|
||||
Let's dig into a few tools and skills you must be proficient in for your selected job role.
|
||||
|
||||
## Essential skills and tools
|
||||
|
||||
Whether you are planning to choose data science or statistics as your career, it is important to know the right tools and essential skills for future challenges.
|
||||
|
||||

|
||||
|
||||
Both data science and statistics require a strong foundation in mathematics and analytical thinking skills. Professionals in these fields often pursue advanced degrees, such as a Master's or Ph.D., to enhance their expertise. Let's examine a few key skills and tools essential for each job profile.
|
||||
|
||||
### Skills and tools of a data scientist
|
||||
|
||||
Handling complex datasets, including both unstructured and structured data, requires a data scientist to possess strong technical and problem-solving skills. You should have the following skills for a data scientist job profile:
|
||||
|
||||
* **Programming Skills:** To perform data science tasks smoothly, you must be proficient in [Python](https://roadmap.sh/python), [SQL](https://roadmap.sh/sql), [Java](https://roadmap.sh/java), and R programming languages. Additionally, you must be good at statistical analysis and mathematics.
|
||||
* **Machine learning knowledge:** You should be able to choose and implement appropriate algorithms, such as linear regression, logistic regression, decision trees, random forests, and neural networks, based on the specific problem and dataset.
|
||||
* **Data mining:** Knowledge of techniques like data cleaning, preprocessing, feature engineering, and pattern recognition are essential to extracting meaningful insights from big data.
|
||||
* **Data visualization:** Tools like Tableau and Power BI can help create compelling charts and graphs for your big data. You must know how to use these tools effectively to communicate data insights.
|
||||
* **Business intelligence:** Understanding business contexts and translating data insights into actionable business decisions is key. You must have strong communication skills and domain knowledge.
|
||||
|
||||
Hadoop, Docker, TensorFlow, GitHub/Git, SQL, and Tableau are important for a data science job profile. Interviewers often prioritize candidates with educational qualifications in computer science, programming, and practical applications of data analysis techniques.
|
||||
|
||||
### Skills and tools of a statistician
|
||||
|
||||
A statistician's main responsibility is to analyze data to predict future events or trends. To achieve this goal, you must excel in the following skills and tools:
|
||||
|
||||
* Mathematical theory: A strong understanding of mathematical concepts like linear algebra, calculus, etc., is essential to measure quantitative data.
|
||||
* Probability: Proficiency in probability theory is essential for understanding and modeling uncertainty in data.
|
||||
* Statistical modeling: Experience with various statistical models, such as time series analysis and linear regression, is also valuable.
|
||||
* Survey design: Knowledge of designing questionnaires or sampling techniques is necessary to collect information from a group of people.
|
||||
|
||||
R, SAS, SPSS, and Excel are a few popular tools you should master to perform statistical analysis and generate graphics. Also, candidates with qualifications in advanced statistical modeling, mathematical and statistical theory, and research methodologies have a better chance of getting selected.
|
||||
|
||||
Let's move forward to different career options available under data science and statistics. Learning about their salary ranges will provide valuable insight into earning potential, helping you make an informed career decision. By comparing salaries, you can assess financial stability, ensuring that your chosen path aligns with your long-term financial goals.
|
||||
|
||||
## Career prospects for both fields
|
||||
|
||||
Data science is experiencing explosive growth across numerous industries, whereas the demand for statisticians remains strong and consistent. Let's explore the various job roles available in both fields and their salary ranges.
|
||||
|
||||
### Data science career paths and salary insights
|
||||
You can choose from the following careers if you are planning to proceed with data science:
|
||||
|
||||
* Data scientist
|
||||
* Machine learning engineer
|
||||
* Data analyst
|
||||
|
||||
**Data scientist:** A career in data science offers opportunities in various industries, including finance, healthcare, and technology. As a data scientist, you'll tackle unique problems, using statistical modeling and machine learning to drive business decisions and outcomes. You need to have a deep understanding of data manipulation and how data relates to the real world.
|
||||
|
||||
Many data scientists use machine learning algorithms to build predictive models, identify trends, and make data-driven decisions. Strong communication skills and expertise in statistical modeling are essential for success in this field. You may start as a junior data scientist and improve your knowledge to lead as Head of Data Science over time.
|
||||
|
||||
In the United States, the [average salary](https://www.datacamp.com/blog/data-science-salaries) of a data scientist is $123,069 per year.
|
||||
|
||||
**Machine learning engineer:** A career as a machine learning engineer involves designing, building, and optimizing machine learning models used in various applications, from recommendation systems to fraud detection. Professionals in this field work on improving machine learning frameworks, monitoring model performance, and solving complex computational problems. To succeed, you need expertise in advanced machine learning, cloud computing, and the software development lifecycle (SDLC).
|
||||
|
||||
Machine learning engineers are in high demand across finance, healthcare, e-commerce, and technology industries. You can start by working on implementing basic machine learning models; as you improve your skills and gain more knowledge, you can work towards a role overseeing ML infrastructure, defining best practices, and leading technical teams.
|
||||
|
||||
In the United States, the [average salary](https://www.indeed.com/career/machine-learning-engineer/salaries) for a machine learning engineer is $161,715 per year.
|
||||
|
||||
**Data analyst:** [Data analysts](https://roadmap.sh/ai-data-scientist/vs-data-analytics) play a crucial role in helping businesses make informed decisions by collecting, filtering, and analyzing data to answer specific business questions. You can use data visualization tools to present insights clearly to stakeholders.
|
||||
|
||||
A career as a data analyst offers opportunities across various industries, including marketing, finance, and healthcare, making it a versatile and in-demand profession. The data analyst job profile includes various positions and levels, from basic reporting and performing deeper data analysis to making data-driven decisions for an organization.
|
||||
|
||||
According to [Indeed](https://www.indeed.com/career/data-analyst/salaries), the average salary for a data analyst job profile in the United States is $81,273 annually.
|
||||
|
||||
### Statistics career paths and salary insights
|
||||
|
||||
If you're interested in statistics, here are a few job positions you can choose from:
|
||||
|
||||
* Statistician
|
||||
* Biostatistician
|
||||
* Research Analyst
|
||||
|
||||
**Statistician:** As a statistician, you will design and conduct statistical analysis, interpret data, and communicate findings to researchers and other stakeholders. Many statisticians work on research projects, clinical trials, and large-scale surveys, helping organizations make data-driven decisions.
|
||||
|
||||
There are different levels in the statistician job profile, from applying statistical techniques for data interpretation to leading statistical research and influencing policy decisions. Strong analytical skills and a solid understanding of statistical methods are essential for this career path.
|
||||
|
||||
According to [Indeed](https://www.indeed.com/career/statistician/salaries), the average salary of a statistician in the United States is $89,126 per year.
|
||||
|
||||
**Biostatistician:** Biostatisticians apply statistical methods to biological and medical research, making significant contributions to the healthcare and pharmaceutical industries. If you are planning to pursue a career in this field, you will design and analyze clinical trials, ensuring the accuracy and reliability of biomedical research. This career path offers opportunities in hospitals, government agencies, research institutions, and pharmaceutical companies.
|
||||
|
||||
The [average salary](https://www.indeed.com/career/biostatistician/salaries) for a biostatistician is $101,789 per year in the United States.
|
||||
|
||||
**Research analyst:** In this role, you will use statistical and analytical methods to collect and interpret information to support business decisions. You will also identify trends, generate insights, and present detailed reports summarizing your research for stakeholders.
|
||||
|
||||
According to [Indeed](https://www.indeed.com/career/research-analyst/salaries), the average salary for a research analyst in the United States is $75,789 per year.
|
||||
|
||||
## Are data science and statistics interconnected?
|
||||
|
||||
A statistician uses statistical tools and mathematical models to analyze customer data and distinct customer segments with similar characteristics. This analysis will help stakeholders understand the factors responsible for customer churn rates. Data scientists, meanwhile, will collect big data and use machine learning models to perform predictive analysis.
|
||||
|
||||
Statistics answer questions like "Why did customer churn get high in the first quarter?" or "What is the reason behind the sudden downfall"? Data science, on the other hand, answers "How can this issue be fixed?".
|
||||
|
||||
So yes, data science and statistics are deeply interconnected.
|
||||
|
||||
Statistics provides the foundation for analyzing data, such as finding patterns and trends. Data science professionals, on the other hand, create sophisticated models and present insights through data visualization. Data science is an extended version of statistics that uses statistical methods, scientific methods, machine learning, and artificial intelligence to manage unstructured or semi-structured data.
|
||||
|
||||
Data science further leverages predictive modeling and other advanced techniques to understand past events, predict future trends, identify potential risks, solve real-world problems, and develop improvement strategies.
|
||||
|
||||
Additionally, statistics doesn't require computational skills but an understanding of basic mathematical models to analyze and predict results.
|
||||
|
||||
## Next Step?
|
||||
|
||||
Choosing between data science and statistics can be a tough call. Hopefully, this guide has helped clarify which career path is the best for you. Once you've made a decision, the next step is to get started.
|
||||
|
||||
To help you with your journey, I encourage you to explore the [comprehensive resources](https://roadmap.sh/ai-data-scientist) that delve deeper into the specifics of each path. Whether you are interested in programming and solving complex datasets or theoretical analysis and working with structured data, we have great resources for each career option.
|
||||
|
||||
You can apply for internships or join online courses to gain more experience or sharpen your knowledge. If you still have queries or doubts about these fields, join the [Discord community](https://roadmap.sh/discord) to stay up-to-date!
|
||||
@@ -1,22 +0,0 @@
|
||||
---
|
||||
title: 'Asymptotic Notation'
|
||||
description: 'Learn the basics of measuring the time and space complexity of algorithms'
|
||||
authorId: 'kamran'
|
||||
seo:
|
||||
title: 'Asymptotic Notation - roadmap.sh'
|
||||
description: 'Learn the basics of measuring the time and space complexity of algorithms'
|
||||
isNew: false
|
||||
type: 'visual'
|
||||
date: 2021-04-03
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'visual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||
Asymptotic notation is the standard way of measuring the time and space that an algorithm will consume as the input grows. In one of my last guides, I covered "Big-O notation" and a lot of you asked for a similar one for Asymptotic notation. You can find the [previous guide here](/guides/big-o-notation).
|
||||
|
||||
[](/guides/asymptotic-notation.png)
|
||||
@@ -1,20 +0,0 @@
|
||||
---
|
||||
title: 'Async and Defer Script Loading'
|
||||
description: 'Learn how to avoid render blocking JavaScript using async and defer scripts.'
|
||||
authorId: 'kamran'
|
||||
seo:
|
||||
title: 'Async and Defer Script Loading - roadmap.sh'
|
||||
description: 'Learn how to avoid render blocking JavaScript using async and defer scripts.'
|
||||
isNew: false
|
||||
type: 'visual'
|
||||
date: 2021-09-10
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'visual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||
[](/guides/avoid-render-blocking-javascript-with-async-defer.png)
|
||||
@@ -1,275 +0,0 @@
|
||||
---
|
||||
title: '8 In-Demand Backend Developer Skills to Master'
|
||||
description: 'Learn what the essential backend skills you should master to advance in your career.'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/backend/developer-skills'
|
||||
seo:
|
||||
title: '8 In-Demand Backend Developer Skills to Master'
|
||||
description: 'Learn what the essential backend developer skills are that you should learn and master to advance in your career.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/backend-developer-skills-ece68.jpg'
|
||||
relatedTitle: "Other Guides"
|
||||
relatedGuidesId: backend
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2024-02-27
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Whether your goal is to become a backend developer or to stay relevant as one, the goal itself requires adopting an eternal student mindset. The ever-evolving web development space demands continuous learning, regardless of the programming language you use. New frameworks, libraries, and methodologies emerge regularly, offering different solutions to old problems. To remain relevant as a [backend developer](https://roadmap.sh/backend), you’ll have to stay updated by honing your core skills.
|
||||
|
||||
In this article, we’ll cover the following set of backend developer skills we recommend you aim for:
|
||||
|
||||
- Keeping an eye on core and new backend programming languages
|
||||
- Understanding the basics of software design and architecture
|
||||
- Understanding databases and how to use them
|
||||
- API development
|
||||
- The basics of version control
|
||||
- Testing and debugging
|
||||
- CI/CD and DevOps fundamentals
|
||||
- Soft skills
|
||||
|
||||
So, let's get going!
|
||||
|
||||
## Understanding Backend Development
|
||||
|
||||
Before we move on and start discussing the different backend development skills you should focus on, let’s first understand what a backend developer is. After all, if you’re looking to actually become a backend developer, you’ll need this.
|
||||
|
||||
A backend developer focuses entirely on writing business logic for an application and much of the supporting logic as well.
|
||||
|
||||
That said, there might be applications where the business logic is split into the frontend and the backend. However, while the frontend dev might have to share their time between UI code and business logic, the backend dev will focus most of their time on core business logic. That’s the main difference between the two.
|
||||
|
||||

|
||||
|
||||
In the above image, you can see how there is a lot more behind the curtain than just the UI when it comes to web applications. In this case, a “simple” log-in form needs a backend to contain its core business logic.
|
||||
|
||||
Let’s now look at the most in-demand backend developer skills you should focus on in backend development.
|
||||
|
||||
## Proficiency in Core and Emerging Programming Languages
|
||||
|
||||
One of the most basic skills you should focus on as a backend developer is on identifying key programming languages to learn (or at least keep an eye out for).
|
||||
|
||||
There are some essential backend languages that the industry has adopted as de facto standards. This means most new projects are usually coded using one (or multiple) of these programming languages.
|
||||
|
||||

|
||||
|
||||
The most common names you should look out for are:
|
||||
|
||||
- **JavaScript (or any of its variants, such as TypeScript).** This is a very common option because it’s also the language used by frontend developers, thus making it easier for developers to work on both sides of the same project.
|
||||
- **Python.** While a very common option for other types of projects (such as data processing and [data science](https://roadmap.sh/ai-data-scientist)), it’s still very popular in the web development world. Python has many good qualities and supporting frameworks that make it a very easy-to-pick-up option for coding backend systems.
|
||||
- **Go (A.K.A Golang).** This programming language was developed by Google. It was designed with simplicity, efficiency, and concurrency in mind. That’s made it gain popularity in the backend development space, making it an interesting option for projects that prioritize performance and concurrency.
|
||||
- **Java.** One of the most common alternatives for enterprise solutions, Java, has been constantly evolving since its first release back in 1995. All that time making its way into big enterprises that trust its robustness and ever-growing community of developers. While not the easiest language to learn, it’s definitely up there in the top 10 most popular [backend languages](https://roadmap.sh/backend/languages) (according to [StackOverflow’s 2023 Developer survey](https://survey.stackoverflow.co/2023/#technology-most-popular-technologies)).
|
||||
|
||||
While there are other options, the ones mentioned above, from the backend point of view, are some of the most relevant languages to pay attention to. Here are the top 10 most popular ones amongst professional developers (screenshot taken from SO’s survey of 2023):
|
||||
|
||||

|
||||
|
||||
### Keeping an eye on the rising stars
|
||||
|
||||
If working with at least one of the most common backend languages was important, understanding what are the rising technologies in the backend world is just as crucial.
|
||||
|
||||
You won’t see a new programming language being released every month. However, in the span of a few years, you might see the release of several, and out of those, some might stick long enough to become new standards.
|
||||
|
||||
For example, take a look at the period between 2012 and 2015; in just 3 years, 9 programming languages were released, out of which most of them are being used to this day.
|
||||
|
||||

|
||||
|
||||
- In 2012, we got Julia, Elm, Go, and TypeScript.
|
||||
- In 2013, we got Dart
|
||||
- In 2014, we got Swift, Hack, and Crystal
|
||||
- And in 2015, we got Rust.
|
||||
|
||||
Some of those languages are very relevant to this day, such as TypeScript and Rust, while others, such as Hack and Crystal, might be known to only a few in very niche sectors.
|
||||
|
||||
Of course, it’s impossible to predict which programming language will become a standard. However, the skill that you need to hone is that of keeping an eye on the industry to spot new and emerging trends.
|
||||
|
||||
### The importance of supporting frameworks
|
||||
|
||||
[Frameworks](https://roadmap.sh/backend/frameworks) for a specific programming language do change a lot faster than the language itself, though.
|
||||
|
||||
Frameworks are there to provide you with a simplified gateway into the functionalities that you’d normally need for common tasks. For example, in the context of backend web development, frameworks usually take care of:
|
||||
|
||||
- **Parsing HTTP requests** and turning them into objects you can easily interact with (so you don’t have to learn how the HTTP protocol works).
|
||||
- **Abstracting concepts,** such as a request or a response, into objects and functions that you can reason about at a higher level. This gives you an easier time thinking about how to solve a problem using these tools.
|
||||
- **Accessing data becomes a lot easier when there are abstractions.** Some frameworks provide what is known as an ORM (Object Relational Mapping). Through ORM, you can interact with databases without having to think about writing SQL queries or even database schemas.
|
||||
- And many more.
|
||||
|
||||
Frameworks are an essential aspect of the work you’ll do as a backend developer, which is why you should not neglect them. Of course, learning and mastering every single framework out there is impossible. Instead, learn to keep an eye out in the industry and see what are the most common frameworks, and focus on one (or two) of them.
|
||||
|
||||
## Software Design and Architecture
|
||||
|
||||
Coding is not just about writing code.
|
||||
|
||||
While that statement might be a bit confusing, the truth is there is a lot of architecture involved in software development (both in frontend and backend development). Sometimes, working on these aspects of a system is the job of a specific role called “architect.” However, for backend systems, it’s not uncommon for backend developers to also be involved in architecture conversations and decisions. You’re helping design the underlying backend infrastructure, after all.
|
||||
|
||||
The following diagram shows an example of what a very simple system’s architecture might look like:
|
||||
|
||||

|
||||
|
||||
While the example is oversimplified, it gives you an idea of what the practice of “architecting a system” is.
|
||||
|
||||
Essentially, architecting a system means coming up with concepts that represent different aspects of the solution and then deciding how you want to make them interact with each other.
|
||||
|
||||
Why is architecture so important here? Because it gives you properties such as code encapsulation, separation of concerns, reusability, and even scalability as a byproduct of the architecture itself.
|
||||
|
||||
Let’s take a quick look at some of the most common architectures used for creating backend systems.
|
||||
|
||||
### Most common backend architectures
|
||||
|
||||
There are too many different architectural styles and patterns to cover them all inside a single article, but let's just look at some of the most common ones and how they can help you while working on your backend system.
|
||||
|
||||
- **Monolithic architecture:** In a monolithic architecture, the entire application is built as a single, tightly coupled unit. All components (frontend, backend, database, etc) are part of the same codebase. This is a great first architecture because it feels very natural to develop under, and if your project is not going to grow out of proportion, then you will probably not hit any of the cons.
|
||||
- **Microservice-based architecture:** The application is divided into small, independent services, each responsible for a specific business capability. These services communicate through APIs.
|
||||
- **Service-Oriented Architecture:** Similar to microservices, a service-oriented architecture splits functionality into individual services. The main difference is that these services aren’t as granular as a microservice, so they might incorporate functionalities related to different business entities.
|
||||
- **Event-driven architecture:** With this architecture, each system (or service) responds to events (e.g., user actions and messages from other services) by triggering actions or processes. All services communicate with each other indirectly through an event bus (also known as a “message bus”), so it removes the possibility of having two or more services coupled with each other (meaning that they can’t be treated individually).
|
||||
- **Serverless Architecture:** Also known as Function as a Service (FaaS), serverless architecture allows you to focus on writing code without worrying about the server where they’ll run. Functions are executed in response to events without the need for provisioning or managing servers (this is done FOR you automatically).
|
||||
- **Microkernel architecture:** This architecture lets you build the core, essential functionality into a small microkernel and have the rest of the features built as plugins that can be added, removed or exchanged easily.
|
||||
|
||||
And if you want to know more about the patterns and principles mentioned here, please check out the [Software Design and Architecture roadmap](https://roadmap.sh/software-design-architecture).
|
||||
|
||||
## Mastery of Database Management Systems
|
||||
|
||||
As a backend developer, you will undoubtedly have to deal with database administration in your daily tasks. They are the industry standard for storing persistent data.
|
||||
|
||||
Because of that, it’s important to understand that you should be aware of two main categories of databases: SQL databases and NoSQL databases.
|
||||
|
||||
### SQL databases
|
||||
|
||||
These are the standard structured databases (A.K.A relational databases) where you need to define the schema for your data (essentially the data structures you’re dealing with), and then you’ll use a language called [SQL (Structured Query Language)](https://roadmap.sh/sql) to interact with the data inside it. Most backend developers will interact with SQL databases at some point in their career, as this is the most common type of database.
|
||||
|
||||
### NoSQL databases
|
||||
|
||||
As the name implies, these are not your standard SQL databases; in fact, within this category, there are columnar databases, document-based ones (such as [MongoDB](https://roadmap.sh/mongodb)), key-value-based ones (like [Redis](https://roadmap.sh/redis)), and more. They don’t use predefined data structures, giving you more flexibility and control over what you can store and how you store it. Backend developers will deal with only a handful of these, as there are many different sub-types, and more are created every year.
|
||||
|
||||
Some examples of these databases are:
|
||||
|
||||
- MongoDB, a document-based database (see here a mongoDB roadmap if you’re interested).
|
||||
- Redis, an in-memory key-value pair database.
|
||||
- Neo4J, a graph database.
|
||||
- ElasticSearch, a document-based search engine.
|
||||
|
||||
In the end, the decision between SQL and NoSQL is about trade-offs and figuring out what works best for your particular use case.
|
||||
|
||||
## API Development Capabilities
|
||||
|
||||
Application Programming Interfaces (APIs) are everywhere. They power the backend of almost all major systems out there (according to a [study conducted by O’Reilly in 2020](https://www.oreilly.com/pub/pr/3307), 77% of companies were using microservices/APIs).
|
||||
|
||||
That is to say, if you’re thinking about becoming a backend developer, you will be coding APIs/microservices. This is why understanding the basics of them is crucial to ensuring your relevance in the field.
|
||||
|
||||

|
||||
|
||||
The above diagram explains how APIs interact with whatever you might be building.
|
||||
|
||||
Now, if you’re inside the “**The System**” box, then you need to understand how to interact with these APIs using the right tools. If you’re inside the “**External System**” box, then you need to understand the type of standards these APIs need to follow and how to implement them.
|
||||
|
||||
Don’t worry though, for both situations, there are always frameworks and libraries you can use to simplify your task and ensure you’re following the proper industry standards.
|
||||
|
||||
### What are the most common API types?
|
||||
|
||||
The most common types of APIs used in the industry currently are REST and GraphQL.
|
||||
|
||||
As a backend developer, it’s not mandatory that you master both of these types, but it’s definitely recommended that you have some practical experience with one of them.
|
||||
|
||||
- **RESTful APIs.** These are APIs that work over HTTP and make extensive use of the HTTP Verbs to give meaning to each request. They’ve been the most popular type of API until recently, so there are still a lot of projects and teams that make use of it.
|
||||
- **GraphQL.** GraphQL APIs operate over HTTP as well, leveraging the HTTP protocol and its verbs. In contrast to the conventional RESTful APIs, GraphQL has emerged as a powerful alternative, offering a flexible and efficient approach to data querying and manipulation. GraphQL allows clients to request only the data they need, providing a more tailored and efficient interaction between clients and servers.
|
||||
|
||||
Is there one better than the other? There is no easy way to answer that question as both are capable of doing everything you’d need. It’s more about your particular requirements and the preferences of your dev team.
|
||||
|
||||
## Version Control Savvy
|
||||
|
||||
One mandatory skill that all backend developers should work on (actually, all developers, in general) is version control, or in other words, understanding and being familiar with version control systems.
|
||||
|
||||
Essentially, you’ll want to know how to use the version control tool that everyone else is using. The industry standard at the moment of writing this is [Git](https://git-scm.com/), while there might be some teams using other (older) tools, as long as you understand the current one, you’ll be in good shape.
|
||||
|
||||
### What is version control?
|
||||
|
||||
Version control references the ability for you and other developers to share code with each other while you’re working on the same files.
|
||||
|
||||
While Git is the industry standard at the moment, GitHub has created such a popular platform around Git, that it almost makes it mandatory to learn about.
|
||||
|
||||
So go ahead and create an account, browse what others are doing, and upload your own personal projects. It’s definitely a great way to learn.
|
||||
|
||||
### What should you learn about Git?
|
||||
|
||||
If you’re picking up Git as your version control system of choice, there are two main areas you should be focusing on.
|
||||
|
||||
- **The basics.** Clearly understanding how Git works and the basic commands to add, push and pull changes. You should aim to learn enough about them to feel comfortable using them on your day-to-day (because you will).
|
||||
- **Branching strategies.** Sadly, using Git alone is not enough. While through Git you can already start versioning your code, when the project is complex enough and your team big enough, the tool alone will not be enough. You’ll have to come up with [branching strategies](https://learngitbranching.js.org/?locale=es_ES) to organize the whole team’s workflow.
|
||||
|
||||
Keep in mind that Git and Git branching are not trivial topics, and they’ll take a while to master. So, while you should give yourself time to learn about them, also make sure you check with others (or use tools such as ChatGPT) to validate your commands before using them. Remember, a wrong Git command or a wrong workflow can cause major problems within a project, especially if there are many developers working on the same codebase.
|
||||
|
||||
## Testing
|
||||
|
||||
Understanding both what testing is and the importance of it within the backend development workflow is crucial for all developers, and one of the mandatory backend developer skills to focus on.
|
||||
|
||||
Testing is the development process of making sure your code works in a way that doesn’t involve you manually testing every feature but rather using tools that allow you to test and reproduce any problems that can be found programmatically.
|
||||
|
||||
This, of course, helps to remove potential human error from the equation when testing big systems and to increase the speed at which these tests can be done (think seconds vs hours of you doing it manually).
|
||||
|
||||
Testing is a far more complex discipline than I can describe here. Just know that there are many different ways to test a system, and all backend developers should be aware of the following:
|
||||
|
||||
- **Unit testing:** This is the most common way of doing code testing. You’ll write tests using a testing framework for every publicly available function/method in your code. This way you’re making sure every piece of code that can be used is tested and performs according to plan. Running these tests is usually quite fast, so you’ll be doing it before every commit (usually).
|
||||
- **Integration testing:** If you’re building a system that consists of multiple independent systems working together (think, for instance, a microservice-based architecture), then testing each individual part is not enough. You also have to make sure systems that should interact with each other do so correctly. This is where integration tests come into play.
|
||||
- **End-to-end testing (E2E):** These tests are similar to integration tests, but they also include the UI of the system. There are tools you can use to automate actions in your UI as if a real user were performing them and then checking the result. For example, clicking on a log-out button and checking if you’re later redirected to the log-in screen. This flow would involve the backend performing some actions that result in the user being logged out.
|
||||
- **Load testing:** While not exactly the same process as with the previous test types, load testing is great for backend systems because it helps you determine if your backend is ready to deal with high amounts of traffic.
|
||||
|
||||
You can think of the list in graphical format as the following diagram:
|
||||
|
||||

|
||||
|
||||
If you’re just getting started with testing, I’d recommend focusing only on unit testing for the time being. Once you have a grasp on it, start moving out following the above diagram and slowly move into the other types as you progress.
|
||||
|
||||
## CI/CD and DevOps Familiarity
|
||||
|
||||
As a backend developer, your code will be constantly deployed, either into cloud environments or perhaps even into normal, on-premise servers. The point is that what you build will run through CI/CD (Continuous Integration and Continuous Deployment) processes.
|
||||
|
||||

|
||||
|
||||
These processes will automatically test it (Continuous Integration) and automatically deploy it (if all tests go well). As a backend developer, you’re not usually expected to know and understand how to configure these processes; however, it’s important that you know about them.
|
||||
|
||||
DevOps is yet another tangential area to that of a backend developer. When teams are small enough, backend devs might be “gently pushed” into tasks such as configuring CI/CD pipelines, setting up servers, and more. These tasks are usually performed by dedicated professionals with the role of DevOps. Their specialty is automation, making the deployment process efficient and ensuring that everything runs smoothly in the real-world server environment. They play a crucial role in maintaining the reliability and performance of applications and websites.
|
||||
|
||||
So, while they’re not strictly the responsibilities of backend developers, they’re close enough to the role’s day-to-day that it would be a good idea to learn about them. If you’re interested in learning more about DevOps, check out [our DevOps roadmap](https://roadmap.sh/devops) containing all the key topics you should learn about if you want to become a DevOps engineer.
|
||||
|
||||
## Soft Skills
|
||||
|
||||
Finally, the last set of backend developer skills you should focus on are, actually, not technical skills, nor are they exclusively useful for backend developers. These are skills that every developer should work on during their career: soft skills.
|
||||
|
||||
### Improving communication
|
||||
|
||||
The ability to communicate with others, both technical and non-technical people, is crucial in any developer's career.
|
||||
|
||||
For backend developers, it’s especially important because communicating their work and the effects of it is definitely harder than other roles, such as frontend developers who can actually showcase what they’re building.
|
||||
|
||||
As a backend developer, you’ll be able to better explain problems or blockers to your colleagues, you’ll be able to perform requirement gathering much more effectively, and you’ll even improve your own problem-solving skills by being better at articulating the problems and potential solutions to yourself.
|
||||
|
||||
### Critical thinking
|
||||
|
||||
Honing your critical thinking as a backend developer will help your ability to analyze complex problems, identify patterns much faster, and come up with innovative solutions to the problems you’re facing.
|
||||
|
||||
Pushing the limits of your critical thinking skills will also foster a more systematic and strategic approach to coding and architecting robust and efficient solutions.
|
||||
|
||||
In other words, it’ll make you a better and more efficient coder. And who doesn’t want that?
|
||||
|
||||
## Conclusion
|
||||
|
||||
To summarize, if you expect to become a backend developer or to grow in the area of backend development:
|
||||
|
||||
- Keep an eye on the industry to understand what’s the status quo and what’s new and hot.
|
||||
- Understand the basics of software design and architecture.
|
||||
- Look into relational databases and NoSQL databases as well; they’re both important.
|
||||
- Learn how to build and use APIs; they’ll be part of almost every project you work on.
|
||||
- Remember, testing might look like it’s not mandatory, but it’s definitely a standard practice when it comes to backend development.
|
||||
- CI/CD and DevOps are practices you’ll be involved with, either directly or indirectly, so learn about them.
|
||||
- Soft skills are just as important as technical skills if you expect to grow in your career.
|
||||
|
||||
That said, do not take this list as the ultimate roadmap but rather as a starting point. If you’re willing to take your backend developer career to the next level, push yourself out of your comfort zone and pursue the skills listed here and the ones listed in this detailed [backend roadmap](https://roadmap.sh/backend).
|
||||
|
||||
Remember, constant learning is the only absolute truth in the software development world (this is true for backend developers, too). If you keep your skillset updated with the latest trends, you’ll remain adaptable and effective as a backend developer.
|
||||
@@ -1,391 +0,0 @@
|
||||
---
|
||||
title: '25 Essential Backend Development Tools for @currentYear@'
|
||||
description: 'Elevate your development process with these 25 essential backend developer tools.'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/backend/developer-tools'
|
||||
seo:
|
||||
title: '25 Essential Backend Development Tools for @currentYear@'
|
||||
description: 'Elevate your coding with backend developer tools that bring efficiency, scalability, and innovation to your projects. Improve your development process today!'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/backend-development-tools-ou6el.jpg'
|
||||
relatedTitle: "Other Guides"
|
||||
relatedGuidesId: backend
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2024-03-19
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
As developers, we’re not just writing code on a text editor without any other external help. Whether we realize it or not, we’re constantly using different development tools to improve the way we work and the speed at which we can deliver our code.
|
||||
|
||||
In this article, we’ll cover 25 backend development tools that are crucial in the web development industry, and as a [backend developer](https://roadmap.sh/backend), you should be aware of them.
|
||||
|
||||
The categories we’ll tackle are:
|
||||
|
||||
- IDEs and editors
|
||||
- Database tools
|
||||
- Collaboration
|
||||
- Hosting Services
|
||||
- API-Related tools
|
||||
- Productivity tools
|
||||
|
||||
So let’s get started!
|
||||
|
||||
## Beyond programming languages: IDEs and Editors
|
||||
|
||||
Other than the actual programming languages, the Integrated Development Environment (A.K.A your IDE) is the single most important tool you’ll have to pick and use throughout your career in software development.
|
||||
|
||||
Some of them are generic (as in, they work for all types of development), and others will have specific backend development tools (which is what we’re focusing on right now).
|
||||
|
||||
Let’s see some examples that are great for a web development project.
|
||||
|
||||
### 1. Jetbrains Products
|
||||
|
||||
The [Jetbrains family](https://www.jetbrains.com/) of IDEs targets multiple programming languages, including JavaScript, .NET, JAVA (and the Java Virtual Machine), Python, PHP, and more (mostly great options for web development).
|
||||
|
||||

|
||||
|
||||
The benefit of using these IDEs, in comparison with others, is that given how they’re language/technology specific, they have tools designed for those programming languages and specifically for this list to help in your backend development tasks, such as:
|
||||
|
||||
- Debuggers.
|
||||
- Improved IntelliSense.
|
||||
- Improved development environment.
|
||||
|
||||
The only minor issue with these IDEs, especially when compared to the rest of the options listed here, is that they’re not all free. While not all of them are priced the same, I recommend you check out your IDE’s pricing page to understand what options you have (there are free plans if you qualify for them).
|
||||
|
||||
### 2. Visual Studio Code
|
||||
|
||||
[VSCode](https://code.visualstudio.com/) is definitely one of the most popular alternatives these days for all types of web developers, but definitely for backend developers. This IDE’s strongest selling point is that it’s incredibly extensible through plugins. And the community using it is so big and varied that there are plugins for literally anything you need.
|
||||
|
||||

|
||||
|
||||
The other major benefit of VSCode over JetBrains products is that it gives developers a fully working IDE for FREE. While some of the extensions don’t provide exactly the same developer experience as a JetBrains IDE, the proper combination of extensions can provide a very close alternative through VSCode.
|
||||
|
||||
### 3. Zed
|
||||
|
||||
[Zed](https://zed.dev/) is a different type of code editor, and because of that, it might just be the right one for you.
|
||||
|
||||

|
||||
|
||||
Zed, like VSCode, is an all-purpose code editor, letting you code in whatever language you want (whether you’re doing web development or not). The main reasons why you’d pick Zed over others are:
|
||||
|
||||
- **Improved performance.** Zed takes advantage of your CPU AND GPU to improve the speed at which the IDE responds to your commands.
|
||||
- **Multi-user support.**
|
||||
- **Team features.** Zed lets you build software while working with others by sharing notes and letting you interact with teammates through the IDE.
|
||||
|
||||
Zed is an [open-source project](https://github.com/zed-industries/zed), but at the time of writing this article, it’s only available for macOS, so Linux and Windows users are still unable to try this excellent option.
|
||||
|
||||
### 4. Sublime Text
|
||||
|
||||
Before VSCode, [Sublime Text](https://www.sublimetext.com/) was probably one of the most popular code editors for web developers who wanted something powerful for free.
|
||||
|
||||
Just like VSCode, Sublime supports extensibility through plugins, and the rich ecosystem of plugins makes it quite a versatile editor. As a note, this code editor also supports GPU rendering of the UI, like Zed does, so if performance is important to you, then you’ll want to keep reading.
|
||||
|
||||

|
||||
|
||||
With a refreshed UI (if you’ve used Sublime Text in the past, you’ll be happily surprised!) and better internal tooling, the latest version of this editor (version 4) is trying to regain the portion of the market that VSCode took from it at the time.
|
||||
|
||||
### 5. VIM - a developer-focused editor
|
||||
|
||||
[VIM](https://www.vim.org/) is a tool that you either hate or love as a developer, but there is no middle ground.
|
||||
|
||||
This is such an iconic text editor that all the previously mentioned IDE have what is called a “vim mode,” which allows you to use them as if you were using VIM (with the visual and input modes).
|
||||
|
||||

|
||||
|
||||
Vim lets you write code without having to move your fingers away from the home row (the row where you “rest” your fingers, the one with the F and G keys). That means you can navigate documents, write code, move through projects, and more, all with minimum hand movement.
|
||||
|
||||
This is the key philosophy behind Vim’s design, and if you embrace it, it should help to make you a very proficient developer. Of course, adapting to this way of working is not trivial, and there is a lot of muscle memory that has to be re-trained. But once you do it, it’s really hard to go back.
|
||||
|
||||
Just like with all the generic IDEs here, you’ll have to [customize it through “scripts”](https://www.vim.org/scripts/script_search_results.php?order_by=creation_date&direction=descending) to make it work exactly as you want for your environment.
|
||||
|
||||
## Database Tools
|
||||
|
||||
While doing backend development, you will definitely be interacting with databases. They’re a ubiquitous backend tool in the realm of web development.
|
||||
|
||||
Let’s take a look at some great database tools you can use as a backend developer to interact with your favorite database management systems (DBMS).
|
||||
|
||||
### 6. DataGrip
|
||||
|
||||
[Datagrip](https://www.jetbrains.com/datagrip/) is a JetBrains product, which makes it a great option if you’re also going with a JetBrains IDE.
|
||||
|
||||
This tool lets you access all SQL databases from within the same user interface, it provides great help while browsing the data stored in the database, and it also has features that help you write better SQL queries.
|
||||
|
||||

|
||||
|
||||
While the pricing of these tools might be a bit steep (especially if you go with the IDE as well), it’s definitely a solid option if you’re looking for feature-rich and stable software development tools.
|
||||
|
||||
### 7. Navicat
|
||||
|
||||
[Navicat](https://navicat.com/en/products) actually has a family of alternatives based on what you need, from the standard set of SQL databases (such as MySQL, Oracle, Postgre, and so on) up to other NoSQL databases such as MongoDB and Redis.
|
||||
|
||||
In general, the Navicat alternatives are quite lightweight and powerful to use. They might not be as feature-rich as Datagrip, but they let you easily browse and query the data you need.
|
||||
|
||||

|
||||
|
||||
The free trial for Navicat only lasts 14 days, and then you’ll have to pay a monthly fee. That said, for non-commercial use, the license is quite low, which makes it accessible to almost all developers.
|
||||
|
||||
As for features, it has all the ones you’d expect from a tool like this:
|
||||
|
||||
- Ability to connect to multiple databases and visually browse their content.
|
||||
- Query editor with some IntelliSense built-in.
|
||||
- Model representation (automatically converts a database into ER Diagrams).
|
||||
- Simple object designer to create entities through a visual IDE.
|
||||
|
||||
The Navicat series of apps are great backend tools to have at your disposal, if you don’t mind their price, that is.
|
||||
|
||||
### 8. TablePlus
|
||||
|
||||
[Tableplus](https://tableplus.com/) is very similar to Navicat in the sense that it’s another lightweight database manager. The main differences are:
|
||||
|
||||
- Tableplus only supports SQL-based databases.
|
||||
- The pricing model is simpler, by only charging a one-time license without you having to commit to a monthly subscription.
|
||||
|
||||

|
||||
|
||||
Some of the most relevant features of Tableplus are:
|
||||
|
||||
- Inline data editing.
|
||||
- Advanced filtering lets you combine different filtering conditions when searching.
|
||||
- Code auto-complete, which comes in very handy when writing SQL queries.
|
||||
- Extensible through JavaScript plugins (currently in Beta).
|
||||
|
||||
This is a solid backend tool alternative to any of the previous options and with a simpler price tag.
|
||||
|
||||
### 9. DBeaver
|
||||
|
||||
[DBeaver](https://dbeaver.io/) is a free, cross-platform tool that lets you connect and interact with multiple databases. While there is a PRO version with extra features, the free version is more than powerful enough to get you started with almost any database you can think of, both SQL and NoSQL alike.
|
||||
|
||||
For a full list of supported databases on the free version, check out their [about page](https://dbeaver.io/about/).
|
||||
|
||||

|
||||
|
||||
Some of the major features of DBeaver are:
|
||||
|
||||
- SQL editor with completion.
|
||||
- ER-diagram creation from a table definition.
|
||||
- In-line data editing.
|
||||
|
||||
Task management to kill any long-lasting queries that block your database.
|
||||
|
||||
## Collaboration tools for web development
|
||||
|
||||
Unless you’re working as a solo-dev (and even then!), collaboration tools allow you to coordinate your work and understand who’s working on what and what you should be working on next.
|
||||
|
||||
While these might not be considered “backend tools” per se, they definitely help improve your performance and organization, so we can still call them “development tools” as a broader term.
|
||||
|
||||
### 10. Trello
|
||||
|
||||
[Trello](https://trello.com/) is a very simple yet powerful organizational tool that lets teams build a Kanban-like board with clear states and simple UX (drag&drop is king in Trello).
|
||||
|
||||
Setting up a new project and a team takes minutes in Trello, and through the plugin system, you can get extra features such as date reminders, calendar integrations, and more.
|
||||
|
||||

|
||||
|
||||
The simple UI and intuitive UX make Trello one of the best options out there for collaborative tools as long as the needs of the team are met with simple column-based layouts and minimal information.
|
||||
|
||||
### 11. Monday
|
||||
|
||||
[Monday](https://monday.com/) is a relatively new online platform for project management and collaboration. I say “new” because some of the other alternatives here have been around for over 5+ years.
|
||||
|
||||
Their limited free plan lasts forever, so if you have a small team and limited requirements, this might just be the perfect tool for you. Also, if you actually need to pay, Monday’s plans are accessible, especially when compared to other alternatives.
|
||||
|
||||

|
||||
|
||||
Monday’s fully customizable UI lets you build the collaborative environment you need. This is a huge advantage over others who've been around for longer and have a fixed UI that you have to adapt to.
|
||||
|
||||
### 12. Basecamp
|
||||
|
||||
[Basecamp](https://basecamp.com/) is a mix between Trello, Monday, and Notion in the sense that it tries to provide developers with the best and most relevant tools from those worlds, leaving out the ones that just create “noise.”
|
||||
|
||||

|
||||
|
||||
Basecamp’s philosophy is to keep things simple and only focus on the features that truly add to collaboration:
|
||||
|
||||
- Simple card tables like Trello.
|
||||
- Ability to upload and manage documents and files with your team.
|
||||
- Integrated chat.
|
||||
- Message boards to send notifications to everyone.
|
||||
|
||||
The only “downside” to basecamp, if you will, is that there is no “forever free” plan. Both their plans are paid and have a 30-day free trial, so you can definitely give it a shot and figure out if what they offer is enough for your needs.
|
||||
|
||||
### 13. Wrike
|
||||
|
||||
[Wrike](https://www.wrike.com/) is yet another attempt at making project management and collaboration feel organic and seamless. They have a minimalistic UI and provide you with over 400 integrations to create your own workflows based on your needs and current ecosystem.
|
||||
|
||||
They have a free plan that, while feature-limited, it’s perfect for understanding the basic way of using Wrike and how useful it can be to you in your current project.
|
||||
|
||||

|
||||
|
||||
Their innovative use of AI allows you to create content faster, analyze project and task descriptions, and create subtasks based on it.
|
||||
|
||||
Wrike feels efficient and powerful, even for its free plan. Give it a chance if you’re a freelancer or if you have a small team looking for something new and powerful.
|
||||
|
||||
## Hosting Services
|
||||
|
||||
When it comes to backend development, deploying your code and running it on the cloud will be a common thing; this is a practice known as continuous integration and continuous deployment (CI/CD). While in some situations, you’ll be dealing with a custom, in-house infrastructure, there are platforms that will make the entire process very lightweight (as in deploying with a couple of clicks).
|
||||
|
||||
Let’s take a look at some of the most common alternatives!
|
||||
|
||||
### 14. Railway
|
||||
|
||||
[Railway.app](https://railway.app/) aims at giving developers all the tools they need at a click’s distance. We’re talking about:
|
||||
|
||||
- PR-triggered deployments.
|
||||
- Support for all popular programming languages.
|
||||
- Autoscaling.
|
||||
- Load balancing.
|
||||
- Monitoring.
|
||||
- A great uptime (99.95%)
|
||||
- With more than 200 ready-made templates for you to get going.
|
||||
|
||||

|
||||
|
||||
Railway has no free plan, but their basic one is very accessible. Careful though, they also charge per resource utilization. Lucky for you, they have a [very handy consumption calculator](https://railway.app/pricing) to avoid surprises at the end of the month!
|
||||
|
||||
### 15. Heroku
|
||||
|
||||
[Heroku](https://www.heroku.com/) is another Platform as a Service provider. This one provides the basic services most of them do, such as autoscaling, monitoring, GitHub integration, and more.
|
||||
|
||||
The list of supported programming languages is not huge, but the most common ones are definitely covered: Node.js, Ruby, JAVA, PHP, Python, Go, Scala, and even Clojure.
|
||||
|
||||

|
||||
|
||||
Another great selling point for Heroku is that on top of their infrastructure, they also offer a managed Postgre database as a service and a Redis one. In both situations, you’ll have to pay for the services as you use them, so keep that in mind.
|
||||
|
||||
### 16. Digital Ocean
|
||||
|
||||
As opposed to platforms such as Heroku, [Digital Ocean](https://www.digitalocean.com/) is known as an Infrastructure as a Service provider (IaaS). They give you all the servers you need and all the resources (memory, CPU, etc) you want to pay for. However, setting up your deployment process, automating your integration tests, or even having all the required libraries to run your code is up to you.
|
||||
|
||||
This is by no means something bad, some teams do prefer to have that freedom over other platforms like Railway and Heroku, where everything’s already managed.
|
||||
|
||||

|
||||
|
||||
Large-scale applications will usually require to have custom infrastructure that managed services can hardly provide. This is where IaaS providers come in.
|
||||
|
||||
On top of their basic offering, they do offer managed databases such as MongoDB, MySQL, Redis, and others.
|
||||
|
||||
### 17. Hetzner
|
||||
|
||||
[Hetzner](https://www.hetzner.com/) is yet another IaaS that offers everything you need to get going if you know what to do with it. In other words, they offer all the hardware you might dream of, even in the cloud, but you have to configure it and maintain it.
|
||||
|
||||
Their only “managed” offer is for web hosting though, so if you’re looking to host your website or app and you don’t want to have to deal with server maintenance and configuration, then this is a good option for you.
|
||||
|
||||

|
||||
|
||||
Other than that, their offering is quite standard, although their pricing model might not be. While they do have the standard pricing tiers like the rest of them, they also give you the option to “bid” for used hardware that is no longer needed.
|
||||
|
||||
### 18. Vercel
|
||||
|
||||
If you’re building a NextJS application and you’re looking for a quick way to deploy it, then there is probably no better place than [Vercel](https://vercel.com/) (the owner of NextJS).
|
||||
|
||||
Their platform allows you to link your GitHub account to their systems and deploy your entire application with a single push to the repo.
|
||||
|
||||

|
||||
|
||||
And since they’re experts on NextJS, your app will “just work.”
|
||||
|
||||
Even their free plan is perfect for quick SaaS prototypes and small applications. On top of this, they offer monitoring, auto-scaling, load balancing, and everything you’d expect from a PaaS provider.
|
||||
|
||||
While it’s true they don’t support other technologies or even offer other related services, such as managed databases, there is hardly anyone who can provide a better developer experience when it comes to deploying a NextJS application.
|
||||
|
||||
### 19. Render
|
||||
|
||||
You can think of [Render](https://render.com/) as if Vercel and Heroku had a love child. Render gives you the amazing developer experience provided by Vercel but the flexibility (or more) from Heroku.
|
||||
|
||||
You’re not tied to a single technology; instead, you have all the major runtimes available out of the box. Much higher HTTP timeouts (up to 100 minutes, which is incredible compared to the standard 10 or 30 seconds most providers give you) and tons of other security and quality-of-life improvements.
|
||||
|
||||

|
||||
|
||||
Render also offers managed MySQL and managed Redis instances for you to use, even in their free tier. In the end, unless you’ve been using Heroku for a while and you’re happy with their DX, it might be a good idea to check out Render instead.
|
||||
|
||||
### 20. OVHCloud
|
||||
|
||||
[OVHCloud](https://www.ovhcloud.com/) is an all-in-one solution that seems to provide you with everything you need, from “bare metal” (as in infrastructure) to managed hosting for web applications, managed databases (they have many to choose from), and many other services.
|
||||
|
||||
However, they do not seem to offer quality-of-life integrations to make your deployment workflow simple and intuitive.
|
||||
|
||||

|
||||
|
||||
Now, given how they centralize all related services from domain name registration all the way up to analytics, identity management, file storage (CDN), and even one-click install CMS (content management systems, such as WordPress), etc, it might just be a good option for you. That is if you have the expertise in your team to deal with all these options.
|
||||
|
||||
## API-Related Tools
|
||||
|
||||
As backend developers, we’ll always be dealing with APIs (Application Programming Interface), either through using the ones created by others or writing our own.
|
||||
|
||||
Whatever you’re doing, it’s always good to have some backend tools to help you build and test them faster, so let’s take a look at a few options.
|
||||
|
||||
### 21. Swagger
|
||||
|
||||
Some developers would argue that one of the hardest parts of creating an API is documenting it. Not only because it might sound like a boring task, but explaining what the API endpoint is doing well enough is not trivial.
|
||||
|
||||
That’s where [Swagger](https://swagger.io/) comes into play.
|
||||
|
||||

|
||||
|
||||
This tool allows you to create interactive documentation that provides developers with all they need to understand how to use your endpoints, and at the same time, it also gives them the option to test them directly from the generated UI.
|
||||
|
||||
### 22. Postman
|
||||
|
||||
[Postman](https://www.postman.com/) is less of a documentation-only app and has grown over the years to become a testing API tool that every developer and development team should know about. Backend developers are especially benefited from using Postman because of how well it helps organize and manage APIs.
|
||||
|
||||
With Postman, you can organize all your company’s APIs, share them with the associated dev teams, and let them use and interact with them without having to write a single line of code.
|
||||
|
||||

|
||||
|
||||
While Swagger is more of a development tool that every backend developer should know about, Postman is the tool that every development team should use to share & control internal API access and documentation.
|
||||
|
||||
## Productivity
|
||||
|
||||
Finally, the last category is about productivity. While some of the products and services mentioned already do provide productivity enhancements, they weren’t there for that. The following list of backend tools is created thinking only about the benefits they can bring to your productivity while working as a backend developer.
|
||||
|
||||
### 23. iTerm
|
||||
|
||||
If you’re a macOS user, then [iTerm](https://iterm2.com/) is definitely one of the “must haves” you need to look into. As a backend developer, you’ll spend a lot of your day in the terminal.
|
||||
|
||||

|
||||
|
||||
iTerm will take that experience to the next level by bringing in features such as:
|
||||
|
||||
- Parallel panes inside the same window making it easy to multi-task.
|
||||
- Improved auto-complete
|
||||
- In-window search outside of the current program you’re using.
|
||||
- Instant replay lets you review the latest content on the screen before cleaning it.
|
||||
- Paste history, letting you move through the latest pasted content into the terminal.
|
||||
|
||||
Mind you, none of these features are mandatory; you can easily work without them, but they do improve your quality of life as a developer. Hence the reason why iTerm leads this list.
|
||||
|
||||
### 24. Zsh/OhMyZsh
|
||||
|
||||
The combination of these two gives your terminal superpowers. [Zsh](https://zsh.sourceforge.io/) is an improved shell that lets you work much faster and more efficiently if you’re spending several hours typing commands in your terminal. For example, you get features such as:
|
||||
|
||||
- Advanced tab auto-complete
|
||||
- Extensibility
|
||||
- Spelling corrections
|
||||
- And more.
|
||||
|
||||

|
||||
|
||||
As mentioned above, after you have your ZSH installed and set up, you should look into installing oh-my-zsh, which helps with configuring all the customization options you have on this shell:
|
||||
|
||||
- It comes bundled with [over 300 plugins](https://github.com/ohmyzsh/ohmyzsh/wiki/Plugins), ranging from 1password integrations to the “jump” plugin, which lets you move around the filesystem by moving from mark to mark (you can assign marks to folders).
|
||||
- [Plenty of themes](https://github.com/ohmyzsh/ohmyzsh/wiki/Themes) out of the box.
|
||||
|
||||
If you find yourself spending hours on the terminal, consider installing this combo.
|
||||
|
||||
### 25. Raycast
|
||||
|
||||
[Raycast](https://www.raycast.com/) allows you to improve your productivity by giving you a better application launcher. Instead of using the default launcher, you can replace it with Raycast and gain superpowers.
|
||||
|
||||
Now, you suddenly have access to hundreds of [community-created extensions](https://www.raycast.com/store) that allow you to directly interact with chatGPT from the app launcher, use GitHub, interact with VSCode directly, and more.
|
||||
|
||||

|
||||
|
||||
While it is only available for macOS users, Raycast has become a must-have application for backend developers on this platform. In the end, the faster you can reach for your tools, the more productive you become. And a properly configured Raycast can make your web development process feel like a breeze.
|
||||
@@ -1,443 +0,0 @@
|
||||
---
|
||||
title: 'Top 7 Backend Frameworks to Use in 2025: Pro Advice'
|
||||
description: 'Get expert advice on backend frameworks for 2024. Learn about the top 7 frameworks that can elevate your development process.'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/backend/frameworks'
|
||||
seo:
|
||||
title: 'Top 7 Backend Frameworks to Use in 2025: Pro Advice'
|
||||
description: 'Get expert advice on backend frameworks for 2024. Learn about the top 7 frameworks that can elevate your development process.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/top-backend-frameworks-jfpux.jpg'
|
||||
relatedTitle: "Other Guides"
|
||||
relatedGuidesId: backend
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2024-09-27
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Choosing the right backend framework in 2025 can be crucial when you’re building web applications. While the programming language you pick is important, the backend framework you go with will help define how scalable, secure, and maintainable your application is. It’s the foundation that supports all the features your users interact with on the frontend and keeps everything running smoothly behind the scenes.
|
||||
|
||||
So, it’s a decision you want to get right.
|
||||
|
||||
In 2024, [backend development](https://roadmap.sh/backend) is more complex and interconnected than ever. Developers are working with APIs, microservices, cloud-native architectures, and ensuring high availability while keeping security at the forefront. It’s an era where the demand for real-time data, seamless integrations, and efficient performance is higher than ever.
|
||||
|
||||
Whether you're building an enterprise-level application or a small startup, the right backend framework can save you time and headaches down the road.
|
||||
|
||||
Let’s take a look at the following top backend development frameworks at the top of all lists for 2024:
|
||||
|
||||
* NextJS
|
||||
* Fastify
|
||||
* SvelteKit
|
||||
* Ruby on Rails
|
||||
* Laravel
|
||||
* Phoenix
|
||||
* Actix
|
||||
|
||||
## Criteria for Evaluating The Top Backend Frameworks
|
||||
|
||||
How can you determine what “best backend framework” means for you? To answer that question, I’ll define a set of key factors to consider. Let’s break down the most important criteria that will help you make the best choice for your project:
|
||||
|
||||
**Performance**:
|
||||
|
||||
* A high-performing backend framework processes server-side tasks (e.g., database queries, user sessions, real-time data) quickly and efficiently.
|
||||
* Faster processing improves user experience, especially in 2025 when speed is critical.
|
||||
|
||||
**Scalability**:
|
||||
|
||||
* The framework should handle increased traffic, larger datasets, and feature expansion without issues.
|
||||
* It should smoothly scale for both small and large user bases.
|
||||
|
||||
**Flexibility**:
|
||||
|
||||
* A flexible framework adapts to new business or technical requirements.
|
||||
* It should support various project types without locking you into a specific structure.
|
||||
|
||||
**Community and Ecosystem**:
|
||||
|
||||
* A strong community provides support through tutorials, forums, and third-party tools.
|
||||
* A good ecosystem includes useful plugins and integrations for popular services or databases.
|
||||
|
||||
**Learning Curve**:
|
||||
|
||||
* An easy-to-learn framework boosts productivity and helps you get up to speed quickly.
|
||||
* A framework should balance ease of learning with powerful functionality.
|
||||
|
||||
**Security**:
|
||||
|
||||
* A reliable framework includes built-in security features to protect user data and prevent vulnerabilities.
|
||||
* It should help you comply with regulations and address security concerns from the start.
|
||||
|
||||
**Future-Proofing**:
|
||||
|
||||
* Choose a framework with a history of updates, a clear development roadmap, and a growing community.
|
||||
* A future-proof framework ensures long-term support and relevance.
|
||||
|
||||
### My go-to backend framework
|
||||
|
||||
My favorite backend framework is Next.js because it has the highest scores from the group.
|
||||
|
||||
That said, I’ve applied the above criteria to the best backend development frameworks I’m covering below in this guide. This table gives you a snapshot view of how they all compare according to my ratings, and I’ll explain the details further below.
|
||||
|
||||

|
||||
|
||||
Of course, Next.js is the best one for me, and that works for me alone. You have to consider your own projects and your own context to understand what the best choice for you would be.
|
||||
|
||||
Let’s get into the selection and what their strengths and weaknesses are to help you select the right one for you.
|
||||
|
||||
## Top 7 Backend Frameworks in 2025
|
||||
|
||||
### Next.js
|
||||
|
||||

|
||||
|
||||
Next.js is a full-stack React framework and one of the most popular backend frameworks in the JavaScript community. Over the years, it has evolved into a robust web development solution that supports static site generation (SSG), server-side rendering (SSR), and even edge computing. Backed by Vercel, it’s now one of the go-to frameworks for modern web development.
|
||||
|
||||
#### 1\. Performance
|
||||
|
||||
Next.js has a wonderful performance thanks to its ability to optimize for both static and dynamic generation. With server-side rendering and support for edge computing, it's built to handle high-performance requirements. Additionally, automatic code splitting ensures only the necessary parts of the app are loaded, reducing load times.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 2\. Scalability
|
||||
|
||||
Next.js is designed to scale easily, from small static websites to large-scale dynamic applications. Its ability to turn backend routes into serverless functions puts it at an unfair advantage over other frameworks. Paired with Vercel’s deployment platform, scaling becomes almost effortless.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 3\. Flexibility
|
||||
|
||||
Next.js is one of the most flexible frameworks out there. It supports a wide range of use cases, from simple static websites to highly complex full-stack applications. With its API routes feature, developers can create powerful backends, making Next.js suitable for both frontend and backend development in a single framework.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 4\. Community and Ecosystem
|
||||
|
||||
The Next.js community (just like the JavaScript community in general) is large and quite active, with an ever-growing number of plugins, integrations, and third-party tools. The framework has solid documentation and an active ecosystem, thanks to its close ties to both the React community and Vercel’s developer support.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 5\. Learning Curve
|
||||
|
||||
For developers already familiar with React, Next.js provides a relatively smooth learning curve. However, for those new to SSR, SSG or even RSC (React Server Components), there’s a bit of a learning curve as you adapt to these concepts (after all, you’re learning React and backend development at the same time). That said, the framework's excellent documentation and active community make it easier to grasp.
|
||||
|
||||
⭐ **Rating: 4/5**
|
||||
|
||||
#### 6\. Security
|
||||
|
||||
Next.js doesn’t inherently have a wide array of built-in security tools, but it follows secure default practices and can be paired with Vercel’s security optimizations for additional protection. Out of the box, Next.js ensures some level of security against common web threats but will need further configuration depending on the app's complexity.
|
||||
|
||||
⭐ **Rating: 3.5/5**
|
||||
|
||||
#### 7\. Future-Proofing
|
||||
|
||||
Backed by Vercel, Next.js has a bright future. Vercel consistently pushes updates, introduces new features, and improves the overall developer experience. Given its adoption and strong support, Next.js is very future-proof, with no signs of slowing down.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
### Fastify
|
||||
|
||||

|
||||
|
||||
Fastify is a lightweight and fast backend framework for Node.js, often seen as a high-performance alternative to Express.js. It was created with a strong focus on speed, low overhead, and developer-friendly tooling, making it a popular choice for developers building APIs and microservices. Fastify offers a flexible plugin architecture and features like schema-based validation and HTTP/2 support, setting it apart in the Node.js ecosystem.
|
||||
|
||||
#### 1\. Performance
|
||||
|
||||
Fastify shines when it comes to performance. It’s optimized for handling large amounts of requests with low latency, making it one of the fastest Node.js frameworks available.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 2\. Scalability
|
||||
|
||||
With a strong focus on scalability, Fastify is ideal for handling large applications and high-traffic scenarios. Its lightweight nature ensures that you can build scalable services with minimal resource consumption.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 3\. Flexibility
|
||||
|
||||
Fastify’s [plugin architecture](https://fastify.dev/docs/latest/Reference/Plugins/) is one of its key strengths. This allows developers to easily extend the framework’s capabilities and tailor it to specific use cases, whether you’re building APIs, microservices, or even server-rendered applications.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 4\. Community and Ecosystem
|
||||
|
||||
While Fastify’s community is not as large as Express.js or Next.js, it is steadily growing. The ecosystem of plugins and tools continues to expand, making it easier to find the right tools and libraries to fit your needs. However, its smaller ecosystem means fewer third-party tools compared to some of the more established frameworks.
|
||||
|
||||
⭐ **Rating: 3/5**
|
||||
|
||||
#### 5\. Learning Curve
|
||||
|
||||
If you’re coming from Express.js or another Node.js framework, Fastify’s learning curve is minimal. Its API is designed to be familiar and easy to adopt for Node.js developers. While there are some differences in how Fastify handles things like schema validation and plugins, it’s a relatively smooth transition for most developers.
|
||||
|
||||
⭐ **Rating: 4/5**
|
||||
|
||||
#### 6\. Security
|
||||
|
||||
Fastify incorporates built-in security features such as schema-based validation, which helps prevent vulnerabilities like injection attacks. The framework also supports HTTP/2 out of the box, which provides enhanced security and performance.
|
||||
|
||||
⭐ **Rating: 4/5**
|
||||
|
||||
#### 7\. Future-Proofing
|
||||
|
||||
Fastify has a strong development roadmap and is [consistently updated](https://github.com/fastify/fastify) with performance improvements and new features. The backing from a growing community and its continued adoption by large-scale applications make Fastify a solid bet for long-term use.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
### SvelteKit
|
||||
|
||||

|
||||
|
||||
SvelteKit is a full-stack framework built on top of Svelte, a front-end compiler that moves much of the heavy lifting to compile time rather than runtime. SvelteKit was designed to simplify building modern web applications by providing server-side rendering (SSR), static site generation (SSG), and support for client-side routing—all in a performance-optimized package. In other words, it’s an alternative to Next.js.
|
||||
|
||||
#### 1\. Performance
|
||||
|
||||
SvelteKit leverages Svelte compile-time optimizations, resulting in fast runtime performance. Unlike frameworks that rely heavily on virtual DOM diffing, Svelte compiles components to efficient JavaScript code, which means fewer resources are used during rendering.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 2\. Scalability
|
||||
|
||||
While SvelteKit is excellent for small to medium-sized applications, its scalability for enterprise-level applications is still being tested by the developer community. It is possible to scale SvelteKit for larger applications, especially with the right infrastructure and server setup, but it may not yet have the same level of proven scalability as more mature frameworks like Next.js or Fastify.
|
||||
|
||||
⭐ **Rating: 4/5**
|
||||
|
||||
#### 3\. Flexibility
|
||||
|
||||
As with most web frameworks, SvelteKit is highly flexible, allowing developers to build everything from static sites to full-stack robust web applications. It provides SSR out of the box, making it easy to handle front-end and back-end logic in a single codebase. Additionally, it supports various deployment environments like serverless functions or traditional servers.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 4\. Community and Ecosystem
|
||||
|
||||
The SvelteKit community is growing rapidly, and more tools, plugins, and resources are being developed to support it. While the ecosystem isn’t as mature as frameworks like React or Vue, the rate of adoption is promising. The official documentation is well-written, and there’s a growing number of third-party tools, libraries, and guides available for developers to tap into.
|
||||
|
||||
⭐ **Rating: 3.5/5**
|
||||
|
||||
#### 5\. Learning Curve
|
||||
|
||||
For developers familiar with Svelte, the transition to SvelteKit is smooth and intuitive. However, if you're new to Svelte, there is a moderate learning curve, particularly in understanding Svelte’s reactivity model and SvelteKit's routing and SSR features. Still, the simplicity of Svelte as a framework helps ease the learning process compared to more complex frameworks like React or Angular.
|
||||
|
||||
⭐ **Rating: 4/5**
|
||||
|
||||
#### 6\. Security
|
||||
|
||||
SvelteKit’s security features are still evolving, with basic protections in place but requiring developers to implement best practices to build really secure web applications. There are no significant built-in security tools like in some larger frameworks, so developers need to be cautious and handle aspects like input validation, cross-site scripting (XSS) protection, and CSRF manually.
|
||||
|
||||
⭐ **Rating: 3/5**
|
||||
|
||||
#### 7\. Future-Proofing
|
||||
|
||||
Svelte’s increasing popularity and SvelteKit’s rapid development signal a bright future for the framework. The growing adoption of Svelte, backed by its simplicity and performance, ensures that SvelteKit will continue to be developed and improved in the coming years.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
### Ruby on Rails
|
||||
|
||||

|
||||
|
||||
Ruby on Rails (Rails) is a full-stack web development framework written in Ruby, created by David Heinemeier Hansson in 2004\. Rails revolutionized web development by promoting "convention over configuration" and allowing developers to rapidly build web applications with fewer lines of code. It
|
||||
|
||||
#### 1\. Performance
|
||||
|
||||
Rails performs exceptionally well for typical CRUD (Create, Read, Update, Delete) applications, where database operations are straightforward and heavily optimized within the framework. However, as applications grow in complexity or require real-time features, Rails’ performance can become a challenge.
|
||||
|
||||
⭐ **Rating: 3.5/5**
|
||||
|
||||
#### 2\. Scalability
|
||||
|
||||
Rails is often critiqued for its scalability limitations, but it can scale when combined with proper architecture and best practices. Techniques like database sharding, horizontal scaling, and using background jobs for heavy-lifting tasks can help. Still, it’s not the first choice for developers who anticipate massive scale, as it requires careful planning and optimization to avoid performance bottlenecks.
|
||||
|
||||
⭐ **Rating: 3.5/5**
|
||||
|
||||
#### 3\. Flexibility
|
||||
|
||||
Rails is a great framework for rapid development, especially for standard web applications, such as e-commerce platforms, blogs, or SaaS products. However, it’s less flexible when it comes to non-standard architectures or unique application needs. It’s designed with conventions in mind, so while those conventions help you move fast, they can become restrictive in more unconventional use cases.
|
||||
|
||||
⭐ **Rating: 3.5/5**
|
||||
|
||||
#### 4\. Community and Ecosystem
|
||||
|
||||
Next to JavaScript with NPM, Rails has one of the most mature ecosystems in web development, with a huge repository of gems (libraries) that can help speed up development. From user authentication systems to payment gateways, there’s a gem for almost everything, saving developers from reinventing the wheel. The community is also very active, and there are many resources, tutorials, and tools to support developers at every level.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 5\. Learning Curve
|
||||
|
||||
Rails is known for its easy learning curve, especially for those new to web development. The framework’s focus on convention over configuration means that beginners don’t need to make many decisions and can get a functional app up and running quickly. On top of that, Ruby’s readable syntax also makes it approachable for new devs.
|
||||
|
||||
However, as the application grows, mastering the framework’s more advanced concepts and learning how to break through those pre-defined conventions can become a bit of a problem.
|
||||
|
||||
⭐ **Rating: 4/5**
|
||||
|
||||
#### 6\. Security
|
||||
|
||||
Rails comes with a solid set of built-in security features, including protections against SQL injection, XSS (cross-site scripting), and CSRF (cross-site request forgery). By following Rails' conventions, developers can implement secure practices without much additional work. However, as with any framework, you still need to stay updated on security vulnerabilities and ensure proper coding practices are followed.
|
||||
|
||||
⭐ **Rating: 4.5/5**
|
||||
|
||||
#### 7\. Future-Proofing
|
||||
|
||||
While Rails is still highly relevant and widely used, its growth has slowed down from its initial hype during 2010, and it’s no longer the hot, new framework. That said, it remains a solid choice for many businesses, especially those building content-heavy or e-commerce applications. With an established user base and regular updates, Rails is not going anywhere, but its popularity may continue to wane as newer frameworks gain traction.
|
||||
|
||||
⭐ **Rating: 4/5**
|
||||
|
||||
### Laravel
|
||||
|
||||

|
||||
|
||||
Laravel is a PHP backend framework that was introduced in 2011 by Taylor Otwell. It has since become one of the most popular frameworks in the PHP ecosystem, known for its elegant syntax, ease of use, and focus on developer experience (known to some as the RoR of PHP). Laravel offers a range of built-in tools and features like routing, authentication, and database management, making it ideal for building full-featured web applications quickly.
|
||||
|
||||
#### 1\. Performance
|
||||
|
||||
Laravel performs well for most typical web applications, especially CRUD operations. However, for larger, more complex applications, performance can be a concern. Using tools like caching, query optimization, and Laravel’s built-in optimization features (such as queue handling and task scheduling) can help boost performance, but some extra work may be required for high-load environments.
|
||||
|
||||
⭐ **Rating: 4/5**
|
||||
|
||||
#### 2\. Scalability
|
||||
|
||||
Laravel can scale, but like Rails, it requires careful attention to architecture and infrastructure. By using horizontal scaling techniques, microservices, and services like AWS or Laravel’s Vapor platform, you can build scalable applications. However, Laravel is often seen as better suited for small to medium applications without heavy scaling needs right out of the box.
|
||||
|
||||
⭐ **Rating: 3.5/5**
|
||||
|
||||
#### 3\. Flexibility
|
||||
|
||||
Laravel is highly flexible, allowing you to build a wide variety of web applications. With built-in features for routing, ORM, middleware, and templating, you can quickly build anything from small websites to enterprise applications.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 4\. Community and Ecosystem
|
||||
|
||||
Contrary to popular belief (mainly due to a lack of hype around the technology), Laravel has a large, active community and a vast ecosystem of packages and third-party tools. With Laracasts, a popular video tutorial platform, and Laravel.io the community portal for Laravel developers, there are many ways to reach out and learn from others.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 5\. Learning Curve
|
||||
|
||||
Laravel has a relatively gentle learning curve, especially for developers familiar with PHP. Its focus on simplicity, readable syntax, and built-in features make it easy to pick up for beginners. However, mastering the full list of Laravel’s capabilities and best practices can take some time for more complex projects.
|
||||
|
||||
⭐ **Rating: 4.5/5**
|
||||
|
||||
#### 6\. Security
|
||||
|
||||
Just like others, Laravel comes with built-in security features, such as protection against common vulnerabilities like SQL injection, cross-site scripting (XSS), and cross-site request forgery (CSRF). The framework adheres to best security practices, making it easier for developers to build secure applications without much extra effort.
|
||||
|
||||
⭐ **Rating: 4.5/5**
|
||||
|
||||
#### 7\. Future-proofing
|
||||
|
||||
Laravel is still highly relevant and continues to grow in popularity (having [recently secured a very substantial](https://laravel-news.com/laravel-raises-57-million-series-a) amount of money). It has a regular release schedule and a strong commitment to maintaining backward compatibility. With its consistent updates, active community, and growing ecosystem, Laravel is a solid choice for long-term projects.
|
||||
|
||||
⭐ **Rating: 4.5/5**
|
||||
|
||||
### Phoenix
|
||||
|
||||

|
||||
|
||||
#### **Overview and History**
|
||||
|
||||
Phoenix is a backend framework written in Elixir, designed to create high-performance, scalable web applications. It leverages Elixir's concurrency and fault-tolerant nature (inherited from the Erlang ecosystem) to build real-time, distributed systems.
|
||||
|
||||
#### 1\. Performance
|
||||
|
||||
Phoenix is known for its outstanding performance, particularly in handling large numbers of simultaneous connections. Thanks to Elixir’s concurrency model and lightweight processes, Phoenix can serve thousands of requests with minimal resource consumption. Real-time applications benefit especially from Phoenix’s built-in WebSockets and its LiveView feature for updating UIs in real-time without the need for JavaScript-heavy frameworks.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 2\. Scalability
|
||||
|
||||
Scalability is one of Phoenix’s biggest features. Because it runs on the Erlang VM, which was designed for distributed, fault-tolerant systems, Phoenix can scale horizontally and vertically with ease.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 3\. Flexibility
|
||||
|
||||
Phoenix is highly flexible, supporting everything from traditional web applications to real-time applications like chat apps and live updates. Its integration with Elixir’s functional programming paradigm and the BEAM virtual machine allows developers to build fault-tolerant, systems. The flexibility extends to how you can structure applications, scale components, and handle real-time events seamlessly.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 4\. Community and Ecosystem
|
||||
|
||||
Phoenix has a growing and passionate community, but it’s still smaller compared to more established frameworks like Rails or Laravel. However, it benefits from Elixir’s ecosystem, including libraries for testing, real-time applications, and database management. The community is supportive, and the framework’s documentation is detailed and developer-friendly, making it easy to get started.
|
||||
|
||||
⭐ **Rating: 2.5/5**
|
||||
|
||||
#### 5\. Learning Curve
|
||||
|
||||
Phoenix, being built on Elixir, has a steeper learning curve than frameworks based on more common languages like JavaScript or PHP. Elixir’s functional programming model, while powerful, can be challenging for developers unfamiliar with the paradigm.
|
||||
|
||||
⭐ **Rating: 3.5/5**
|
||||
|
||||
#### 6\. Security
|
||||
|
||||
As with most of the popular backend frameworks, Phoenix comes with strong built-in security features, including protections against common vulnerabilities like XSS, SQL injection, and CSRF. Additionally, because Elixir processes are isolated, Phoenix applications are resilient to many types of attacks. While some manual work is still required to ensure security, Phoenix adheres to best practices and provides tools to help developers write secure code.
|
||||
|
||||
⭐ **Rating: 4.5/5**
|
||||
|
||||
#### 7\. Future-Proofing
|
||||
|
||||
Phoenix has a bright future thanks to its solid foundation in the Erlang/Elixir ecosystem, which is known for long-term reliability and support. While the framework might be technologically sound and future-proof, the key to having Elixir in the future will depend on the growth of its popularity. If Elixir’s community keeps growing, we’ll be able to enjoy the framework for a long time.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
### Actix
|
||||
|
||||

|
||||
|
||||
Actix is a powerful, high-performance web framework written in Rust. It’s based on the actor model, which is ideal for building concurrent, distributed systems. Actix is known for its incredible performance and memory safety, thanks to Rust’s strict compile-time guarantees.
|
||||
|
||||
#### 1\. Performance
|
||||
|
||||
Actix is one of the fastest web frameworks available, thanks to Rust’s system-level performance and Actix’s use of asynchronous programming. As it happens with JavaScript-based frameworks, it can handle a large number of requests with minimal overhead, making it ideal for high-performance, real-time applications.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 2\. Scalability
|
||||
|
||||
The actor model makes Actix the best at handling concurrent tasks and scaling across multiple threads or servers. Rust’s memory safety model and Actix’s architecture make it highly efficient in resource usage, meaning applications can scale well without excessive overhead.
|
||||
|
||||
⭐ **Rating: 5/5**
|
||||
|
||||
#### 3\. Flexibility
|
||||
|
||||
Actix is flexible but requires a deeper understanding of Rust’s ownership and concurrency model to fully take advantage of it. It’s great for building both small, fast APIs and large, service architectures. While Actix is powerful, it’s less forgiving compared to other popular backend frameworks like Node.js or Python’s Flask, where rapid prototyping is easier.
|
||||
|
||||
⭐ **Rating: 3/5**
|
||||
|
||||
#### 4\. Community and Ecosystem
|
||||
|
||||
Rust’s ecosystem, while growing, is still smaller compared to more established languages like JavaScript or Python. However, the Rust community is highly engaged, and support is steadily improving.
|
||||
|
||||
⭐ **Rating: 3.5/5**
|
||||
|
||||
#### 5\. Learning Curve
|
||||
|
||||
Actix inherits Rust’s learning curve, which can be steep for developers new to systems programming or Rust’s strict memory management rules. However, for developers already familiar with Rust, Actix can be a great gateway into web development.
|
||||
|
||||
⭐ **Rating: 2/5**
|
||||
|
||||
#### 6\. Security
|
||||
|
||||
Rust is known for its memory safety and security guarantees, and Actix benefits from these inherent strengths. Rust’s compile-time checks prevent common security vulnerabilities like null pointer dereferencing, buffer overflows, and data races. While these features tackle one side of the security ecosystem, more relevant ones like web-related vulnerabilities are not tackled by the framework.
|
||||
|
||||
⭐ **Rating: 2.5/5**
|
||||
|
||||
#### **7\. Future-Proofing**
|
||||
|
||||
Rust’s growing popularity and adoption, especially in performance-critical areas, ensure that Actix has a strong future. While Actix’s ecosystem is still developing, the framework is regularly maintained and benefits from Rust’s long-term stability.
|
||||
|
||||
⭐ **Rating: 4.5/5**
|
||||
|
||||
## Conclusion
|
||||
|
||||
Choosing the right backend framework is a critical decision that can shape the future of your project. In 2024, developers have more powerful options than ever, from popular backend frameworks like Ruby on Rails, Laravel or Next.js to high-performance focused, like Fastify, SvelteKit, Phoenix, and Actix. Each framework has its own strengths, making it essential to consider factors such as performance, scalability, flexibility, and the learning curve to ensure you pick the right tool for the job.
|
||||
|
||||
Ultimately, there’s no proverbial silver bullet that solves all your problems. Your choice will depend on your project’s needs, your team's expertise, and the long-term goals of your application.
|
||||
|
||||
So take your time, weigh the pros and cons, and pick the framework that aligns best with your vision for the future.
|
||||
@@ -1,274 +0,0 @@
|
||||
---
|
||||
title: "Backend Developer Job Description [@currentYear@ Template]"
|
||||
description: 'Learn how to write the perfect backend developer job description and get my best tips on how to recruit backend dev talent effectively.'
|
||||
authorId: ekene
|
||||
excludedBySlug: '/backend/job-description'
|
||||
seo:
|
||||
title: "Backend Developer Job Description [@currentYear@ Template]"
|
||||
description: ''
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/backend-job-description-nn3ja.png'
|
||||
relatedTitle: "Other Guides"
|
||||
relatedGuidesId: backend
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2024-11-12
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Hiring the right candidate for a [backend engineering](https://roadmap.sh/backend) role requires identifying individuals who possess the necessary technical and soft skills and align with your organization's values. Selecting the right candidate can be challenging with a high volume of applications.
|
||||
|
||||
Knowing what to prioritize when evaluating candidates is necessary for choosing the best fit for this role. In this guide, I’ll outline the key skills and qualities I focus on as a hiring manager when hiring a backend engineer.
|
||||
|
||||
Here is a summary of the backend developer job description:
|
||||
|
||||
- Design, develop, and maintain highly performant, reliable, scalable, and secure backend systems and server side logic.
|
||||
- Oversee projects from conception to deployment, ensuring smooth execution and delivery to create a great and on-brand user experience.
|
||||
- Maintain and optimize the backend infrastructure to meet evolving project needs.
|
||||
- Collaborate with front-end developers to integrate user-facing elements with server-side logic.
|
||||
- Write clean, standardized, maintainable, testable, and reusable backend code to solve business and technical problems.
|
||||
|
||||
Let’s look at the backend engineer role in more detail.
|
||||
|
||||
## Backend engineer job description template
|
||||
|
||||
The job description of a backend developer differs depending on the team, project, or organization. Based on my experience as a backend engineer recruiter, here is a sample job description template that outlines the key skills and qualifications hiring managers look for in potential candidates:
|
||||
|
||||
**Job title: Backend Engineer**
|
||||
|
||||
**Company:** [Company Name]
|
||||
|
||||
**Location:** [Location, region, hybrid, or remote]
|
||||
|
||||
**Job Type:** [Full-time, Part-time, or Contract].
|
||||
|
||||
**About us**
|
||||
[Give a brief introduction of your company and what you do].
|
||||
|
||||
**Job Description**
|
||||
**[Company Name]** is looking for experienced backend engineers who are passionate about building scalable, efficient, and reliable server-side applications. This role requires strong proficiency in server-side languages (such as Python, Java, or Node.js), databases (SQL, NoSQL), and API development. The ideal candidate will have a solid understanding of backend architecture, security best practices, and cloud technologies to support modern applications.
|
||||
|
||||
Collaboration with frontend developers, designers, product managers, and other teams is key to this role, so strong communication skills are important. We are looking for strong problem solvers who can apply their engineering skills across different platforms and environments to deliver the best possible experience for customers and internal users.
|
||||
|
||||
**Responsibilities**
|
||||
|
||||
- Take ownership of the design, architecture, development, deployment and operations of microservices you will develop, using DevOps practices, pair programming and other cutting-edge methodologies.
|
||||
- Promote a highly collaborative environment with other product team members.
|
||||
- Participate in regular technical forums to share knowledge with other engineers.
|
||||
- Be an active member of cross-functional agile teams collaborating with product owners, frontend developers, designers, and business intelligence teams.
|
||||
- Build the server side logic of our web application.
|
||||
|
||||
**Requirements**
|
||||
|
||||
- Solid backend experience with microservice and distributed event-driven architectural patterns
|
||||
- Degree in computer science or any related discipline.
|
||||
- Professional experience with one backend programming language, e.g., Python, C#, Java
|
||||
- Experience working with docker and containerization technologies such as Kubernetes.
|
||||
- A deep understanding of continuous integration and continuous delivery.
|
||||
- Practical experience in applying advanced design concepts such as Domain Driven Design (DDD), Object Oriented Programming (OOP).
|
||||
- Strong communication and collaboration skills.
|
||||
|
||||
**What we offer**
|
||||
[Itemize the different perks you offer, for example, training allowance, competitive salary, home office setup, etc.].
|
||||
|
||||
**How to apply**
|
||||
If this role excites you, please submit your resume and cover letter to **[contact email or link to** **job** **portal]**.
|
||||
|
||||
You have seen what a sample backend engineer job advert looks like; now, let’s have a detailed look at a backend developer’s responsibilities.
|
||||
|
||||
## Key backend developer responsibilities
|
||||
|
||||
The roles and responsibilities of a backend engineer could vary depending on the project requirements, company size, or team structure. However, there are typical roles and responsibilities that cut across board. They include:
|
||||
|
||||
- Server-side development
|
||||
- Application Programming Interface (API) development
|
||||
- Database administration and management
|
||||
- Performance optimization
|
||||
- Integration of third-party services
|
||||
- Testing
|
||||
- Documentation
|
||||
- Collaboration
|
||||
|
||||

|
||||
|
||||
Typical projects that backend developers work on include:
|
||||
|
||||
- RESTful APIs that perform CRUD operations.
|
||||
- Building web scraping and data processing services.
|
||||
- Building image processing services.
|
||||
- Designing and implementing content delivery networks (CDNs).
|
||||
- Modeling and designing database systems.
|
||||
|
||||
Let’s look at their individual responsibilities in detail:
|
||||
|
||||
### Server-side development
|
||||
|
||||
This is one of the core responsibilities of a backend developer. It involves writing server-side web application logic to handle requests from the frontend, communicate with database systems, and handle an application’s business and backend logic.
|
||||
|
||||
### API development
|
||||
|
||||
A backend developer designs, implements, and maintains APIs for communicating between different services or parts of an application and with external systems. This involves creating endpoints, responding to requests, and ensuring API security. [Swagger](https://swagger.io/) is a standard tool used by backend engineers to design and document APIs.
|
||||
|
||||
### Database administration and management
|
||||
|
||||
Data plays a central role in software and application development. A backend developer decides how and where to store these data. Databases are one of the most used data storage solutions, and a backend developer designs and maintains them for efficient data management. The tasks here include deciding which databases to use, either [SQL](https://roadmap.sh/sql) or NoSQL databases, also known as document databases, choosing the right Object Relation Mapper (ORM) for mapping objects to a database, writing efficient queries, optimizing database performance, and ensuring data security.
|
||||
|
||||
### Performance optimization
|
||||
|
||||
Backend engineers continually look for ways to optimize performance. They identify performance bottlenecks such as slow database queries, poor code quality, and high application latency and work towards resolving them. This involves refactoring to ensure high-quality reusable code, updating dependencies, redesigning the database schema, etc.
|
||||
|
||||
### Integration of third-party services
|
||||
|
||||
Some applications integrate with third-party web services or APIs to perform specific tasks. Some of these third-party services include payment gateways, cloud services such as Google Cloud and [Amazon Web Services](https://roadmap.sh/aws), and user authentication services, such as Auth0. Backend engineers integrate these external services into an application.
|
||||
|
||||
### Testing and bug fixing
|
||||
|
||||
Backend engineers write unit, integration, and end-to-end tests to ensure system reliability. These tests help to keep the system *up* and bug-free during continuous development. Troubleshooting and fixing are also part of a backend engineer’s primary responsibility.
|
||||
|
||||
### Documentation
|
||||
|
||||
A backend developer writes and maintains technical specifications, API documentation, and guides for existing and new team members. These documents are forms of knowledge transfer and can be referenced when needed.
|
||||
|
||||
### Collaboration
|
||||
|
||||
Backend engineers collaborate with other team members, including frontend developers, UI/UX designers, project managers, product managers, etc., to achieve a common goal.
|
||||
|
||||
## Skills and qualifications needed to excel as a backend engineer
|
||||
|
||||
A backend engineer needs a combination of soft and technical skills to excel. Some of the skills you should look out for when hiring a backend engineer include:
|
||||
|
||||
- Knowledge of at least one backend programming language
|
||||
- In-depth understanding of databases and caching
|
||||
- Knowledge of Application Programming Interfaces (APIs)
|
||||
- Basic knowledge of web servers
|
||||
- Knowledge of design patterns
|
||||
- Familiarity with version control systems
|
||||
- Understanding of security best practices
|
||||
- Collaboration and communication skills
|
||||
|
||||
### Knowledge of at least one backend programming language
|
||||
|
||||
A [backend developer](https://roadmap.sh/backend/developer-skills) should have an in-depth knowledge of at least one backend programming language, such as [Java](https://roadmap.sh/java), C#, [Python](https://roadmap.sh/python), [Node.js](https://roadmap.sh/nodejs), etc. It is also beneficial for a backend engineer to be familiar with some [backend frameworks](https://roadmap.sh/backend/frameworks) such as Django, [ASP.NET](https://roadmap.sh/aspnet-core), Ruby on Rails, [Sprint Boot](https://roadmap.sh/spring-boot), etc.
|
||||
|
||||

|
||||
|
||||
### In-depth understanding of databases and caching
|
||||
|
||||
A backend developer should know how databases and caching work in robust web applications. Many types of databases are used in backend systems, including relational and document databases. Examples of Database Management Systems used in backend systems include Microsoft SQL Server, PostgreSQL, MySQL, MongoDB, etc.
|
||||
|
||||
[Caching](https://roadmap.sh/guides/http-caching) is a process of temporarily storing data that is requested regularly. It helps avoid recurrent unnecessary database queries. Redis is an example of an in-memory data store used for caching.
|
||||
|
||||
### Knowledge of APIs
|
||||
|
||||
APIs are used to communicate between different systems. These systems could be microservices, frontend and backend systems, or third-party systems. A backend developer is expected to know how to [design APIs](https://roadmap.sh/api-design) and make them available to consumers.
|
||||
|
||||
### Basic knowledge of web servers
|
||||
|
||||
A backend engineer should have a basic understanding of web server technologies. Web servers respond to client requests. An example of a web server is Nginx. During the interview process, you should ensure that the candidate understands how web servers work and also know how to configure them.
|
||||
|
||||
### Knowledge of design patterns
|
||||
|
||||
[Design patterns](https://roadmap.sh/guides/design-patterns-for-humans) are reusable code libraries or solutions to common problems in designing and structuring software components. A backend developer should know some of these design patterns. The common types of design patterns are:
|
||||
|
||||
- Creational patterns
|
||||
- Structural patterns
|
||||
- Behavioral patterns
|
||||
- Architectural patterns
|
||||
|
||||
### Familiarity with version control systems
|
||||
|
||||
Version control systems help track and maintain a history of code changes made to an application. With a proper version control system, multiple developers can work on a codebase simultaneously. Through version control, they collaborate on a code repository.
|
||||
|
||||
A backend engineer is expected to have proficient knowledge of version control. Git is one of the most common version control systems today. There are many code repositories, including Bitbucket, GitHub, and GitLab.
|
||||
|
||||
### Understanding of security best practices
|
||||
|
||||
A backend developer should have a basic understanding of standard security practices and implement robust security measures to protect sensitive data and prevent unauthorized access to data. Common vulnerabilities include SQL injection, cross-site scripting, and cross-site request forgery. About every large cloud provider has features that provide security measures, including AWS IAM, Azure Active Directory, and Google Cloud Identity.
|
||||
|
||||
### Collaboration and communication skills
|
||||
|
||||
A backend developer typically collaborates with other engineers, managers, and testers across multiple teams to ensure consistency and improve user experience. During the interview process, you should pay close attention to the candidate's communication skills because a backend developer should be able to clearly communicate problems and their approach to a solution. Ask the candidate questions that border on collaboration and see how they respond.
|
||||
|
||||
## Additional skills that will make a candidate stand out as a backend developer
|
||||
|
||||
The role of a backend developer is very competitive. However, there are some skills that a backend developer should possess to make them stand out. Some of these skills include:
|
||||
|
||||
- Continuous learning
|
||||
- Problem-solving skills
|
||||
- Time management skills
|
||||
- DevOps skills
|
||||
|
||||
### Continuous learning
|
||||
|
||||
The field of [backend engineering](https://roadmap.sh/backend) is continually expanding, so be sure to look out for candidates who enjoy learning. Find out if they stay up to date with the latest technologies and industry trends and how often they try out new things. In addition to acquiring new skills, you should also find out if they are willing to share knowledge and help in team development.
|
||||
|
||||
### Problem-solving skills
|
||||
|
||||
While it’s essential to use problem-solving tools, intrinsic problem-solving skills are equally important for a backend developer. Your potential hire should have an analytical mindset and be able to break complex problems into smaller chunks that can be solved incrementally.
|
||||
|
||||
### Time management skills
|
||||
|
||||
Engineers sometimes have chaotic workloads, which often lead to burnout and affect their performance. During the interview, ask the candidate about their time management practices and how they manage heavy workloads. Effective time management and prioritizing can make a candidate stand out as an engineer and avoid burnout.
|
||||
|
||||
### DevOps skills
|
||||
|
||||
Knowledge of [docker](https://roadmap.sh/docker) and container orchestration technologies, such as [Kubernetes](https://roadmap.sh/kubernetes) is another skill that makes a backend developer stand out. A firm understanding of continuous integration and continuous deployment (CI/CD) setups is a plus. Consider a candidate with this basic DevOps skill for the role.
|
||||
|
||||
## Common backend engineer job interview questions
|
||||
|
||||
This curated list of the common backend developer job interview questions should help your search:
|
||||
|
||||
**What are the different HTTP methods?**
|
||||
Here, the candidate should be able to explain the different HTTP methods, which are GET, POST, PUT, and DELETE.
|
||||
|
||||
**Describe what you understand** **about continuous integration and continuous delivery**
|
||||
The candidate is expected to explain what CI/CD means in clear terms.
|
||||
|
||||
**What are databases****,** **and what are the different types of databases?**
|
||||
The candidate should know what a database is and what relational and document databases are, along with examples.
|
||||
|
||||
**What is object****-****oriented programming?**
|
||||
The candidate should be able to explain OOP, a process of designing software around objects.
|
||||
|
||||
**Explain the difference between synchronous and asynchronous programming**
|
||||
Here, you should look for the candidate’s understanding of sync and async processes. Synchronous programming executes tasks sequentially, and each task must be completed before the next start. Asynchronous programming allows tasks to run independently without waiting for each other to complete. It uses promises or async/await to handle task completion.
|
||||
|
||||
**What is the purpose of caching in a backend system****,** **and what caching strategies have you used?**
|
||||
The candidate should be able to explain what caching means and also the different caching strategies, which include:
|
||||
|
||||
- Full-page caching
|
||||
- Data caching
|
||||
- Result caching
|
||||
|
||||
**What are some common security vulnerabilities in web applications****,** **and how will you mitigate them?**
|
||||
The candidate should be able to explain common security vulnerabilities, such as cross-site scripting, SQL injection, cross-site request forgery (CSRF), and so on. You can mitigate them by performing proper input validation and secure session management.
|
||||
|
||||
## Effective interview strategies and assessments
|
||||
|
||||
Evaluating backend engineers requires targeted assessments that reveal technical skills and problem-solving abilities. Here are practical techniques to help you identify qualified candidates:
|
||||
|
||||
- **Code review exercises:** Provide a sample code snippet on any backend programming languages with issues or inefficiencies. Ask candidates to identify problems, propose improvements, and explain their reasoning. This exercise tests attention to detail and understanding of best practices.
|
||||
- **Live coding tasks:** Use short coding challenges focused on common backend development tasks like database queries or API calls. Live coding reveals how candidates approach problems under pressure and handle real-time debugging.
|
||||
- **System design discussions:** Present a simple system design prompt, like designing a scalable file storage system. Listen for clarity in explaining their thought process, handling of trade-offs, and understanding of backend fundamentals.
|
||||
- **Behavioral questions on past projects:** Ask about specific backend challenges they’ve faced and how they solved them. Look for evidence of adaptability, collaboration, and knowledge depth, such as experiences with database optimization or API integration.
|
||||
- **Assess communication skills:** Observe how they explain technical concepts. Strong candidates communicate clearly and adapt explanations for both technical and non-technical audiences.
|
||||
|
||||
These methods offer a well-rounded view of a candidate’s backend development skills and experience.
|
||||
|
||||
## What’s next?
|
||||
|
||||
Backend engineers play a vital role in software engineering, and great ones are in high demand. Now that you have a clear understanding of what to look for, it’s time to build a hiring process that identifies candidates with the right technical skills and collaborative mindset.
|
||||
|
||||
The foundation of your tech stack depends on a strong backend. You can find potential hires in the roadmap.sh [community](https://roadmap.sh/discord) of beginner and experienced backend developers.
|
||||
|
||||
roadmap.sh also offers valuable resources to help you and your team stay ahead by helping you to:
|
||||
|
||||
- Create a personalized or [team-based roadmap](https://roadmap.sh/teams).
|
||||
- Become part of a supportive community by [signing up on](https://roadmap.sh/signup) [roadmap.sh](http://roadmap.sh) [platform](https://roadmap.sh/signup).
|
||||
@@ -1,384 +0,0 @@
|
||||
---
|
||||
title: 'The 5 Best Backend Development Languages to Master (@currentYear@)'
|
||||
description: 'Discover the best backend development languages to master in @currentYear@.'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/backend/languages'
|
||||
seo:
|
||||
title: 'The 5 Best Backend Development Languages to Master (@currentYear@)'
|
||||
description: 'Discover the best backend development languages to learn right now for career development, with practical tips from an experienced developer.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/backend-languages-2x930.jpg'
|
||||
relatedTitle: "Other Guides"
|
||||
relatedGuidesId: backend
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2024-01-18
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Web development is typically divided into two main categories: [backend development](https://roadmap.sh/backend) and [frontend development](https://roadmap.sh/frontend). Frontend development focuses on the visible part of the application for end-users, i.e. the part that users interact with, while backend development involves writing code that remains unseen but is essential for the functioning of all applications—the business logic.
|
||||
|
||||
Two of the key components when it comes to backend development are the programming language that you are going to code in and the database. In this article, we will be looking into a subset of programming languages that could be used for backend development. We will be discussing the pros and cons of each and the community to help you pick the best programming language for backend development.
|
||||
|
||||
Diving straight in, I will cover the top 5 backend programming languages that you should to learn if you’re looking to broaden your horizons in the server-side world.
|
||||
|
||||
## Top 5 Backend Languages to Learn for Web Development
|
||||
|
||||
The best backend languages to learn in 2025 are:
|
||||
|
||||
- Python
|
||||
- Java
|
||||
- JavaScript
|
||||
- PHP
|
||||
- Go
|
||||
|
||||
Why these languages specifically?
|
||||
|
||||
They’re some of the most known and used languages in the industry right now (see [StackOverflow’s 2023 Developer Survey](https://survey.stackoverflow.co/2023/#most-popular-technologies-language-prof)). That said, keep in mind that these are all great options, and they’re not presented here in any particular order.
|
||||
|
||||
### Python
|
||||
|
||||
[Python](https://roadmap.sh/python) has been around for decades already and while it’s never been the most popular option, it has always managed to stay within the top 5 choices. People love it for being easy to read, straightforward, and able to handle all sorts of tasks, making it a top pick for developers globally. Sure, Python's got a big name in data processing and machine learning, but let's not forget its solid impact on web development!.
|
||||
|
||||
What makes Python extra appealing, especially for beginners, is the fact that reading and writing it feels very much like English (or at least, as pseudo code). This makes it a top choice for folks just starting out in coding.
|
||||
|
||||
#### Beginner Accessibility and Learning Resources
|
||||
|
||||
One of Python's standout features is its beginner-friendly syntax, making it an ideal language for those new to programming. The emphasis on readability and the absence of complex syntax (for the most part), eases the learning curve, enabling new developers to quickly grasp fundamental concepts.
|
||||
|
||||
Python's community plays a critical role in its accessibility. Abundant learning resources, tutorials, and documentation are readily available, empowering beginners to progress from basic programming principles to advanced backend development seamlessly. Online platforms like Codecademy, Coursera, Real Python, and even Google offer comprehensive courses tailored to all skill levels.
|
||||
|
||||
#### Practical Applications and Popular Frameworks
|
||||
|
||||
Python's versatility is evident in its applicability across a spectrum of industries, from web development and data science to artificial intelligence and automation. In the context of backend development, Python shines brightly with its two standout [backend frameworks](https://roadmap.sh/backend/frameworks): [Django](https://www.djangoproject.com/) and [Flask](https://github.com/pallets/flask).
|
||||
|
||||
##### Django
|
||||
|
||||
So, let's talk about Django – it's like the superhero of web frameworks, at least in the world of Python. This high-level powerhouse is all about that "batteries-included" style, giving you a whole package of tools and features that make development lightning-fast. It follows the [Model-View-Controller](https://www.crio.do/blog/understand-mvc-architecture/) (MVC) architecture that gives your web applications a solid structure, making them scalable and easy to keep up.
|
||||
|
||||
Part of that whole “batteries-included” motto means that it comes with an admin panel, an ORM (Object-Relational Mapping) for smooth data handling, and security features that make sure your project is secured out-of-the-box. All these goodies work together, making Django a top choice for projects, whether they're a walk in the park or a brain-bending challenge.
|
||||
|
||||
##### Flask
|
||||
|
||||
On the other hand, Flask, a micro-framework, takes a minimalist approach, providing developers with the flexibility to choose components as needed. While Flask may be lighter than Django, it doesn't compromise on functionality. Its simplicity and modularity make it an excellent choice for small to medium-sized projects, allowing developers to tailor the framework to meet specific project requirements.
|
||||
|
||||
Both Django and Flask underscore Python's suitability for backend development, offering developers frameworks that cater to diverse project needs while maintaining Python's hallmark readability and efficiency.
|
||||
|
||||
#### Pros and Cons of Python
|
||||
|
||||
As with all other backend languages in this article, Python has some pros and cons you should consider before picking it as your first backend language.
|
||||
|
||||
##### Pros
|
||||
|
||||
- The syntax is very easy to learn because it’s very much like writing English.
|
||||
- The ecosystem is quite mature and has some nice frameworks that will contain all the tools you need to get started
|
||||
|
||||
##### Cons
|
||||
|
||||
- It’s not the most popular backend language, so while the frameworks available are constantly updated, they aren’t necessarily using the latest technology trends.
|
||||
- The GIL (Global Interpreter Lock) limits Python’s performance in multi-threaded applications.
|
||||
|
||||
### Java
|
||||
|
||||
[Java](https://roadmap.sh/java) has a massive presence and for good reason (according to [JetBrain’s survey in 2022, Java was used by 48% of developers](https://w3techs.com/technologies/details/pl-php)).It's the kind of programming language that's everywhere – serving up websites, running your favorite apps, and even powering big-scale enterprise systems.
|
||||
|
||||
#### Is it worth learning Java?
|
||||
|
||||
Now, learning Java, (a strongly typed, object oriented programming language (OOP)), is a journey worth taking, but it's not a walk in the park. It's a bit like climbing a mountain – you start at the bottom with the basics, and as you ascend, you get into the nitty-gritty of things like object-oriented programming. The process will force you to learn a lot, which is a great thing, by the end you’ll have a lot of understanding of mechanics and concepts around OOP that can be extrapolated into other languages. However, that can also be overwhelming to some developers who just want to learn by building mini-projects. In those situations, the learning curve of Java might be too long (not steep, but long because there is a lot more to cover than with alternatives such as Python or JavaScript).
|
||||
|
||||
That said, the community is big and there are tons of resources, from online courses to forums, helping you navigate the Java landscape. And good reason, considering Java has been around for quite a while.
|
||||
|
||||
#### Use Cases and Robust Ecosystem
|
||||
|
||||
Java's everywhere. From web development to mobile apps, and even diving into the world of big data, Java's got its fingerprints all over. And if it’s not the language itself, it’s the Java Virtual Machine (JVM) powering some other language, like Spark.
|
||||
|
||||
Java’s the language of choice for many big enterprises given its innate robustness (the first version of the language was released in 1995, it’s had quite a long time to evolve), and its robust ecosystem of libraries and frameworks makes it a go-to for developers.
|
||||
|
||||
#### Pros and Cons of Java
|
||||
|
||||
For all its power and robustness, there are some negative (and positive) aspects to picking Java as your first backend language.
|
||||
|
||||
##### Pros
|
||||
|
||||
- Java has a mature ecosystem with a varied array of libraries and frameworks for you to try. The community has been working on them and evolving them for years in many cases, so they’re quite ready to develop enterprise-ready solutions.
|
||||
- Java’s multithreading support makes it ideal for some processing-heavy tasks in the backend of big applications.
|
||||
- Java’s heavy focus on object oriented programming makes it a great option for developers who enjoy that paradigm.
|
||||
|
||||
##### Cons
|
||||
|
||||
- Java’s verbose syntax might be a problem for some people. While you can still code without an issue, it all comes down to personal preference. If you like to write less and do more with your code, Java might not be the ideal pick for you. It’s verbosity can increase development time in some situations.
|
||||
- Java applications can have higher memory consumption than others, especially compared to others like PHP. While the reason for this is their entire architecture, the fact remains.
|
||||
|
||||
### JavaScript (Node.js)
|
||||
|
||||
With Node.js in the mix, JavaScript becomes a lingua franca in web development. In other words, you can use the same language both for the frontend (client side) and for the backend (server side) of your application.
|
||||
|
||||
That said, keep in mind that depending on the framework you’re using, while it might be JavaScript on both sides, the code and logic you use can be considerably different.
|
||||
|
||||
Remember that frontend code is often confused with framework code (as in React, Angular, Vue, etc) by some developers, simply because it’s all JavaScript. But don’t be confused, the backend lacks a lot of the extra “juice” added by the browser (like the DOM API and others).
|
||||
|
||||
#### Learning Advantages of Node.js
|
||||
|
||||
If you've got the basics of JavaScript down, even if your experience has only been on the frontend, diving into Node.js is like leveling up. It lets you use the same language for both frontend and backend, which means less time juggling languages and more time building cool stuff.
|
||||
|
||||
The event-driven, non-blocking architecture is one of the main features that make the language so special – it makes your web apps fast and efficient without you having to learn more complex concepts such as multi-threading. Plus, the community is constantly growing and there are tutorials everywhere to guide you through the Node.js universe.
|
||||
|
||||
If you were to rank languages based on the amount of content out there to learn them, JavaScript would be one of the first ones (if not the first one) on the list.
|
||||
|
||||
#### Key Frameworks and Development Tools
|
||||
|
||||
Now, let's talk about frameworks. In the case of JavaScript, this topic is so varied that recommending a single option for someone just getting started is really hard.
|
||||
|
||||
For example, if you want to go frontend agnostic, or in other words, you don’t care about the technology being used to develop the client side of your app, then a good starting option would be [Express.js](https://expressjs.com/). This framework used to be the industry standard. And while that’s no longer the case, it’s still a perfect first choice if you’re looking for something with the required functionality to make your life a lot easier.
|
||||
|
||||
Now, if on the other hand, you’re looking to build the frontend and the backend at the same time, then I would recommend going with [Next.js](https://nextjs.org/) if you’re already familiar with React. Or if on the other hand, you prefer Vue.js, then definitely try [Nuxt](https://nuxt.com/). Either one of those will help you get the job done with all the bells and whistles you can think of.
|
||||
|
||||
#### Does it make sense to pick up JavaScript as a backend language?
|
||||
|
||||
The answer to this question is always going to be “yes”, whether you’re coming from the frontend and you already have JS experience or if you’re picking it up from scratch. In fact, according to [StackOverflow’s 2023 survey, JavaScript is the most used language by professionals](https://survey.stackoverflow.co/2023/#most-popular-technologies-language-prof) (with 65.85% of the votes).
|
||||
|
||||

|
||||
|
||||
If you’re coming from the client side, then adopting JS for your backend will let you start working in minutes. You’ll probably spend more time learning the backend-specific concepts than the language itself.
|
||||
|
||||
On the other hand, if you’re coming from zero, or from other programming languages, JS has some quirks, for sure, but if you go the JS route, you’re already making way for a potential switch into the frontend in the future. Who knows, maybe in a few months you’ll also want to start working on the frontend, and by having picked up JS as your main backend language, you have 90% of the work already cut for you.
|
||||
|
||||
There is really no downside to picking JS as your first backend language.
|
||||
|
||||
#### Pros and Cons of JavaScript
|
||||
|
||||
While there might not be a downside to picking JS, there is no perfect language out there, so let’s take a look at some of the pros and cons before moving on to the next one.
|
||||
|
||||
##### Pros
|
||||
|
||||
- Going with JavaScript, you’re using the same language on the backend and on the frontend. There is less cognitive load while switching environments if you’re the one coding both sides of the app.
|
||||
- The ecosystem around JavaScript is one of the richest ones you can find. The community is constantly pushing the limits of the language and coming up with new solutions to everyday problems.
|
||||
- The simple syntax allows you to reduce development time because you don’t have to write as much code to achieve good results.
|
||||
|
||||
##### Cons
|
||||
|
||||
- Asynchronous programming can be hard for some developers coming from other languages, like Python for example.
|
||||
- The lack of strong types in JavaScript can cause some problems for big codebases.
|
||||
- The single-thread nature of the language makes it really hard to implement CPU-intensive tasks. While there is support for multi-threading, it’s not extensive nor commonly used.
|
||||
- Debugging asynchronous code can be difficult for new developers given the non-linear nature of it.
|
||||
|
||||
### PHP
|
||||
|
||||
Now, if you’re looking for something very well established in the web development industry, just like Java but with a shorter learning curve, then you’re probably looking for PHP.
|
||||
|
||||
> As a note about PHP’s relevancy, while many developers might claim that PHP is a dying tech, according to [W3Techs, over 75% of websites with a backend use PHP](https://w3techs.com/technologies/details/pl-php).
|
||||
|
||||
It's the glue that holds a ton of websites together, and its longevity in the web development scene is no accident.
|
||||
|
||||
#### Ease of Mastery and Vast Library Support
|
||||
|
||||
If you're diving into PHP, you wouldn’t be so wrong (no matter what others might tell you). It's got a gentle learning curve, which means you can start building things pretty quickly. Getting everything set up and working will probably take you 10 minutes, and you’ll be writing your first “hello world” 5 minutes after that.
|
||||
|
||||
The vast community support and an ocean of online resources make mastering PHP a breeze. Plus, its library support is like having a toolkit that's always expanding – you'll find what you need, whether you're wrangling databases, handling forms, or making your website dance with dynamic content.
|
||||
|
||||
If you’re looking to pick up PHP, look for the LAMP stack, which stands for **L**inux, **A**pache, **M**ySQL, and **P**HP. With that tech stack, you’ll have everything you need to start creating websites in no time.
|
||||
|
||||
#### Modern PHP Frameworks and Their Impact
|
||||
|
||||
If we’re talking about PHP frameworks, then we gotta talk about [Laravel](https://laravel.com/) and [Symfony](https://symfony.com/). They are like the rockstars of the modern PHP world.
|
||||
|
||||
Laravel comes with a lot of tools and features that help you speed up your development process. On the other side, Symfony has a modular architecture, making it a solid choice for projects of all sizes.
|
||||
|
||||
These frameworks showcase how PHP has evolved, staying relevant and powerful in the ever-changing landscape of web development.
|
||||
|
||||
#### Pros and Cons of PHP
|
||||
|
||||
Let’s take a look at some of the most common advantages of going with PHP for the backend and some cons to discuss why it might not be the best choice for you.
|
||||
|
||||
##### Pros
|
||||
|
||||
- PHP is designed for web development, which still makes it a very popular choice for a backend language.
|
||||
- PHP’s community is quite big, considering how old the language is, so if you need help, chances are, someone has the answer you’re looking for.
|
||||
|
||||
##### Cons
|
||||
|
||||
- One of the major complaints developers have about the language is its inconsistent function naming convention. While not a huge problem, it makes it very hard for developers to intuitively find the right function by name. This causes you to constantly verify your code against the documentation to make sure you’re not making mistakes.
|
||||
|
||||
### Go
|
||||
|
||||
Now, let's close in on Go, the programming language born at Google that's all about simplicity and efficiency. Go embraces a clean and straightforward syntax. Despite its simplicity, it focuses heavily on performance, making it an excellent choice for building modern, scalable applications.
|
||||
|
||||
According to the [PYPL index](https://pypl.github.io/PYPL.html) (using Google searches to weigh interest of developers in a particular language), we can see a clear worldwide growing interest in Go from the development community:
|
||||
|
||||

|
||||
|
||||
#### Concurrency and Scalability
|
||||
|
||||
Go stands out in the crowd, especially when it comes to handling concurrency and scalability. Its built-in support for concurrent programming, through goroutines and channels, makes it a standout choice for applications that need to juggle multiple tasks simultaneously. This makes Go particularly adept at handling the demands of today's highly concurrent and distributed systems. In other words, Go is a great choice for building microservices, a type of system that is very commonly used as the backend for complex web applications.
|
||||
|
||||
So yes, very relevant.
|
||||
|
||||
#### Learning Curve and Developer Productivity
|
||||
|
||||
Learning Go is a smooth ride, thanks to its simplicity and extensive documentation. Developers often find themselves quickly transitioning from understanding the basics to building robust applications.
|
||||
|
||||
The language's focus on developer productivity is evident in its quick compilation times and the absence of excessive boilerplate code, allowing developers to concentrate on building features rather than wrestling with the language itself.
|
||||
|
||||
#### Pros and Cons of Go
|
||||
|
||||
Let’s take a look at some pros and cons for the last programming language on our list.
|
||||
|
||||
##### Pros
|
||||
|
||||
- Go code compiles quickly, which in turn leads to very fast development cycles. This is a big plus if you’re developing a big application with a large codebase because other options might slow down your process with their compilation times.
|
||||
- Go's syntax is simple enough to make it easy to learn and understand for new developers.
|
||||
|
||||
##### Cons
|
||||
|
||||
- Go’s ecosystem is quite young when compared to the other alternatives here, so the maturity of the tools available might not be the same as, for example, Java or JavaScript tooling.
|
||||
|
||||
## Choosing the Ideal Backend Language
|
||||
|
||||
So, are these the best backend programming languages out there? Is there an absolute “best” backend programming language?
|
||||
|
||||
As you’ve probably seen by now, there is no “perfect” or “ideal” backend language. When it comes to picking one out of the huge number of alternatives, you have to consider other aspects outside of the language itself:
|
||||
|
||||
- What’s the size of your project? Are you building a large-scale platform? Or just a basic static website?
|
||||
- Do you mind spending more time learning or do you need to be efficient and start coding right away?
|
||||
- Do you already have some programming knowledge and would like to pick something that resembles what you already know? Or would you like to pick up something that’s entirely different?
|
||||
- Are you alone? Or are you part of a team?
|
||||
|
||||
Once you’ve answered those questions, you’ll probably have some idea of where to go, but then you should look into the language itself, specifically into:
|
||||
|
||||
- Does it have enough learning resources for you?
|
||||
- How big and active is the community around it?
|
||||
- Are the main frameworks still under development? Or have they been parked for a while?
|
||||
|
||||
In the end, you’re evaluating the language and its ecosystem, making sure they’re both evolving right along the web industry. If you find that there are aspects that are falling behind, then it probably isn’t a good choice.
|
||||
|
||||
[](https://roadmap.sh/backend)
|
||||
|
||||
<p align="center" style="font-size: 14px; margin-top: -10px; text-align: center">Small section of the full backend roadmap available on <a href="https://roadmap.sh/backend">roadmap.sh</a></p>
|
||||
|
||||
There you’ll find community-maintained roadmaps for many career paths within software development. In particular, for this article, the [backend roadmap](https://roadmap.sh/backend) is a great place to start, because while picking a backend language is important, you’ll see there that it’s not just about the language. In fact, there is a lot of tech around the language that is also required (I’m referring to databases, git, understanding how client-server communication works, and a big “etc).
|
||||
|
||||
## What are backend languages?
|
||||
|
||||
When it comes to web development, there is a very clear distinction between frontend and backend technologies.
|
||||
|
||||
While the frontend ecosystem is quite limited to JavaScript (and other JavaScript-based languages, like TypeScript) due to Browser compatibility, the backend (A.K.A server-side) is a very different scenario.
|
||||
|
||||

|
||||
|
||||
Please note that neither of those lists is extensive, as they’re both constantly growing.
|
||||
|
||||
You can think of a backend language as one that “runs on the server side”. That said, by that definition, any language is a backend language because even JavaScript nowadays can be used on the backend as well (thanks to Node, Bun, and Deno).
|
||||
|
||||
However, we can go one step further and say:
|
||||
|
||||
> “A backend language is a server side programming language that has the tools and frameworks required to build web backends”
|
||||
|
||||
That will narrow down the list a little bit. But essentially, we can think of backend languages as anything that fits the following list:
|
||||
|
||||
- Is able to listen for incoming HTTP/S connections.
|
||||
- Can access databases.
|
||||
- Can send HTTP/S requests.
|
||||
- Can access the filesystem.
|
||||
- Has a rich ecosystem of tools and frameworks to build web applications.
|
||||
|
||||
With those features and a rich ecosystem of libraries and frameworks, a language can definitely be considered “backend-ready”.
|
||||
|
||||
## Why learn a backend programming language?
|
||||
|
||||
If you’re already a backend developer, then the main reason would be to become a more versatile developer. The more languages you know, the better code you’ll write. Either because you’ve learned different ways of solving the same problem, or simply because you’ll be able to contribute to more projects.
|
||||
|
||||
If, on the other hand, you’re just getting started, the main reason would be that you’re entering an industry that’s always looking for people.
|
||||
|
||||
## Is the market in demand for backend developers?
|
||||
|
||||
One thing to keep in mind right now is that the software development market is always in demand for devs. For example, the [U.S. Bureau of Labor Statistics gives our industry a 25% growth rate](https://www.bls.gov/ooh/computer-and-information-technology/software-developers.htm) (demand-wise) from 2022 to 2023, whereas the mean for other industries is 3%.
|
||||
|
||||
According to [JetBrains, during 2022, 75% of developers were involved with web development](https://www.jetbrains.com/lp/devecosystem-2022/) in one fashion or another, so whether you’re backend devs or frontend devs, there is always someone looking for you.
|
||||
|
||||
That said, we also have to consider that this industry is becoming a global industry. While some countries might still be fighting that process back, most developers can directly access the global market and work for any company in the world.
|
||||
|
||||
That is a great opportunity for a backend developer who lives in an area where there isn’t a big IT industry; however, it also means competing with every other developer in the world. That might cause the illusion that the IT industry is in recession or that there are no job opportunities for developers.
|
||||
|
||||
There are always opportunities; it’s just that you're now after the same job that many others from around the world are after as well.
|
||||
|
||||
That said, backend devs are always in high demand because they’re the bread and butter of any web application. They’re always required to create the underlying platform that will power most systems, so the key to standing out here is to stay up-to-date with the industry’s trends and technologies.
|
||||
|
||||
Don’t get me wrong. You can’t possibly be expected to keep up with every single programming language that is released or with all the new frameworks that are created every month. However, keeping an eye on the industry and understanding what survives long enough to become a new industry standard is important. You have to keep updating yourself and learning new technologies/skills constantly; that way, you’ll stay relevant.
|
||||
|
||||
## Is learning a backend language good for your career?
|
||||
|
||||
Whether you’re a frontend developer looking to become full-stack (someone who can code both the backend and the frontend of an application), or if you’re new to the industry and you’re thinking if this might be the best place for you, the answer is “yes”.
|
||||
|
||||
Backend developers are always in demand, so adding a new tool to your already existing toolbelt (if you’re already a dev) will only make you more flexible in the eyes of your employer.
|
||||
|
||||
But remember, a language is just a language until you give it context. If you’re wondering whether or not one of the backend languages in this article might be for you, the answer will always be “yes”. However, understand that if backend development is new to you, you will also need to pick up other skills and backend technologies around the language, such as:
|
||||
|
||||
- Understanding HTTP.
|
||||
- Learning Structured Query Language (SQL) to query your databases.
|
||||
- Understanding how APIs work.
|
||||
- What server side rendering means and how to take advantage of it.
|
||||
- What web servers are and how to use them/build them.
|
||||
|
||||
Otherwise, you’ll understand the language, but you won’t know how to use it for the role of backend development.
|
||||
|
||||
## Jumpstarting Your Backend Development Journey
|
||||
|
||||
To get started with your backend development journey, it's crucial to have a roadmap that guides you through the learning process and equips you with the skills to build robust and scalable backend systems.
|
||||
|
||||
Lucky for you, if you’re reading this, that means you’ve found the most complete and comprehensive roadmap online: [roadmap.sh](https://roadmap.sh), the current [backend roadmap](https://roadmap.sh/backend) is filled with details of everything you should and could (optionally) learn in your journey to becoming a backend developer.
|
||||
|
||||
## Guided Learning: From Online Courses to Bootcamps
|
||||
|
||||
Online courses and bootcamps serve as invaluable companions on your learning expedition. Platforms like Udemy, Coursera, and freeCodeCamp offer comprehensive backend development courses.
|
||||
|
||||
These resources not only cover programming languages like Python, Java, or JavaScript but also dive deep into frameworks like Django, Express.js, or Laravel. For those seeking a more immersive experience, coding bootcamps provide intensive, hands-on training to fast-track your backend development skills.
|
||||
|
||||
Whatever choice you go for, make sure you’re not following trends or just copying the learning methods of others. Learning is a very personal experience and what works for others might not work for you, and vice versa. So make sure to do the proper research and figure out what option works best for you.
|
||||
|
||||
## Building Community Connections for Learning Support
|
||||
|
||||
Joining developer communities (there are several on Twitter for example), forums like Stack Overflow, or participating in social media groups dedicated to backend development creates a network of support.
|
||||
|
||||
Engaging with experienced developers, sharing challenges, and seeking advice fosters a collaborative learning environment. Attend local meetups or virtual events if you can to connect with professionals in the field, gaining insights and building relationships that can prove invaluable throughout your journey.
|
||||
|
||||
## Think about you and your project
|
||||
|
||||
There are many ways to go about picking the ideal backend language for you. If there is anything you should take home with you after reading this article, it is that most languages are equivalent in the sense that you’ll be able to do pretty much everything with any of them.
|
||||
|
||||
So what criteria can you use to pick the “right one” for you?
|
||||
|
||||
The questions you should also be asking yourself are:
|
||||
|
||||
- What’s your preference for a language? Do you like Object Oriented Programming (OOP) or are you more of a functional programming type of dev? Do you like statically typed programming languages or loosely typed ones? Personal preferences should also play an important role at the time of picking your ideal programming language.
|
||||
- What does my project need? After all, project requirements sometimes dictate technology. Keep that in mind, check if the project’s needs and your personal preferences align, and try to weigh in pros and cons if they don’t.
|
||||
|
||||
In the end, personal preference and actual project requirements (if you have any) are very important, because both will influence how much you enjoy (or don’t enjoy) the learning process.
|
||||
|
||||
## Crafting a Portfolio to Display Your Backend Skills:
|
||||
|
||||
As you accumulate skills and knowledge, showcase your journey through a well-crafted portfolio. Include projects that highlight your backend skills, demonstrating your ability to - design databases, implement server-side logic, and integrate with client side technologies. Whether it's a dynamic web application, a RESTful API, or a data-driven project, your portfolio becomes a tangible representation of your backend development capabilities for potential employers or collaborators.
|
||||
|
||||
When it comes to deciding where to publish this portfolio, you have some options, such as directly on your GitHub profile (if you have one), or perhaps on your own personal website where you can share some design thoughts about each project along with the code.
|
||||
|
||||
In the end, the important thing is that you should be sharing your experience somewhere, especially when you don’t have working experience in the field.
|
||||
|
||||
## Conclusion
|
||||
|
||||
In the end, there are many backend programming languages to choose from, and what language you go for, is up to you and your particular context/needs. All I can do is guide you to the door, but you have to cross it yourself. Some interesting options are:
|
||||
|
||||
- Python with its English-like syntax.
|
||||
- Java with its formal syntax and enterprise support.
|
||||
- JavaScript with its flexibility and ability to jump between frontend and backend.
|
||||
- PHP with its proven record of success.
|
||||
- And Go, with its performance and scalability focus.
|
||||
|
||||
You’re the one who gets to decide, but just know that no matter what you choose, getting started in backend development is a one-way street. You’ll be learning from this moment on, and you’ll be jumping from one language to the other as the field evolves.
|
||||
|
||||
Remember that there is a very detailed version of a [backend roadmap here](https://roadmap.sh/backend), it might be a great place to get started! And if you’re also interested in frontend development, there is an [equally handy roadmap](https://roadmap.sh/frontend) here as well!
|
||||
@@ -1,464 +0,0 @@
|
||||
---
|
||||
title: '20 Backend Project Ideas to take you from Beginner to Pro'
|
||||
description: 'Seeking backend projects to enhance your skills? Explore our top 20 project ideas, from simple apps to complex systems. Start building today!'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/backend/project-ideas'
|
||||
seo:
|
||||
title: '20 Backend Project Ideas to take you from Beginner to Pro'
|
||||
description: 'Seeking backend projects to enhance your skills? Explore our top 20 project ideas, from simple apps to complex systems. Start building today!'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/backend-project-ideas-zxutw.jpg'
|
||||
relatedTitle: "Other Guides"
|
||||
relatedGuidesId: backend
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2024-05-09
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
As backend developers, showcasing our work to others is not straightforward, given that what we do is not very visible.
|
||||
|
||||
That said, having a project portfolio, even as backend developers, it’s very important, as it can lead to new job opportunities.
|
||||
|
||||
As an added bonus, the experience you get out of the entire process of building the apps for your portfolio will help you improve your coding skills.
|
||||
|
||||
Let’s take a look at 20 of the best backend projects you can work on to improve both your project portfolio and to learn [backend development](https://roadmap.sh/backend).
|
||||
|
||||
Keep in mind that these project ideas are organized from easiest to hardest to complete, and the entire list should take you at least a year to complete, if you’re not rushing the process.
|
||||
|
||||
So sit back, grab a cup of your favorite hot drink, and let’s get started!
|
||||
|
||||
## 1. Personal Blogging Platform API
|
||||
|
||||
**Difficulty**: Easy
|
||||
|
||||
**_Skills and technologies used_**: CRUD for main operations, databases (SQL or NoSQL), server-side RESTful API.
|
||||
|
||||

|
||||
|
||||
Let’s start with a very common one when it comes to backend projects.
|
||||
|
||||
This is a RESTful API that would power a personal blog. This implies that you’d have to create a backend API with the following responsibilities:
|
||||
|
||||
- Return a list of articles. You can add filters such as publishing date, or tags.
|
||||
- Return a single article, specified by the ID of the article.
|
||||
- Create a new article to be published.
|
||||
- Delete a single article, specified by the ID.
|
||||
- Update a single article, again, you’d specify the article using its ID.
|
||||
|
||||
And with those endpoints you’ve covered the basic CRUD operations (**C**reate, **R**ead, **U**pdate and **D**elete).
|
||||
|
||||
As a recommendation for techstack, you could use [Fastify](https://fastify.dev/) as the main [backend framework](https://roadmap.sh/backend/frameworks) if you’re going with Node, or perhaps [Django](https://www.djangoproject.com/) for Python or even [Ruby on Rails](https://rubyonrails.org/) or [Sinatra](https://sinatrarb.com/) for Ruby. As for your database, you could use [MongoDB](https://www.mongodb.com/) if you want to try NoSQL or [MySQL](https://www.mysql.com/) if you’re looking to get started with relational databases first.
|
||||
|
||||
## 2. To-Do List API
|
||||
|
||||
**_Difficulty_**: Easy
|
||||
|
||||
**_Skills and technologies used_**: REST API design, JSON, basic authentication middleware.
|
||||
|
||||

|
||||
|
||||
We’re continuing with the APIs for our backend project ideas, this time around for a To-Do application. Why is it different from the previous one?
|
||||
|
||||
While the previous project only focused on the main CRUD operations, here we’ll add some more interesting responsibilities, such as:
|
||||
|
||||
1. An authentication logic, which means you’ll have to keep a new table of users and their credentials
|
||||
2. You’ll have to create both users and tasks.
|
||||
3. You’ll also have to be able to update tasks (their status) and even delete them.
|
||||
4. Get a list of tasks, filter them by status and get the details of each one.
|
||||
|
||||
You’re free to implement this with whatever programming language and framework you want, however, you could continue using the same stack from the previous project.
|
||||
|
||||
## 3. Weather API Wrapper Service
|
||||
|
||||
**_Difficulty_**: Easy
|
||||
|
||||
**_Skills and technologies used_**: Third-party API integration, caching strategy, environment variable management.
|
||||
|
||||

|
||||
|
||||
Let’s take our API magic to the next level with this new backend project. Now instead of just relying on a database, we’re going to tackle two new topics:
|
||||
|
||||
- Using external services.
|
||||
- Adding caching through the use of a quick in-memory storage.
|
||||
|
||||
As for the actual weather API to use, you can use your favorite one, as a suggestion, here is a link to [Visual Crossing’s API](https://www.visualcrossing.com/weather-api), it’s completely FREE and easy to use.
|
||||
|
||||
Regarding the in-memory cache, a pretty common recommendation is to use [Redis](https://redis.io/), you can read more about it [here](https://redis.io/docs/manual/client-side-caching/), and as a recommendation, you could use the city code entered by the user as the key, and save there the result from calling the API.
|
||||
|
||||
At the same time, when you “set” the value in the cache, you can also give it an expiration time in seconds (using the EX flag on the [SET command](https://redis.io/commands/set/)). That way the cache (the keys) will automatically clean itself when the data is old enough (for example, giving it a 12-hours expiration time).
|
||||
|
||||
## 4. Expense Tracker API
|
||||
|
||||
**_Difficulty_**: Easy
|
||||
|
||||
**_Skills and technologies used_**: Data modeling, user authentication (JWT).
|
||||
|
||||

|
||||
|
||||
For the last of our “easy” backend projects, let’s cover one more API, an expense tracker API. This API should let you:
|
||||
|
||||
- Sign up as a new user.
|
||||
- Generate and validate JWTs for handling authentication and user session.
|
||||
- List and filter your past expenses. You can add the following filters:
|
||||
- Past week.
|
||||
- Last month.
|
||||
- Last 3 months.
|
||||
- Custom (to specify a start and end date of your choosing).
|
||||
- Add new expenses.
|
||||
- Remove existing expenses.
|
||||
- Update existing expenses.
|
||||
|
||||
Let’s now add some constraints:
|
||||
|
||||
- You’ll be using [JWT](https://itnext.io/demystifying-jwt-a-guide-for-front-end-developers-ead6574531c3) (JSON Web Token) to protect the endpoints and to identify the requester.
|
||||
- For the different expense categories, you can use the following list (feel free to decide how to implement this as part of your data model):
|
||||
- Groceries
|
||||
- Leisure
|
||||
- Electronics
|
||||
- Utilities
|
||||
- Clothing
|
||||
- Health
|
||||
- Others.
|
||||
|
||||
As a recommendation, you can use MongoDB or an ORM for this project, such as [Mongoose](https://mongoosejs.com/) (if you’re using JavaScript/Node for this).
|
||||
|
||||
From everything you’ve done so far, you should feel pretty confident next time you have to build a new API.
|
||||
|
||||
## 5. Markdown Note-taking App
|
||||
|
||||
**_Difficulty_**: Moderate
|
||||
|
||||
**_Skills and technologies used_**: Text processing, Markdown libraries, persistent storage, REST API with file upload.
|
||||
|
||||

|
||||
|
||||
You’ve been building APIs all this time, so that concept alone should not be a problem by now. However, we’re increasing the difficulty by allowing file uploads through your RESTful API. You’ll need to understand how that part works inside a RESTful environment and then figure out a strategy to store those files while avoiding name collisions.
|
||||
|
||||
You’ll also have to process the text in the following ways:
|
||||
|
||||
- You’ll provide an endpoint to check the grammar of the note.
|
||||
- You’ll also provide an endpoint to save the note that can be passed in as Markdown text.
|
||||
- Return the HTML version of the Markdown note (rendered note) through another endpoint.
|
||||
|
||||
As a recommendation, if you’re using JavaScript for this particular project, you could use a library such as [Multer](https://www.npmjs.com/package/multer), which is a Node.js module.
|
||||
|
||||
## 6. URL Shortening Service
|
||||
|
||||
**_Difficulty_**: Moderate
|
||||
|
||||
**_Skills and technologies used_**: Database indexing, HTTP redirects, RESTful endpoints
|
||||
|
||||

|
||||
|
||||
We’re now moving away from your standard APIs, and tackling URL shortening. This is a very common service, which allows you to shorten very long URLs, especially when looking to share them on social media or make them easily memorable.
|
||||
|
||||
For this project idea let’s focus on the following features, which you should be more than capable of implementing on your local environment, no matter your OS.
|
||||
|
||||
- Ability to pass a long URL as part of the request and get a shorter version of it. You’re free to decide how you’ll perform the shortening .
|
||||
- Save the shorter and longer versions of the URL in the database to be used later during redirection.
|
||||
- Configure a catch-all route on your service that gets all the traffic (no matter the URI used), finds the correct longer version and performs a redirection so the user is seamlessly redirected to the proper destination.
|
||||
|
||||
## 7. Real-time Polling App
|
||||
|
||||
**_Difficulty_**: Moderate
|
||||
|
||||
**_Skills and technologies used_**: WebSockets, live data updates, state management
|
||||
|
||||

|
||||
|
||||
Time to leave APIs alone for a while and focus on real-time interactions, another hot topic in web development. In fact, let’s try to use some sockets.
|
||||
|
||||
Sockets are a fantastic way of enabling 2-way communication between two or more parties (systems) with very few lines of code. Read more about sockets [here](https://www.digitalocean.com/community/tutorials/understanding-sockets).
|
||||
|
||||
That being said, we’re building both a client and a server for this project. The client can easily be a CLI (Command Line Interface) tool or a terminal program that will connect to the server and show the information being returned in real-time.
|
||||
|
||||
The flow for this first socket-based project is simple:
|
||||
|
||||
- The client connects to the server and sends a pre-defined request.
|
||||
- The server upon receiving this request, will send, through the same channel, an automatic response.
|
||||
|
||||
While the flow might seem very similar to how HTTP-based communication works, the implementation is going to be very different. Keep in mind that from the client perspective, the request is sent, and there is no waiting logic, instead, the client will have code that gets triggered when the message from the server is received.
|
||||
|
||||
This is a great first step towards building more complex socket-based systems.
|
||||
|
||||
## 8. Simple E-commerce API
|
||||
|
||||
**_Difficulty_**: Moderate
|
||||
|
||||
**_Skills and technologies used_**: Shopping cart logic, payment gateway integration (Stripe, PayPal), product inventory management
|
||||
|
||||

|
||||
|
||||
Back to the world of APIs, this time around we’re pushing for a logic-heavy implementation.
|
||||
|
||||
For this one, you’ll have to keep in mind everything we’ve been covering so far:
|
||||
|
||||
- JWT authentication to ensure many users can interact with it.
|
||||
- Interaction with external services. Here you’ll be integrating with payment gateways such as Stripe.
|
||||
- A complex data model that can handle products, shopping carts, and more.
|
||||
|
||||
With that in mind, let’s take a look at the responsibilities of this system:
|
||||
|
||||
- JWT creation and validation to handle authorization.
|
||||
- Ability to create new users.
|
||||
- Shopping cart management, which involves payment gateway integration as well.
|
||||
- Product listings.
|
||||
- Ability to create and edit products in the database.
|
||||
|
||||
This project might not seem like it has a lot of features, but it compensates in complexity, so don’t skip it, as it acts as a great progress check since it’s re-using almost every skill you’ve picked up so far.
|
||||
|
||||
## 9. Fitness Workout Tracker
|
||||
|
||||
**_Difficulty_**: Moderate
|
||||
|
||||
**_Skills and technologies used_**: User-specific data storage, CRUD for workout sessions, date-time manipulation.
|
||||
|
||||

|
||||
|
||||
This backend project is not just about taking in user-generated notes, but rather, about letting users create their own workout schedules with their own exercises and then go through them, checking the ones they’ve done, and the ones they haven't.
|
||||
|
||||
Making sure you also give them the space to add custom notes, with remarks about how the exercise in question felt and if they want to tweak it in the future.
|
||||
|
||||
Keep in mind the following responsibilities for this backend project:
|
||||
|
||||
- There needs to be a user sign-up and log-in flow in this backend system, as many users should be able to use it.
|
||||
- There needs to be a secure JWT flow for authentication.
|
||||
- The system should let users create workouts composed of multiple exercises.
|
||||
- For each workout, the user will be able to update it and provide comments on it.
|
||||
- The schedule the user creates needs to be associated to a specific date, and any listing of active or pending workouts needs to also be sorted by date (and time if you want to take it one step further).
|
||||
- There should also be a report of past workouts, showing the percentage of finished workouts during the queried period.
|
||||
|
||||
The data model for this one can also be complex, as you’ll have predefined exercises that need to be grouped into workout sessions, and those can then have associated comments (input from the user).
|
||||
|
||||

|
||||
|
||||
Consider the benefits of using a structured model here vs something document-based, such as MongoDB and pick the one that feels better for your implementation.
|
||||
|
||||
## 10. Recipe Sharing Platform
|
||||
|
||||
**_Difficulty_**: Moderate
|
||||
|
||||
**_Skills and technologies used_**: File uploads and image processing (like Sharp), user permissions, complex querying
|
||||
|
||||

|
||||
|
||||
While this project might feel a lot like the first one, the personal blogging platform, we’re taking the same concept, and then adding a lot more on top of it.
|
||||
|
||||
We’re building a RESTful API (or rather several) that will let you perform the following actions:
|
||||
|
||||
- Access a list of recipes. You should be able to filter by keywords (text input), publication date, by chef, and by labels. Access to this endpoint should be public.
|
||||
- The list should be paginated, and as part of the response on every page.
|
||||
- Users should be able to sign up as chefs to the system to upload their own recipes.
|
||||
- A JWT-secured login flow must be present to protect the endpoints in charge of creating new recipe posts.
|
||||
- Images uploaded as part of the recipe should be processed to be re-sized into a standard size (you pick the dimensions). You can use a library such as [Sharp](https://sharp.pixelplumbing.com/) for this.
|
||||
|
||||
## 11. Movie Reservation System
|
||||
|
||||
**_Difficulty_**: Difficult
|
||||
|
||||
**_Skills and technologies used_**: Relational data modeling (SQL), seat reservation logic, transaction management, schedule management.
|
||||
|
||||

|
||||
|
||||
There are very expensive pre-made tools that handle all this logic for companies, and the following diagram shows you a glimpse of that complexity.
|
||||
|
||||
As backend projects go, this one is a great example of the many different problems you might need to solve while working in web development.
|
||||
|
||||
A movie reservation system should allow any user to get tickets and their associated seats for any movie playing the specific day the user is looking to attend. This description alone already provides a lot of features and constraints we have to keep in mind:
|
||||
|
||||
- We’re going to have a list of movies (and maybe theaters as well).
|
||||
- Each movie will have a recurring schedule for some time and then it’ll be taken out to never return.
|
||||
- Users should be able to list movies, search for them and filter by dates, genres and even actors.
|
||||
- Once found, the user should be able to pick the seats for their particular movie of choice, and for their date of choice.
|
||||
- This leads us to you having to keep a virtual representation of your movie theater to understand seating distribution and availability.
|
||||
- In the end, the user should also be able to pay using an external payment gateway such as Stripe (we’ve already covered this step in the past).
|
||||
|
||||
## 12. Restaurant Review Platform (API) with automatic NLP analysis
|
||||
|
||||
**_Difficulty_**: Difficult
|
||||
|
||||
**_Skills and technologies used_**: RESTful API, In-memory database (for live leaderboard), SQL, Natural Language Processing to auto-label positive and negative comments.
|
||||
|
||||

|
||||
|
||||
Now this project takes a turn into the land of noSQL and AI by leading with user input. The aim of this particular backend project is to provide a very simple API that will let users:
|
||||
|
||||
- Input their own review of a restaurant (ideally, the API should request the restaurant’s ID to make sure users are reviewing the correct one).
|
||||
- Keep a leaderboard of restaurants with a generic positive or negative score, based on the type of reviews these restaurants get. For this, you can use Redis as an in-memory leaderboard to have your API query it, instead of hitting the database you’re using. This also implies that you’ll have to keep the leaderboard updated on Redis as well (as a hint: look for type [SortedSet](https://redis.io/docs/data-types/sorted-sets/) data type to understand how to do this).
|
||||
- Perform NLP (Natural Language Processing) on the user’s text portion of the review, to understand if it’s a positive one or a negative one.
|
||||
- Use the result of the NLP as a scoring system for the leaderboard.
|
||||
|
||||
As a recommendation, you might want to use Python on this project, as there tend to be more libraries around NLP for this language.
|
||||
|
||||
## 13. Multiplayer Battleship Game Server
|
||||
|
||||
**Difficulty**: Difficult
|
||||
|
||||
**_Skills and technologies used_**: Game state synchronization, low-latency networking, concurrency control.
|
||||
|
||||

|
||||
|
||||
For this project you’re not going to build a full game from scratch, so don’t worry.
|
||||
|
||||
You will however, build a game server. Your game server will have to maintain the internal state of each player’s board, and it should also enable communication between them by broadcasting their actions and results. Since we have “low-latency networking” as a constraint here, the logical implementation would be through the use of Sockets (so if you haven’t done it yet, go back to project 7 and work on it first).
|
||||
|
||||
You’re free to pick the programming language you feel more comfortable with, however, keep the mind that you’ll have to:
|
||||
|
||||
- Keep track of the player's state and game state.
|
||||
- Enable 2-way communication between players and server.
|
||||
- Allow players to join the game and set up their initial state somehow.
|
||||
|
||||
This can be a very fun project to work on, even if you’re “just” building a terminal version of this multiplayer game, as you’ll be using several of the concepts and technologies covered so far on this list.
|
||||
|
||||
## 14. Database Backup CLI utility
|
||||
|
||||
**_Difficulty_**: Difficult
|
||||
|
||||
**_Skills and technologies used_**: Advanced SQL, Database fundamentals, CLI development, Node.js (for CLI)
|
||||
|
||||

|
||||
|
||||
We’re now moving away from the API world for a while, and into the world of command line interfaces, which is another very common space for backend developers to work on.
|
||||
|
||||
This time around, the project is a CLI utility to back up an entire database.
|
||||
|
||||
So for this project, you’ll be creating a command line utility that takes the following attributes:
|
||||
|
||||
- **Host:** the host of your database (it can be localhost or anything else).
|
||||
- **Username**: the utility will need a username to login and query the database.
|
||||
- **Password**: same with the password, usually databases are protected this way.
|
||||
- **DB Name**: the name of the database to backup. We’re backing up the entire set of tables inside this database.
|
||||
- **Destination folder**: the folder where all the dump files will be stored.
|
||||
|
||||
With all that information, your utility should be able to connect to the database, pull the list of tables, and for each one understand its structure and its data. In the end, the resulting files inside the destination folder should have everything you need to restore the database on another server simply by using these files.
|
||||
|
||||
Finally, if you haven’t heard of it yet, you might want to check out the [SHOW CREATE TABLE](https://dev.mysql.com/doc/refman/8.3/en/show-create-table.html) statement.
|
||||
|
||||
## 15. Online Code Compiler API
|
||||
|
||||
**_Difficulty_**: Difficult
|
||||
|
||||
**_Skills and technologies used_**: Sandboxing code execution, integration with compilers, WebSocket communication.
|
||||
|
||||

|
||||
|
||||
For this project, you’ll be building the backend of a remote code execution application. In other words, your APIs will allow you to receive source code written using a specific language of choice (you can pick the one you want, and only allow that one), run it and then return the output of that execution.
|
||||
|
||||
Of course, doing this without any restrictions is not worth it for being in the “difficult” section of this list, so let’s kick it up a notch:
|
||||
|
||||
- The code execution should be done inside a safe sandbox, which means that the code can’t hurt or affect the system it’s running on, no matter what the code or the logic dictates.
|
||||
- On top of that, for long-running tasks, the API should also provide a status report containing the following information:
|
||||
- Time running.
|
||||
- Start time of the execution.
|
||||
- Lines of code being executed.
|
||||
|
||||
## 16. Messaging Platform Backend
|
||||
|
||||
**_Difficulty_**: Difficult
|
||||
|
||||
**_Skills and technologies used_**: Real-time messaging, end-to-end encryption, contact synchronization
|
||||
|
||||

|
||||
|
||||
Yes, we’re talking about a chat platform here. And as a backend developer you’re more than ready to implement both the server and the client application.
|
||||
|
||||
This backend project would take project #7 to the next level, by implementing the following responsibilities:
|
||||
|
||||
- Adding message encryption between client applications
|
||||
- The ability to understand who’s online
|
||||
- Understand if those users are interacting with you (a.k.a showing the “\[username\] is typing” message in real-time).
|
||||
- Sending a message from one of the clients into the server should be broadcasted to the rest of the clients connected.
|
||||
|
||||
As a recommendation for technology implementing this project, [Socket.io](http://socket.io) would be a perfect match. This means you’d be using JavaScript (node.js) for this.
|
||||
|
||||
## 17. Content Delivery Network (CDN) Simulator
|
||||
|
||||
**_Difficulty_**: Very Difficult
|
||||
|
||||
**_Skills and technologies used_**: Load balancing algorithms, caching strategies, network latency simulation
|
||||
|
||||

|
||||
|
||||
For this particular backend project, we’re not going to focus on coding, but rather on backend tools and their configuration. A [CDN](https://aws.amazon.com/what-is/cdn/) (or Content Delivery Network) is a platform that allows you to serve static content (like text files, images, audio, etc) safely and reliably.
|
||||
|
||||
Instead of having all files inside the same server, the content is replicated and distributed across a network of servers that can provide you with the files at any given point in time.
|
||||
|
||||
The point of this project is for you to figure out a way to set up your own CDN keeping in mind the following points:
|
||||
|
||||
- Use cloud servers (you can pick your favorite cloud provider for this)
|
||||
- Configure a load balancer to distribute the load between all servers.
|
||||
- Set up a caching strategy.
|
||||
|
||||
Remember that all major cloud providers have a free tier that allows you to use all their services for some time. AWS for example, allows for a full year of free tier limited to the type of resources you can use.
|
||||
|
||||
## 18. Time-tracking CLI for Freelancers
|
||||
|
||||
**_Difficulty_**: Very Difficult
|
||||
|
||||
**_Skills and technologies used_**: time tracking, interactive CLI, Day.js for time operations, reporting.
|
||||
|
||||

|
||||
|
||||
As freelancers, sometimes understanding what you’re working on, or understanding how much time you’ve spent on a particular project once it’s time to get paid, can be a challenge.
|
||||
|
||||
So, with this command line interface tool, we’ll try to solve that pain for freelancers. The tool you’re developing should let you specify that you’re starting to work on a project, and once you’re done, you should also be able to say that you’ve stopped.
|
||||
|
||||
On top of that, there should be an interactive reporting mode that should tell you the amount of time spent so far on a particular project (with the ability to filter by date and time), so you can know exactly how much to charge each client.
|
||||
|
||||
From the user’s POV, you could have commands like this:
|
||||
|
||||
- freelance start project1
|
||||
- freelance stop project2
|
||||
|
||||
And when in interactive mode, something like this should work:
|
||||
|
||||
- report project1 since 1/2/24
|
||||
|
||||
The challenge on this backend project is not just the CLI itself, which you’ve built in the past, but the actual time tracking logic that needs to happen internally. You’ll be keeping track of small chunks of time associated with different backend projects, and once the report is requested, you need to properly query your DB and get only the right chunks, so you can later add them up and return a valid number.
|
||||
|
||||
## 19. JS Obfuscator CLI utility
|
||||
|
||||
**_Difficulty_**: Very Difficult
|
||||
|
||||
**_Skills and technologies used_**: code obfuscation, batch processing of files using a CLI, Node.js.
|
||||
|
||||

|
||||
|
||||
Code obfuscation happens when you turn a perfectly readable code into something that only a machine can understand, without changing the plain text nature of the file. In other words, you just make it impossible for a human to read and understand.
|
||||
|
||||
Many tools do this in the JS ecosystem, it’s now your turn to create a new tool and perform the exact same action. As an added difficulty, you’ll be coding a tool that does this to an entire folder filled with files (not just one at the time).
|
||||
|
||||
Make sure the output for each file is placed inside the same folder, with a “.obs.js” extension, and that you’re also navigating sub-folders searching for more files.
|
||||
|
||||
Try to avoid libraries that already perform these exact same tasks, as you’ll be skipping through all the potential problems you can find, and effectively learning nothing from the experience.
|
||||
|
||||
## 20. Web Scraper CLI
|
||||
|
||||
**_Difficulty_**: Very Difficult
|
||||
|
||||
**_Skills and technologies used_**: Web scraping, headless browsing, rules engine
|
||||
|
||||

|
||||
|
||||
A web scraper is a tool that allows you to navigate a website through code, and in the process, capture information from the presented web pages.
|
||||
|
||||
As part of the last backend project of this list, you’ll be implementing your very own web scraper CLI tool. This tool will take input from the user with a list of preset commands, such as:
|
||||
|
||||
- show code: to list the HTML code of the current page.
|
||||
- navigate: to open a new URL
|
||||
- capture: this will return a subsection of the HTML of the current page using the CSS selector you specify.
|
||||
- click on: this command will trigger a click on a particular HTML element using a CSS selector provided.
|
||||
|
||||
Feel free to add extra commands to make the navigation even more interactive.
|
||||
|
||||
With the last of our backend project ideas, you’ve covered all the major areas involved in backend development and you’re more than ready to apply for a backend development job if you haven’t already.
|
||||
|
||||
If you find a piece of technology that wasn’t covered here, you’ll have the skills required to pick it up in no time.
|
||||
@@ -1,454 +0,0 @@
|
||||
---
|
||||
title: 'Top 10+ Backend Technologies to Use in @currentYear@: Expert Advice'
|
||||
description: 'Looking for the best backend technologies in @currentYear@? Check out our expert list of top tools for developers.'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/backend/technologies'
|
||||
seo:
|
||||
title: 'Top 10+ Backend Technologies to Use in @currentYear@: Expert Advice'
|
||||
description: 'Looking for the best backend technologies in @currentYear@? Check out our expert list of top tools for developers.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/backend-technologies-pnof4.jpg'
|
||||
relatedTitle: "Other Guides"
|
||||
relatedGuidesId: backend
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2024-08-27
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Backend technologies are the key to building robust and scalable applications. They power all platforms and products on the web without even being visible to the users.
|
||||
|
||||
While backend programming languages form the foundation of backend development, they aren't enough on their own. Understanding and leveraging the right backend technologies can significantly enhance your development workflow and application performance.
|
||||
|
||||
As a [backend developer](https://roadmap.sh/backend), you’ll be faced with too many options while trying to define your backend technology stack, and that can feel overwhelming.
|
||||
|
||||
So, in this article, we’re going to cover the best backend technologies in the following categories:
|
||||
|
||||
- Databases
|
||||
- Version control systems
|
||||
- Containerization and orchestration
|
||||
- Cloud platforms
|
||||
- APIs & Web Services
|
||||
- Caching systems
|
||||
- Message brokers
|
||||
- Authentication and Authorization systems
|
||||
- CI/CD
|
||||
- Monitoring & Logging
|
||||
|
||||
These should help you stay up-to-date or reach the required level to succeed as a backend developer.
|
||||
|
||||
## Databases
|
||||
|
||||

|
||||
|
||||
We can’t have a list of backend technologies to learn without covering databases. After all, databases are a core piece of the best backend technologies in use today and the backbone of any application, providing the necessary storage and retrieval of data. Choosing the right type of database depends on your application's requirements, such as data consistency, scalability, and complexity.
|
||||
|
||||
### SQL Databases
|
||||
|
||||
SQL databases (or relational databases as they’re also called) bring structure to your data and a standard querying language known as SQL.
|
||||
|
||||
#### PostgreSQL
|
||||
|
||||
PostgreSQL is an advanced open-source relational database known for its reliability and extensive feature set. It supports a wide range of data types and complex queries, making it ideal for applications that require ACID compliance and advanced data handling capabilities. PostgreSQL is commonly used in financial systems, data warehousing, and applications needing strong data integrity and complex reporting.
|
||||
|
||||
PostgreSQL also offers robust support for JSON and JSONB data types, enabling seamless integration of relational and NoSQL capabilities within a single database system. Its powerful indexing mechanisms ensure efficient query performance even with large datasets.
|
||||
|
||||
Additionally, PostgreSQL provides advanced security features like row-level security and multi-factor authentication, making it a secure choice for handling sensitive data.
|
||||
|
||||
#### MySQL
|
||||
|
||||
MySQL is a widely used open-source SQL database praised for its speed, reliability, and ease of use. It is particularly popular backend technology for web applications and online transaction processing (OLTP) due to its performance and robust community support. MySQL is often the database of choice for content management systems, e-commerce platforms, and logging applications.
|
||||
|
||||
MySQL also supports a variety of storage engines, including InnoDB, which provides ACID compliance, foreign key support, and transaction-safe operations, making it suitable for a wide range of applications.
|
||||
|
||||
Its replication capabilities, including master-slave and group replication, ensure high availability and scalability for large-scale deployments. Additionally, MySQL offers advanced security features such as data encryption, user authentication, and role-based access control, enhancing its suitability for handling sensitive data.
|
||||
|
||||
#### Microsoft SQL Server
|
||||
|
||||
SQL Server is a relational database management system from Microsoft that offers great performance, scalability, and deep integration with other Microsoft products. It provides comprehensive tools for database management, including advanced analytics and business intelligence features. SQL Server is ideal for enterprise-level applications, data warehousing, and environments where integration with Microsoft services, such as Azure, is beneficial.
|
||||
|
||||
MSSQL Server also includes robust security features, such as transparent data encryption, dynamic data masking, and advanced threat protection, making it a trusted choice for handling sensitive data. It supports a wide range of data types, including spatial and XML data, and offers powerful indexing and query optimization techniques to ensure efficient data retrieval and processing.
|
||||
|
||||
SQL Server's integration with Visual Studio and other Microsoft development tools helps to streamline the development process.
|
||||
|
||||
#### SQLite
|
||||
|
||||
SQLite is a self-contained, serverless, and zero-configuration database engine known for its simplicity and ease of use. It is lightweight and efficient, making it perfect for small to medium-sized applications, mobile apps, desktop applications, and prototyping. SQLite is embedded within the application, eliminating the need for a separate database server, which simplifies deployment and maintenance. Its single-disk file format makes it highly portable across various operating systems and platforms.
|
||||
SQLite's efficient memory and disk usage allow it to perform well even on devices with limited resources, such as IoT devices and embedded systems.
|
||||
|
||||
This makes SQLite an excellent choice for applications where simplicity, reliability, and low overhead are essential.
|
||||
|
||||
### NoSQL Databases
|
||||
|
||||
On the other hand, NoSQL databases allow for more flexibility by removing the need for a fixed schema and structure to your data. Each solution presented here covers a different type of unstructured database, and it’s up to you to decide if that focus actually makes sense for your business logic or not.
|
||||
|
||||
#### MongoDB
|
||||
|
||||
MongoDB is a document-oriented database that offers flexibility and scalability. It handles unstructured data with ease, making it ideal for applications with large-scale data and real-time analytics. MongoDB is commonly used in content management systems, e-commerce platforms, and applications that require a dynamic schema. Its ability to store data in JSON-like documents allows for easy data retrieval and manipulation.
|
||||
|
||||
#### DynamoDB
|
||||
|
||||
DynamoDB is a fully managed NoSQL database service provided by AWS. It is designed for high-performance applications requiring seamless scalability and high availability. DynamoDB is best suited for high-traffic web applications, gaming, and IoT applications. Its serverless nature means it can automatically scale up or down based on demand, ensuring consistent performance and cost-efficiency.
|
||||
|
||||
#### Cassandra
|
||||
|
||||
Cassandra is an open-source distributed NoSQL database known for its high availability and fault tolerance without compromising performance. It is ideal for large-scale applications and real-time big data analytics. Cassandra's distributed architecture makes it perfect for environments requiring continuous availability and the ability to handle large amounts of data across multiple nodes. It is commonly used in social media platforms, recommendation engines, and other data-intensive applications.
|
||||
|
||||
## Version Control Systems
|
||||
|
||||

|
||||
|
||||
Version control systems are essential for managing changes to source code over time, allowing multiple developers to collaborate effectively and maintain a history of changes.
|
||||
|
||||
### Git
|
||||
|
||||
When it comes to picking the right version control tool, Git is the most widely used one. It provides a powerful, flexible, and distributed model for tracking changes. Git’s architecture supports nonlinear development, allowing multiple branches to be created, merged, and managed independently. This makes Git essential for code collaboration and version tracking, making it a foundational tool for any developer.
|
||||
|
||||
Let’s go through some of the key benefits that make Git one of the leading backend technologies in web development.
|
||||
|
||||
#### Distributed Version Control
|
||||
|
||||
Unlike centralized version control systems (CVCS) where a single central repository holds the entire project history, Git allows each developer to have a complete copy of the repository, including its history. This decentralized approach enhances collaboration and ensures that work can continue even if the central server is down.
|
||||
|
||||
#### Branching and Merging
|
||||
|
||||
**Branching**: Git’s lightweight branching model allows developers to create, delete, and switch between branches effortlessly. This facilitates isolated development of features, bug fixes, or experiments without impacting the main codebase.
|
||||
|
||||
**Merging**: Git provides powerful merging capabilities to integrate changes from different branches. Tools like merge commits and rebasing help manage and resolve conflicts, ensuring a smooth integration process.
|
||||
|
||||
#### Performance
|
||||
|
||||
Git is designed to handle everything from small to very large projects with speed and efficiency. Its performance for both local operations (like committing and branching) and remote operations (like fetching and pushing changes) is optimized, making it suitable for high-performance needs.
|
||||
|
||||
#### Commit History and Tracking
|
||||
|
||||
Commit Granularity: Git encourages frequent commits, each with a descriptive message, making it easier to track changes, understand the project history, and identify when and why a change was made.
|
||||
|
||||
**History Viewing**: Commands like git log, git blame, and git bisect allow developers to explore the project’s history, pinpoint the introduction of bugs, and understand the evolution of the codebase.
|
||||
|
||||
#### Collaboration
|
||||
|
||||
While strictly not part of Git’s feature set, these functionalities enhance the basic set of features provided by the version control system.
|
||||
|
||||
**Pull Requests**: Platforms like GitHub, GitLab, and Bitbucket build on Git’s capabilities, offering features like pull requests to facilitate code reviews and discussions before integrating changes into the main branch.
|
||||
|
||||
**Code Reviews**: Integrating with continuous integration (CI) systems, Git platforms enable automated testing and code quality checks, ensuring that changes meet project standards before merging.
|
||||
|
||||
#### Staging Area
|
||||
|
||||
Git’s staging area (or index) provides an intermediate area where changes can be formatted and reviewed before committing. This allows for more granular control over what changes are included in a commit.
|
||||
|
||||
### GitHub
|
||||
|
||||
GitHub is a web-based platform that leverages Git for version control. It provides an extensive list of collaborative features, including (as already mentioned) pull requests, code reviews, and project management tools.
|
||||
|
||||
#### Key Features and Benefits
|
||||
|
||||
**Pull Requests and Code Reviews**: Facilitate discussions around proposed changes before integrating them into the main codebase. Developers can review code, leave comments, and suggest improvements. Built-in tools for reviewing code changes ensure collaborations are following coding standards and catch potential issues early.
|
||||
|
||||
**Project Management**: GitHub Issues allow tracking of bugs, enhancements, and tasks. Milestones help in organizing issues into targeted releases or sprints. Kanban-style boards provide a visual way to manage tasks, track progress, and organize workflows.
|
||||
|
||||
**Continuous Integration and Deployment**: Automate workflows for CI/CD, testing, deployment, and more. GitHub Actions supports custom scripts and pre-built actions to streamline DevOps processes.
|
||||
|
||||
**Community and Collaboration**: Developers can host static websites directly from a GitHub repository with Github Pages, they’re ideal for project documentation or personal websites. Integrated wikis can be used for detailed project documentation. And through forking, starring, and following repositories the platform encourages collaboration and knowledge sharing.
|
||||
|
||||
GitHub’s extensive features and strong community support make it the de facto choice for many companies and developers, both for open-source and private projects.
|
||||
|
||||
### GitLab
|
||||
|
||||
GitLab is a web-based platform for version control using Git, known for its robust CI/CD pipeline integration. It offers a comprehensive set of tools for the entire DevOps lifecycle, making it suitable for continuous integration, deployment, and monitoring.
|
||||
|
||||
#### Key Features and Benefits
|
||||
|
||||
**Integrated CI/CD**: Built-in continuous integration and continuous deployment pipelines allow backend developers to automate building, testing, and deploying code changes. With Gitlab they can even automatically configure CI/CD pipelines, deploy applications, and monitor performance, all through the same platform.
|
||||
|
||||
**Security and Compliance**: Gitlab provides key security capabilities for backend development: built-in static and dynamic application security testing (SAST/DAST).
|
||||
|
||||
**Collaboration and Communication**: Instead of Pull Requests like Github, Gitlab provides the concept of “Merge Requests”: a simplified code review process with inline comments and suggestions.
|
||||
|
||||
GitLab’s all-in-one platform makes it an excellent choice for teams looking to streamline their DevOps processes and improve collaboration and productivity.
|
||||
|
||||
### Bitbucket
|
||||
|
||||
Bitbucket is a Git-based source code repository hosting service that provides both commercial plans and free accounts for small teams. It integrates seamlessly with Atlassian products like Jira and Trello, making it a great choice for teams already using these tools.
|
||||
|
||||
**Repository Hosting**: Bitbucket supports both Git and Mercurial version control systems. And it offers unlimited private repositories for teams.
|
||||
|
||||
**Integration with Atlassian Products**: Seamlessly integrates with Jira for issue tracking and project management. It can create branches from Jira issues and view development progress which is a fantastic integration for big teams using both tools. If, on the other hand, you’re using Trello, it can connect to Trello’s boards for visual task management and tracking.
|
||||
|
||||
**Continuous Integration and Deployment**: Integrated CI/CD service for automating builds, tests, and deployments. It can be configured with a YAML file for custom workflows.
|
||||
|
||||
**Security and Permissions**: Control who accesses specific branches to enforce workflows and protect critical branches. You can even enhance security with two-factor authentication.
|
||||
|
||||
Bitbucket’s integration with Atlassian’s suite of products, along with its robust CI/CD capabilities, make it an attractive option for teams seeking a tightly integrated development and project management environment.
|
||||
|
||||
## Containerization and Orchestration
|
||||
|
||||

|
||||
|
||||
While backend developers aren’t always directly involved in the deployment process, understanding the basics of containerization and orchestration can help them work and interact with the team in charge of devops (who usually set up these CI/CD pipelines).
|
||||
|
||||
While this is not an exhaustive list of backend technologies, the two main ones to learn about are:
|
||||
|
||||
### Docker
|
||||
|
||||
Docker is a platform for developing, shipping, and running applications in containers. Containers package software and its dependencies, ensuring it runs consistently across different environments. Docker simplifies application deployment and testing, making it ideal for microservices architectures and continuous integration/continuous deployment (CI/CD) pipelines.
|
||||
|
||||
### Kubernetes
|
||||
|
||||
Kubernetes is an open-source system for automating the deployment, scaling, and management of containerized applications. It orchestrates containers across clusters of machines, providing high availability, scalability, and efficient resource utilization. Kubernetes is perfect for complex, large-scale applications requiring robust infrastructure management and automated scaling.
|
||||
|
||||
## Cloud Platforms
|
||||
|
||||

|
||||
|
||||
Cloud platforms provide a range of services and infrastructure that allow developers to deploy, manage, and scale applications without maintaining physical servers. Mind you, the “cloud” is nothing else than someone else’s servers that you don’t have to manage.
|
||||
|
||||
These platforms all offer very similar types of managed services (each with its own flavor) that allow you to set up powerful and scalable infrastructures with a few clicks.
|
||||
|
||||
### Amazon Web Services (AWS)
|
||||
|
||||
Amazon Web Services (AWS) is a very complete cloud computing platform offered by Amazon. It provides a broad range of services, including computing power, storage solutions, and databases, catering to various needs and applications.
|
||||
|
||||
#### Key Characteristics of AWS
|
||||
|
||||
**Scalability**: AWS provides scalable solutions that allow businesses to easily adjust resources based on demand.
|
||||
Global Reach: With data centers located worldwide, AWS offers high availability and low latency for global applications.
|
||||
|
||||
**Diverse Service Offerings**: AWS offers a wide range of services, including EC2 for computing, S3 for storage, and RDS for databases.
|
||||
|
||||
**Security and Compliance**: AWS provides robust security features and complies with numerous industry standards and regulations.
|
||||
|
||||
**Cost Management**: Flexible pricing models and cost management tools help businesses optimize their cloud spending.
|
||||
|
||||
### Google Cloud Platform (GCP)
|
||||
|
||||
Google Cloud Platform (GCP) is a suite of cloud computing services provided by Google. Like AWS and Microsoft Azure, GCP offers a variety of services, including computing power, storage, machine learning, and data analytics.
|
||||
|
||||
#### Key Characteristics of GCP
|
||||
|
||||
**AI and Machine Learning**: GCP excels in providing advanced AI and machine learning tools, leveraging Google's expertise.
|
||||
|
||||
**Big Data and Analytics**: GCP offers powerful analytics tools, including BigQuery, for handling large-scale data processing.
|
||||
|
||||
**Networking**: GCP provides a robust and secure global network infrastructure.
|
||||
|
||||
**Integration with Google Services**: Seamless integration with Google Workspace and other Google services enhances productivity and collaboration.
|
||||
|
||||
**Open Source Support**: GCP supports various open-source technologies, promoting flexibility and innovation.
|
||||
|
||||
### Microsoft Azure
|
||||
|
||||
Microsoft Azure is a cloud computing service created by Microsoft, offering a wide range of cloud services, including those for computing, analytics, storage, and networking.
|
||||
|
||||
#### Key Characteristics of Microsoft Azure
|
||||
|
||||
**Integration with Microsoft Products**: Azure offers seamless integration with popular Microsoft software and services.
|
||||
|
||||
**Hybrid Cloud Capabilities**: Azure supports hybrid cloud environments, enabling smooth integration between on-premises and cloud resources.
|
||||
|
||||
**Comprehensive Service Range**: Azure provides a broad spectrum of services, including Azure Virtual Machines, Azure SQL Database, and Azure DevOps.
|
||||
|
||||
**Enterprise-Grade Security**: Azure emphasizes security with advanced features and compliance with industry standards.
|
||||
|
||||
**Developer and IT Pro Tools**: Azure offers a wide range of tools for developers and IT professionals, including Visual Studio and Azure DevOps.
|
||||
|
||||
At a high level, all of these providers are very similar to each other, to the point where backend developers experienced in one of them, can extrapolate their understanding of the environment into others with minimum ramp-up time.
|
||||
|
||||
## APIs and Web Services
|
||||
|
||||

|
||||
|
||||
APIs (or Application Programming Interfaces) and web services are another mandatory incorporation to the list of top backend technologies any developer should keep in mind. They enable communication between different software systems.
|
||||
|
||||
The three most common types of APIs right now, are REST, GraphQL and gPRC, let’s take a closer look at each one of them.
|
||||
|
||||
### REST
|
||||
|
||||
REST is a standard architecture for web services, known for its simplicity and scalability. It operates on stateless principles and uses standard HTTP methods (GET, POST, PUT, DELETE) to perform CRUD (Create, Read, Update, Delete) operations. RESTful APIs are typically used to access and manipulate web resources using URLs.
|
||||
|
||||
REST is ideal for web applications and services due to its ease of implementation and broad compatibility with various web technologies. It is commonly used for developing APIs for web and mobile applications, providing endpoints that clients can interact with to perform various operations. RESTful APIs are also ideal for integrating with third-party services, enabling data exchange and interaction between different systems.
|
||||
|
||||
#### Key Characteristics of REST
|
||||
|
||||
**Statelessness**: Each request from a client contains all the information needed to process the request, without relying on stored context on the server.
|
||||
|
||||
**Uniform Interface**: REST APIs follow standard conventions, making them easy to understand and use. This includes using standard HTTP methods and status codes.
|
||||
|
||||
**Client-Server Architecture**: Separates the client and server concerns, improving scalability and flexibility. Clients handle the user interface and user experience, while servers handle data storage and business logic.
|
||||
|
||||
**Cacheability**: Responses from REST APIs can be cached to improve performance, reducing the need for repeated requests.
|
||||
|
||||
**Layered System**: REST allows for a layered system architecture, enabling intermediaries like load balancers and proxy servers to enhance security, performance, and scalability.
|
||||
|
||||
If you’d like to know more about REST, you can read the full definition directly from [its source](https://ics.uci.edu/~fielding/pubs/dissertation/rest_arch_style.htm).
|
||||
|
||||
### GraphQL
|
||||
|
||||
GraphQL is a query language for APIs and a runtime for executing those queries by using a type system you define for your data. Unlike REST, where multiple endpoints return fixed data structures, GraphQL allows clients to request exactly the data they need. This flexibility reduces the amount of data transferred over the network and can significantly improve performance.
|
||||
|
||||
GraphQL is ideal for applications with complex and dynamic data requirements.
|
||||
|
||||
#### Key Characteristics of GraphQL
|
||||
|
||||
**Declarative Data Fetching**: Clients specify the structure of the response, ensuring they receive only the data they need.
|
||||
|
||||
**Strongly Typed Schema**: The API schema is strongly typed, providing clear and detailed documentation of available data and operations.
|
||||
|
||||
**Single Endpoint**: Unlike REST, GraphQL uses a single endpoint to serve all requests, simplifying the API architecture.
|
||||
|
||||
**Real-time Data**: Supports real-time updates through subscriptions, enabling clients to receive live data changes.
|
||||
|
||||
### gRPC
|
||||
|
||||
gRPC is a high-performance, open-source RPC (Remote Procedure Call) framework developed by Google. gRPC is designed for low-latency, high-throughput communication, making it suitable for microservices architectures and real-time communication systems.
|
||||
|
||||
gRPC is ideal for applications that require efficient, reliable, and bi-directional communication.
|
||||
|
||||
#### Key Characteristics of gRPC
|
||||
|
||||
**Protocol Buffers**: Uses Protocol Buffers for compact, efficient, and platform-neutral serialization of structured data.
|
||||
|
||||
**HTTP/2**: Utilizes HTTP/2 for multiplexing, flow control, header compression, and efficient binary transport.
|
||||
|
||||
**Bi-directional Streaming**: Supports multiple types of streaming, including client-side, server-side, and bi-directional streaming.
|
||||
|
||||
**Cross-Language Compatibility**: Provides support for multiple backend programming languages, enabling interoperability between different systems.
|
||||
|
||||
## Caching Systems
|
||||
|
||||

|
||||
|
||||
Caching systems store copies of frequently accessed data to reduce latency and improve application performance. They are essential for speeding up data retrieval and reducing the load on primary data stores.
|
||||
|
||||
Implementing a successful caching strategy is not trivial, and one key aspect of it is the backend technology used for the implementation. While there might be multiple options out there, the industry currently recognizes only one de facto choice: Redis.
|
||||
|
||||
### Redis: a fast in-memory storage solution
|
||||
|
||||
Redis is an in-memory data structure store that can function as a database, cache, and message broker. It supports various data structures such as strings, hashes, lists, sets, sorted sets, bitmaps, hyperloglogs, and with the right add-ons, even vectors. Redis uses a key-value storage mechanism, which makes it simple yet powerful for a wide range of use cases.
|
||||
|
||||
Let’s quickly review some of the characteristics of Redis that make it such a fantastic option.
|
||||
|
||||
#### High Availability and Scalability
|
||||
|
||||
- **Redis Sentinel**: Provides high availability and monitoring, automatically promoting a slave to master in case of failure, ensuring minimal downtime.
|
||||
|
||||
- **Redis Cluster**: Supports automatic sharding, allowing Redis to scale horizontally. It partitions data across multiple nodes, ensuring that the system can handle large datasets and high throughput.
|
||||
|
||||
#### Performance and Use Cases
|
||||
|
||||
Redis's in-memory architecture gives it unmatched I/O speed, making it ideal for real-time applications such as:
|
||||
|
||||
- **Gaming**: Managing leaderboards, player sessions, and real-time statistics.
|
||||
- **Chat Applications**: Storing messages, user presence information, and delivering real-time notifications.
|
||||
- **Analytics**: Real-time data processing and analytics, where rapid data access and manipulation are crucial.
|
||||
- **Caching**: Reducing database load by caching frequently accessed data, improving application response times.
|
||||
|
||||
#### Persistence and Durability
|
||||
|
||||
- **RDB (Redis Database)**: Creates snapshots of the dataset at specified intervals, allowing data to be restored from the last snapshot.
|
||||
- **AOF (Append Only File)**: Logs every write operation received by the server, providing a more durable solution that can replay the log to reconstruct the dataset.
|
||||
- **Hybrid Approach**: Combining RDB and AOF to leverage the benefits of both methods, balancing performance and data durability.
|
||||
|
||||
#### Advanced Features
|
||||
|
||||
On top of all of that, Redis even provides some very powerful out-of-the-box features:
|
||||
|
||||
- **Lua Scripting**: Supports server-side scripting with Lua, enabling complex operations to be executed atomically.
|
||||
- **Pub/Sub Messaging**: Allows for message broadcasting to multiple clients, supporting real-time messaging and notifications. You can create whole event-based architectures around Redis.
|
||||
- **Modules**: Extend Redis functionality with custom modules, such as RedisGraph for graph database capabilities and RedisJSON for JSON document storage.
|
||||
|
||||
Redis's robust feature set, combined with its high performance and flexibility, makes it a versatile tool for developers looking to build scalable and responsive applications.
|
||||
|
||||
## Message Brokers and Streaming Platforms
|
||||
|
||||

|
||||
|
||||
Message brokers and streaming platforms facilitate communication between different parts of a system, enabling efficient data exchange and processing. They are crucial for building scalable and resilient applications and they are the core of reactive architectures (also known as event-based architectures).
|
||||
|
||||
### RabbitMQ
|
||||
|
||||
RabbitMQ is an open-source message broker that implements the Advanced Message Queuing Protocol (AMQP). It supports multiple messaging protocols and can be deployed in distributed and federated configurations. RabbitMQ is ideal for use cases that require reliable message delivery, complex routing, and interoperability with other messaging systems. It is commonly used in financial systems, order processing, and other applications that need robust messaging capabilities.
|
||||
|
||||
### Apache Kafka
|
||||
|
||||
Apache Kafka is a distributed streaming platform designed for high-throughput, low-latency data processing. It excels at handling real-time data feeds, making it suitable for applications that require continuous data integration and processing. Kafka’s publish-subscribe messaging system is fault-tolerant and scalable, making it ideal for big data applications, real-time analytics, event sourcing, and log aggregation. Its ability to store streams of records in a fault-tolerant manner also makes it useful for building event-driven architectures and microservices.
|
||||
|
||||
As backend developers, understanding how to take advantage of these message queues is critical to the development of scalable and resilient platforms. It is definitely a must-have skill and you need to master it.
|
||||
|
||||
## Authentication and Authorization
|
||||
|
||||

|
||||
|
||||
Authentication and authorization technologies are essential for securing applications, ensuring that users are who they claim to be and have the appropriate permissions to access resources.
|
||||
|
||||
This space is filled with solutions and methodologies, so it’s not easy to pick one option here, however, these two are very common solutions used to implement both, authZ (authorization) and authN (authentication).
|
||||
|
||||
### OAuth
|
||||
|
||||
OAuth is an open standard for access delegation commonly used to grant websites or applications limited access to a user’s information without exposing their passwords. It is widely used in single sign-on (SSO) systems, enabling users to log in to multiple applications with a single set of credentials. OAuth is ideal for third-party applications that need access to user data, such as social media integrations and API access management.
|
||||
|
||||
### JWT (JSON Web Tokens)
|
||||
|
||||
JWT is a compact, URL-safe means of representing claims to be transferred between two parties. The claims in a JWT are encoded as a JSON object, which is used as the payload of a JSON Web Signature (JWS) structure or as the plaintext of a JSON Web Encryption (JWE) structure. JWTs are commonly used for authentication and authorization in web applications, providing a secure way to transmit information between parties. They are particularly useful in stateless authentication systems, where user state is not stored on the server (like when dealing with RESTful APIs).
|
||||
|
||||
## CI/CD Pipelines
|
||||
|
||||

|
||||
|
||||
CI/CD (Continuous Integration/Continuous Deployment) pipelines automate the process of code integration, testing, and deployment, enabling faster and more reliable software delivery. This is one of the key areas backend developers need to understand to avoid creating code that simply gets in the way of the deployment process.
|
||||
|
||||
### GitHub Actions
|
||||
|
||||
GitHub Actions is an integrated CI/CD service within GitHub repositories, allowing developers to automate build, test, and deployment workflows. It supports a wide range of actions and integrations, making it highly customizable and versatile for various development workflows.
|
||||
|
||||
### CircleCI
|
||||
|
||||
CircleCI is a continuous integration and delivery platform that automates the building, testing, and deployment of applications. It supports multiple backend languages and integrates with various version control systems, making it a popular choice for diverse development environments. CircleCI is known for its speed and ease of setup, providing robust tools for optimizing and monitoring CI/CD pipelines.
|
||||
|
||||
### GitLab CI/CD
|
||||
|
||||
GitLab CI/CD is an integrated part of the GitLab platform (similar to how GitHub actions are a part of GitHub), offering continuous integration, delivery, and deployment features within the GitLab ecosystem. It allows developers to manage their entire DevOps lifecycle in a single application, from planning and coding to monitoring and security. GitLab CI/CD is particularly useful for teams seeking a seamless and comprehensive CI/CD solution.
|
||||
|
||||
### Jenkins
|
||||
|
||||
If instead of a SaaS, you’re looking for a solution that you can potentially self-host, then you might want to look into Jenkins. Jenkins is an open-source automation server that provides hundreds of plugins to support building, deploying, and automating your software development process. It is highly extensible and can be integrated with a wide array of tools and technologies. Jenkins is ideal for complex, large-scale projects requiring a customizable and powerful CI/CD environment.
|
||||
|
||||
## Monitoring and Logging
|
||||
|
||||

|
||||
|
||||
Understanding how the systems that you develop behave and perform on a daily basis is crucial to launching a successful product. Here’s where monitoring and logging come into play. Monitoring and logging are crucial pieces of backend technology used for maintaining the health, performance, and security of applications. These tools help detect issues, analyze performance, and ensure system reliability.
|
||||
|
||||
### ELK Stack (Elasticsearch, Logstash, Kibana)
|
||||
|
||||
The ELK Stack is a set of tools for searching, analyzing, and visualizing log data in real time. Elasticsearch is a search and analytics engine, Logstash is a server-side data processing pipeline, and Kibana is a visualization tool. Together, they provide a powerful platform for centralized logging and monitoring, making them ideal for applications requiring detailed log analysis and real-time insights.
|
||||
|
||||
### Grafana
|
||||
|
||||
Grafana is an open-source platform for monitoring and observability that integrates with various data sources. It provides powerful visualizations, dashboards, and alerting capabilities, making it a popular choice for monitoring infrastructure and application performance. Grafana is particularly useful for teams needing a flexible and customizable monitoring solution.
|
||||
|
||||
### Loki
|
||||
|
||||
Loki is a log aggregation system designed to work with Grafana. It is optimized for cost-effective and scalable logging, making it suitable for applications with high log volumes. Loki simplifies log management by allowing developers to query logs using the same language as Grafana, providing seamless integration for comprehensive observability.
|
||||
|
||||
### Prometheus
|
||||
|
||||
Prometheus is an open-source monitoring and alerting toolkit designed for reliability and scalability. It collects and stores metrics as time series data, providing powerful querying language and alerting capabilities. Prometheus is ideal for monitoring applications and infrastructure, particularly in cloud-native and microservices environments, where dynamic and ephemeral resources are common.
|
||||
|
||||
In the end, you might want to go with one or several of these options, the point is that you, as a developer, should be aware of them and what type of value they add to the project.
|
||||
|
||||
## Conclusion
|
||||
|
||||
As backend developers, focusing on a backend programming language and a backend framework is not going to be enough. The backend ecosystem is very rich, and there are many areas that are either directly or indirectly related to the daily tasks that a backend dev needs to work on.
|
||||
|
||||
This is why you need to stay up-to-date and look at the trends that develop within each area to make sure you’re still working with and focusing on the right solutions.
|
||||
|
||||
If you'd like more details on the type of backend development technologies you should be focusing on to excel at your role as a backend developer, check out our [Backend Developer Roadmap](https://roadmap.sh/backend).
|
||||
@@ -1,20 +0,0 @@
|
||||
---
|
||||
title: 'Basic Authentication'
|
||||
description: 'Understand what is basic authentication and how it is implemented'
|
||||
authorId: 'kamran'
|
||||
seo:
|
||||
title: 'Basic Authentication - roadmap.sh'
|
||||
description: 'Understand what is basic authentication and how it is implemented'
|
||||
isNew: false
|
||||
type: 'visual'
|
||||
date: 2021-05-19
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'visual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||
[](/guides/basic-authentication.png)
|
||||
@@ -1,103 +0,0 @@
|
||||
---
|
||||
title: 'Basics of Authentication'
|
||||
description: 'Learn the basics of Authentication and Authorization'
|
||||
authorId: 'kamran'
|
||||
seo:
|
||||
title: 'Basics of Authentication - roadmap.sh'
|
||||
description: 'Learn the basics of Authentication and Authorization'
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2022-09-21
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||
Our last video series was about data structures. We looked at the most common data structures, their use cases, pros and cons, and the different operations you could perform on each data structure.
|
||||
|
||||
Today, we are kicking off a similar series for Authentication strategies where we will discuss everything you need to know about authentication and authentication strategies.
|
||||
|
||||
In this guide today will be talking about what authentication is, and we will cover some terminology that will help us later in the series. You can watch the video below or continue reading this guide.
|
||||
|
||||
<iframe class="w-full aspect-video mb-5" src="https://www.youtube.com/embed/Mcyt9SrZT6g" title="Basics of Authentication"></iframe>
|
||||
|
||||
## What is Authentication?
|
||||
|
||||
Authentication is the process of verifying someone's identity. A real-world example of that would be when you board a plane, the airline worker checks your passport to verify your identity, so the airport worker authenticates you.
|
||||
|
||||
If we talk about computers, when you log in to any website, you usually authenticate yourself by entering your username and password, which is then checked by the website to ensure that you are who you claim to be. There are two things you should keep in mind:
|
||||
|
||||
- Authentication is not only for the persons
|
||||
- And username and password are not the only way to authenticate.
|
||||
|
||||
Some other examples are:
|
||||
|
||||
- When you open a website in the browser. If the website uses HTTP, TLS is used to authenticate the server and avoid the fake loading of websites.
|
||||
|
||||
- There might be server-to-server communication on the website. The server may need to authenticate the incoming request to avoid malicious usage.
|
||||
|
||||
## How does Authentication Work?
|
||||
|
||||
On a high level, we have the following factors used for authentication.
|
||||
|
||||
- **Username and Password**
|
||||
- **Security Codes, Pin Codes, or Security Questions** — An example would be the pin code you enter at an ATM to withdraw cash.
|
||||
- **Hard Tokens and Soft Tokens** — Hard tokens are the special hardware devices that you attach to your device to authenticate yourself. Soft tokens, unlike hard tokens, don't have any authentication-specific device; we must verify the possession of a device that was used to set up the identity. For example, you may receive an OTP to log in to your account on a website.
|
||||
- **Biometric Authentication** — In biometric authentication, we authenticate using biometrics such as iris, facial, or voice recognition.
|
||||
|
||||
We can categorize the factors above into three different types.
|
||||
|
||||
- Username / Password and Security codes rely on the person's knowledge: we can group them under the **Knowledge Factor**.
|
||||
|
||||
- In hard and soft tokens, we authenticate by checking the possession of hardware, so this would be a **Possession Factor**.
|
||||
|
||||
- And in biometrics, we test the person's inherent qualities, i.e., iris, face, or voice, so this would be a **Qualities** factor.
|
||||
|
||||
This brings us to our next topic: Multi-factor Authentication and Two-Factor Authentication.
|
||||
|
||||
## Multifactor Authentication
|
||||
|
||||
Multifactor authentication is the type of authentication in which we rely on more than one factor to authenticate a user.
|
||||
|
||||
For example, if we pick up username/password from the **knowledge factor**. And we pick soft tokens from the **possession factor**, and we say that for a user to authenticate, they must enter their credentials and an OTP, which will be sent to their mobile phone, so this would be an example of multifactor authentication.
|
||||
|
||||
In multifactor authentication, since we rely on more than one factor, this way of authentication is much more secure than single-factor authentication.
|
||||
|
||||
One important thing to note here is that the factors you pick for authentication, they must differ. So, for example, if we pick up a username/password and security question or security codes, it is still not true multifactor authentication because we still rely on the knowledge factor. The factors have to be different from each other.
|
||||
|
||||
### Two-Factor Authentication
|
||||
|
||||
Two-factor authentication is similar to multifactor authentication. The only difference is that there are precisely two factors in 2FA. In MFA, we can have 2, 3, 4, or any authentication factors; 2FA has exactly two factors. We can say that 2FA is always MFA, because there are more than one factors. MFA is not always 2FA because there may be more than two factors involved.
|
||||
|
||||
Next we have the difference between authentication and authorization. This comes up a lot in the interviews, and beginners often confuse them.
|
||||
|
||||
### What is Authentication
|
||||
|
||||
Authentication is the process of verifying the identity. For example, when you enter your credentials at a login screen, the application here identifies you through your credentials. So this is what the authentication is, the process of verifying the identity.
|
||||
|
||||
In case of an authentication failure, for example, if you enter an invalid username and password, the HTTP response code is "Unauthorized" 401.
|
||||
|
||||
### What is Authorization
|
||||
|
||||
Authorization is the process of checking permission. Once the user has logged in, i.e., the user has been authenticated, the process of reviewing the permission to see if the user can perform the relevant operation or not is called authorization.
|
||||
|
||||
And in case of authorization failure, i.e., if the user tries to perform an operation they are not allowed to perform, the HTTP response code is forbidden 403.
|
||||
|
||||
## Authentication Strategies
|
||||
|
||||
Given below is the list of common authentication strategies:
|
||||
|
||||
- Basic Authentication
|
||||
- Session Based Authentication
|
||||
- Token-Based Authentication
|
||||
- JWT Authentication
|
||||
- OAuth - Open Authorization
|
||||
- Single Sign On (SSO)
|
||||
|
||||
In this series of illustrated videos and textual guides, we will be going through each of the strategies discussing what they are, how they are implemented, the pros and cons and so on.
|
||||
|
||||
So stay tuned, and I will see you in the next one.
|
||||
@@ -1,22 +0,0 @@
|
||||
---
|
||||
title: 'Big-O Notation'
|
||||
description: 'Easy to understand explanation of Big-O notation without any fancy terms'
|
||||
authorId: 'kamran'
|
||||
seo:
|
||||
title: 'Big-O Notation - roadmap.sh'
|
||||
description: 'Easy to understand explanation of Big-O notation without any fancy terms'
|
||||
isNew: false
|
||||
type: 'visual'
|
||||
date: 2021-03-15
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'visual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||
Big-O notation is the mathematical notation that helps analyse the algorithms to get an idea about how they might perform as the input grows. The image below explains Big-O in a simple way without using any fancy terminology.
|
||||
|
||||
[](/guides/big-o-notation.png)
|
||||
@@ -1,20 +0,0 @@
|
||||
---
|
||||
title: 'Character Encodings'
|
||||
description: 'Covers the basics of character encodings and explains ASCII vs Unicode'
|
||||
authorId: 'kamran'
|
||||
seo:
|
||||
title: 'Character Encodings - roadmap.sh'
|
||||
description: 'Covers the basics of character encodings and explains ASCII vs Unicode'
|
||||
isNew: false
|
||||
type: 'visual'
|
||||
date: 2021-05-14
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'visual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||
[](/guides/character-encodings.png)
|
||||
@@ -1,22 +0,0 @@
|
||||
---
|
||||
title: 'What is CI and CD?'
|
||||
description: 'Learn the basics of CI/CD and how to implement that with GitHub Actions.'
|
||||
authorId: 'kamran'
|
||||
seo:
|
||||
title: 'What is CI and CD? - roadmap.sh'
|
||||
description: 'Learn the basics of CI/CD and how to implement that with GitHub Actions.'
|
||||
isNew: false
|
||||
type: 'visual'
|
||||
date: 2021-07-09
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'visual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||
The image below details the differences between the continuous integration and continuous delivery. Also, here is the [accompanying video on implementing that with GitHub actions](https://www.youtube.com/watch?v=nyKZTKQS_EQ).
|
||||
|
||||
[](/guides/ci-cd.png)
|
||||
@@ -1,72 +0,0 @@
|
||||
---
|
||||
title: 'Consistency Patterns'
|
||||
description: 'Everything you need to know about Week, Strong and Eventual Consistency'
|
||||
authorId: 'kamran'
|
||||
seo:
|
||||
title: 'Consistency Patterns - roadmap.sh'
|
||||
description: 'Everything you need to know about Week, Strong and Eventual Consistency'
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2023-01-18
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'visual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||
Before we talk about the Consistency Patterns, we should know what a distributed system is. Simply put, a distributed system is a system that consists of more than one components, and each component is responsible for one part of the application.
|
||||
|
||||
> A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another. The components interact with one another in order to achieve a common goal. - Wikipedia
|
||||
|
||||
## Distributed Systems
|
||||
|
||||
Imagine we have an e-commerce application where we are selling books. This application may consist of multiple different components. For example, one server might be responsible for the accounts, another might be responsible for the payments, one might be responsible for storing orders, one might be responsible for loyalty points and relevant functionalities, and another might be responsible for maintaining the books inventory and so on.
|
||||
|
||||

|
||||
|
||||
Now, if a user buys a book, there might be different services involved in placing the order; order service for storing the order, payment service for handling the payments, and inventory service for keeping the stock of that ordered book up to date. This is an example of a distributed system, an application that consists of multiple different components, each of which is responsible for a different part of the application.
|
||||
|
||||
## Why is Consistency Important?
|
||||
|
||||
When working with distributed systems, we need to think about managing the data across different servers. If we take the above example of the e-commerce application, we can see that the inventory service must have up-to-date stock information for the ordered items if the user places an order. Now, there might be two different users looking at the same book. Now imagine if one of the customers places a successful order, and before the inventory service can update the stock, the second customer also places the order for the same book. In that case, when the inventory wasn't updated, we will have the wrong stock information when the second order was placed, i.e., the ordered book may or may not be available in stock. This is where different consistency patterns come into play. They help ensure that the data is consistent across the application.
|
||||
|
||||
## Consistency Patterns
|
||||
|
||||
Consistency patterns refer to the ways in which data is stored and managed in a distributed system and how that data is made available to users and applications. There are three main types of consistency patterns:
|
||||
|
||||
- Strong consistency
|
||||
- Weak consistency
|
||||
- Eventual Consistency
|
||||
|
||||
Each of these patterns has its own advantages and disadvantages, and the choice of which pattern to use will depend on the specific requirements of the application or system.
|
||||
|
||||
### Strong Consistency
|
||||
|
||||
> After an update is made to the data, it will be immediately visible to any subsequent read operations. The data is replicated in a synchronous manner, ensuring that all copies of the data are updated at the same time.
|
||||
|
||||
In a strong consistency system, any updates to some data are immediately propagated to all locations. This ensures that all locations have the same version of the data, but it also means that the system is not highly available and has high latency.
|
||||
|
||||
An example of strong consistency is a financial system where users can transfer money between accounts. The system is designed for **high data integrity**, so the data is stored in a single location and updates to that data are immediately propagated to all other locations. This ensures that all users and applications are working with the same, accurate data. For instance, when a user initiates a transfer of funds from one account to another, the system immediately updates the balance of both accounts and all other system components are immediately aware of the change. This ensures that all users can see the updated balance of both accounts and prevents any discrepancies.
|
||||
|
||||
### Weak Consistency
|
||||
|
||||
> After an update is made to the data, it is not guaranteed that any subsequent read operation will immediately reflect the changes made. The read **may or may not** see the recent write.
|
||||
|
||||
In a weakly consistent system, updates to the data may not be immediately propagated. This can lead to inconsistencies and conflicts between different versions of the data, but it also allows for **high availability and low latency**.
|
||||
|
||||
Another example of weak consistency is a gaming platform where users can play online multiplayer games. When a user plays a game, their actions are immediately visible to other players in the same data center, but if there was a lag or temporary connection loss, the actions may not be seen by some of the users and the game will continue. This can lead to inconsistencies between different versions of the game state, but it also allows for a high level of availability and low latency.
|
||||
|
||||
### Eventual Consistency
|
||||
|
||||
> Eventual consistency is a form of Weak Consistency. After an update is made to the data, it will be eventually visible to any subsequent read operations. The data is replicated in an asynchronous manner, ensuring that all copies of the data are eventually updated.
|
||||
|
||||
In an eventually consistent system, data is typically stored in multiple locations, and updates to that data are eventually propagated to all locations. This means that the system is highly available and has low latency, but it also means that there may be inconsistencies and conflicts between different versions of the data.
|
||||
|
||||
An example of eventual consistency is a social media platform where users can post updates, comments, and messages. The platform is designed for high availability and low latency, so the data is stored in multiple data centers around the world. When a user posts an update, the update is immediately visible to other users in the same data center, but it may take some time for the update to propagate to other data centers. This means that some users may see the update while others may not, depending on which data center they are connected to. This can lead to inconsistencies between different versions of the data, but it also allows for a high level of availability and low latency.
|
||||
|
||||
## Conclusion
|
||||
|
||||
In conclusion, consistency patterns play a crucial role in distributed systems, and the choice of which pattern to use will depend on the specific requirements of the application or system. Each pattern has its own advantages and disadvantages, and each is more suitable for different use cases. Weak consistency is suitable for systems that require high availability and low latency, strong consistency is suitable for systems that require high data integrity, and eventual consistency is suitable for systems that require both high availability and high data integrity.
|
||||
@@ -1,147 +0,0 @@
|
||||
---
|
||||
title: 'Data Analyst Career Path: My Pro Advice'
|
||||
description: 'Wondering where a data analyst role can take you? Learn what your data analyst career path could look like.'
|
||||
authorId: fernando
|
||||
excludedBySlug: '/data-analyst/career-path'
|
||||
seo:
|
||||
title: 'Data Analyst Career Path: My Pro Advice'
|
||||
description: 'Wondering where a data analyst role can take you? Learn what your data analyst career path could look like.'
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/data-analyst-career-path-heu4b.jpg'
|
||||
isNew: false
|
||||
type: 'textual'
|
||||
date: 2025-05-15
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
# Data Analyst Career Path: My Pro Advice
|
||||
|
||||
Data analysts sit at the heart of decision‑making in virtually every industry today. From uncovering customer behavior patterns in retail to optimizing operations in healthcare, the ability to collect, clean, and interpret data has become a critical superpower.
|
||||
|
||||
To help you map out your future data analyst career path, in this guide I'll mix in two cornerstone resources from roadmap.sh: the very detailed [Data Analyst Roadmap](https://roadmap.sh/data-analyst), which lays out the skills and milestones you'll need from beginner to pro, and the hands‑on [SQL Course](https://roadmap.sh/courses/sql), designed to build your foundation in one of the most common languages when it comes to data operations. Together, these tools will serve as your compass and toolkit, ensuring you have a clear path forward and the practical know‑how to tackle real‑world challenges.
|
||||
|
||||
## Options for a Data Analyst Career Path
|
||||
|
||||

|
||||
|
||||
Knowing where to go and how to grow in data analysis is not trivial, simply because there are too many very valid and interesting options for data analysts.
|
||||
|
||||
To narrow the list of options, we can think of three core trajectories, each with its own set of responsibilities, key skills, and growth opportunities:
|
||||
|
||||
### Junior Data Analyst → Senior Data Analyst → Analytics Manager
|
||||
|
||||
| Level | Focus | Key skills | Goal |
|
||||
| :---- | :---- | :---- | :---- |
|
||||
| **Entry-level (i.e junior analyst)** | Clean & transform data using SQL or MS Excel | Basic data modeling, reporting, req. gathering. | Provide actionable insights. |
|
||||
| **Mid-level** | Complex analysis, advanced statistical analysis, and project ownership. | Python/R, creating ETLs, mentoring | Shaping data strategy, collaborating with business or operations, and influencing decision-making |
|
||||
| **Leadership** | Defining implementation roadmaps | Leadership, stakeholder management, expectation management with clients. | Lead key meetings with clients, become VP of analytics, or similar role. |
|
||||
|
||||
### Data Analytics Consultant / BI Analyst
|
||||
|
||||
| Level | Focus | Key Skills | Goal |
|
||||
| :---- | :---- | :---- | :---- |
|
||||
| **Data Analytics Consultant** | Acting as a strategic advisor, you help organizations define their data strategy and translate business requirements. | Data Strategy & Governance, Client Engagement, deep SQL. | Delivering a scalable analytics roadmap, implementing dashboards, and earning trust as a go‑to advisor. |
|
||||
| **BI Analyst** | Embedding within a single organization or business unit to build and maintain self‑service reporting environments. | ETL, dashboard development. | Influence data strategy, mentor JR Data Scientists. |
|
||||
|
||||
### Specialized Data Scientist Tracks → Chief Data Officer
|
||||
|
||||
| Level | Focus | Key Skills | Goal |
|
||||
| :---- | :---- | :---- | :---- |
|
||||
| **Data science option** | Go from descriptive analytics to machine learning algorithms. | Advanced Python, Statistical Analysis, Data modeling. | Deliver a working predictive solution |
|
||||
| **Advanced Statistics** | Tackle large‑scale analytical problems | Expertise in advanced statistical programming, big Data, and a bit of storytelling | Influence data strategy, mentor JR Data Scientists |
|
||||
| **CDO** | Oversee data governance, compliance, and ensure that analytics and machine learning initiatives align with strategic objectives. | Strategic leadership, understanding of data privacy, data governance. | Implement robust data governance & privacy frameworks, deliver analytics roadmap. |
|
||||
|
||||
### What should you pick?
|
||||
|
||||
In the end, either through any of these variations of the data analyst career path, there isn't a single option that is clearly better than the others.
|
||||
|
||||
* If you love turning raw numbers into charts and dashboards, the **junior→senior analyst** route offers steady, skill‑based progression.
|
||||
|
||||
* If you thrive on variety and advising multiple teams, consider the **analytics consultant/BI analyst** track.
|
||||
|
||||
* If you're drawn to algorithms and predictive work, the **data science** trajectory can propel you toward senior data scientist roles and, ultimately, a chief data officer position.
|
||||
|
||||
## Is Data Analysis Right for You?
|
||||
|
||||
Figuring out if the data analyst career path is the right place for you is not an easy task; in fact, many will need to go through the process of working in the field to retroactively answer the question.
|
||||
|
||||
But to give you a basic guide and help you understand whether you'd enjoy the position or not, you have to consider that pursuing a data analytics career begins with an honest curiosity about how raw data translates into actionable insights. Data analysis isn't just number crunching; it's about asking the right questions, designing robust statistical tests, and building data models that answer real business problems.
|
||||
|
||||
## Learning Path & Essential Skills
|
||||
|
||||
Charting your learning path starts with a clear learning roadmap, and there's no better place to begin than the [Data Analyst Roadmap](https://roadmap.sh/data-analyst).
|
||||
|
||||

|
||||
|
||||
Following its structured progression ensures you're building the right technical skill set in the right order.
|
||||
|
||||
As part of the roadmap, you'll have to tackle different languages such as SQL, R, Python, and others. To learn more about it, you can try this hands-on [SQL Course](https://roadmap.sh/courses/sql) that walks you through writing efficient queries, designing relational schemas, and performing complex joins and aggregations.
|
||||
|
||||
You'll also need **data visualization tools** and the storytelling mindset that makes your analyses resonate.
|
||||
|
||||
Finally, you'll start noticing that soft skills are particularly needed as a data analyst. For example, clear communication, problem solving, and a collaborative spirit are non‑negotiable when gathering requirements, iterating on dashboards, or presenting to senior management.
|
||||
|
||||
## 3 Portfolio Project Ideas
|
||||
|
||||
Below are three end‑to‑end projects designed to showcase the abilities that hiring managers look for in data analyst candidates. Each idea maps to stages on the [Data Analyst Roadmap](https://roadmap.sh/data-analyst) and gives you a chance to apply SQL, Python/R, and visualization tools to real‑world questions.
|
||||
|
||||
### Interactive Sales Dashboard
|
||||
|
||||
**Objective:** In this project, you can build a live dashboard that empowers marketing and senior management to spot seasonal patterns, best‑selling products, and under‑performing regions.
|
||||
|
||||
**Data & tools:** For this project, you can source a public retail or e-commerce dataset (such as Kaggle "Online Retail II"). You can use Python and SQL, the rest is up to you to decide how to show the results.
|
||||
|
||||
**Key skills demonstrated:** In this project, you're covering a bit of Data Modeling, ETL pipelines, and mostly Data Visualization tools.
|
||||
|
||||
### Customer Churn Prediction Model
|
||||
|
||||
**Objective:** For this one, you'll show how statistical analysis and basic machine learning can predict which customers are most likely to churn, enabling proactive retention strategies.
|
||||
|
||||
**Data & Tools:** For this one, you can find some sort of telecom dataset (like IBM Telco Customer Churn), use Python and SQL again to do some exploratory analysis, and finally train a classification model using scikit-learn.
|
||||
|
||||
**Key skills demonstrated:** During this project, you'll work on statistical analysis, data mining, and, as usual, some actionable insights turned into storytelling.
|
||||
|
||||
### A/B Testing Analysis for Website Redesign
|
||||
|
||||
**Objective**: Conduct and interpret an A/B test to determine which landing‑page design maximizes conversion, showcasing your ability to drive business analytics projects from hypothesis to recommendation.
|
||||
|
||||
**Data & Tools**: You can get some synthetic data for this one using something like ChatGPT, as long as it simulates A/B test data. Then, using either SQL or even MS Excel, you can do some aggregations and finally do the last calculations with Python or R. Try to plot the results on something like PowerBI at the end.
|
||||
|
||||
**Key skills demonstrated**: For this project, you'll be doing some experimental design, some business intelligence, and of course, decision making by translating statistical outcomes into a go/no‑go recommendation, acting as a market research analyst.
|
||||
|
||||

|
||||
|
||||
## My tips from personal experience
|
||||
|
||||
With all of this out of the way, let me quickly run you through some of my personal tips when it comes to growing and moving forward as a data analyst.
|
||||
|
||||
1. **Build a strong network and find mentors:** Connect with other data analysts, data scientists, and analytics managers through LinkedIn groups, local meetups, or virtual conferences. Ask others who have gone through the same about their journey, about the problems they found along the way. Learn from them.
|
||||
2. **Showcase your work with purpose:** Your first data analyst job will depend on having a solid portfolio (since you don't have any actual experience). Try to host your projects on GitHub or a personal blog, and include clear READMEs that explain your data strategy, the tech stack you used, and the business impact (showing you understand the value of your work), whether it's "increased conversion rate by X%" or "optimized inventory planning".
|
||||
3. **Stay ahead with the latest tools and techniques:** Data visualization tools and programming languages are constantly evolving. One key language you'll be using quite regularly is SQL, and if you ignore it, your progress will slow down. Find yourself a [SQL Course](https://roadmap.sh/courses/sql) that works for you and ensure you master it as soon as possible.
|
||||
4. **Embrace feedback and cultivate a growth mindset:** Whether you're presenting to marketing teams or senior management, feedback is your friend. After each project or presentation, or even on a regular basis try to get constructive feedback on your data modeling, storytelling, and communication style. Use this input to refine your processes, improving both your essential skills and your ability to communicate insights.
|
||||
5. **Plan for credentials that matter:** Getting credentials that validate your expertise with a certain tool or a type of analysis is going to help you stand out in the sea of analysts fighting for the same position. So, consider pursuing data analytics certifications (e.g., Google Data Analytics or Microsoft Power BI). They will not ensure you get the job, but they'll help you demonstrate a certain level of expertise at first glance.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Congrats, you now have a clear playbook for launching and advancing your data analyst career:
|
||||
|
||||
1. **Choose your path.** Understand exactly what you enjoy the most, and find the best career path for you.
|
||||
|
||||
2. **Assess your fit**. Understand the role you want, and make sure you'll enjoy the day-to-day of it.
|
||||
|
||||
3. **Build your skills**. Follow the [Data Analyst Roadmap](https://roadmap.sh/data-analyst) to structure your learning, and dive into the [SQL Course](https://roadmap.sh/courses/sql) to master the foundation of every data role.
|
||||
|
||||
4. **Practice with real projects**. Even if it's with fake, test or even raw data, tackle real-world problems to show you're able to transmit insights in the right way.
|
||||
|
||||
5. **Finally,** remember to network with other analysts, seek feedback, stay current on tools and techniques, and earn targeted certifications when you're ready to stand out.
|
||||
|
||||
Your journey into becoming a successful data analyst begins today: pick one section of the roadmap, schedule time to complete the SQL course module, and start your first portfolio project.
|
||||
|
||||
Go!
|
||||
@@ -1,218 +0,0 @@
|
||||
---
|
||||
title: "How to Become a Data Analyst with No Experience: My Advice"
|
||||
description: "Learn how to become a data analyst with no experience through smart steps, skill-building tips, and my real-world guidance."
|
||||
authorId: fernando
|
||||
excludedBySlug: '/data-analyst/how-to-become'
|
||||
seo:
|
||||
title: "How to Become a Data Analyst with No Experience: My Advice"
|
||||
description: "Learn how to become a data analyst with no experience through smart steps, skill-building tips, and my real-world guidance."
|
||||
ogImageUrl: 'https://assets.roadmap.sh/guest/become-a-data-analyst-with-no-experience-khk03.jpg'
|
||||
isNew: true
|
||||
relatedTitle: "Other Guides"
|
||||
relatedGuidesId: data-analyst
|
||||
type: 'textual'
|
||||
date: 2025-05-14
|
||||
sitemap:
|
||||
priority: 0.7
|
||||
changefreq: 'weekly'
|
||||
tags:
|
||||
- 'guide'
|
||||
- 'textual-guide'
|
||||
- 'guide-sitemap'
|
||||
---
|
||||
|
||||

|
||||
|
||||
Breaking into the data analytics industry can be scary, especially when you have no prior background in data analysis.
|
||||
|
||||
Yet the need for entry-level data analysts has never been higher, data is at the heart of everything, and organizations across the globe depend on data-driven insights to inform strategic decisions in every area of the enterprise.
|
||||
|
||||
Many aspiring data professionals incorrectly believe that a degree in computer science or a long resume in data science is a prerequisite for anything. The truth is that mastering the **data analysis process**, building a solid **analytics portfolio**, and showcasing your **data skills** can open doors to your first **junior data analyst** role, just like a long resume or a fancy degree.
|
||||
|
||||
In this practical guide on how to become a data analyst with no experience, I'm going to show you the key skills you should focus your learning path on (like SQL and statistical analysis).
|
||||
|
||||
I'll also prepare you on how to hone critical soft skills and leverage expert resources such as the [Data Analyst Roadmap](https://roadmap.sh/data-analyst) and this [SQL course](https://roadmap.sh/courses/sql) to help you improve your skills in that language.
|
||||
|
||||
## Step 1: Master the Essential Data Analyst Skills
|
||||
|
||||
In the analysis life cycle (from data collection and unprocessed data wrangling to statistical modeling and presentation), some **techniques** and **skills (both technical and non-technical)** are non-negotiable. The first thing you have to do is to focus on these core areas to build a solid foundation for your first **entry-level data analyst** or **junior data analyst** role:
|
||||
|
||||
### Technical Skills:
|
||||
|
||||
A data analyst's toolkit revolves around five foundational technical domains, each critical to unlocking insights from raw data and driving informed decisions. Begin by mastering **Structured Query Language (SQL)**, the backbone of relational data interrogation. With our [**SQL course on roadmap.sh**](https://roadmap.sh/courses/sql), you will learn to write complex queries—filtering, joining, aggregations, and advanced window functions—that enable you to extract and **manipulate data** at scale.
|
||||
|
||||
Next, tackle Data cleansing and Manipulation, the art of transforming messy inputs into reliable analytical datasets. Utilizing libraries such as pandas in Python or dplyr in R, you will develop workflows for handling missing values, normalizing formats, and removing duplicates, thereby ensuring high **data quality** before any modeling or visualization begins.
|
||||
|
||||
With a pristine dataset in hand, dive into different Analysis techniques to derive meaningful patterns. Key concepts such as descriptive statistics, hypothesis testing, correlations, and regression form the core of **these analysis techniques** used to validate assumptions and generate **actionable insights**. Proficiency in these methods equips you to support business cases with evidence-backed conclusions.
|
||||
|
||||
Translating numerical results into compelling narratives requires strong **Data Visualization** skills. Whether you choose Tableau, Power BI, or Python's matplotlib and seaborn libraries, you will create interactive dashboards and visual stories that highlight trends, outliers, and opportunities. Effective visualization not only conveys findings clearly but also drives stakeholder engagement.
|
||||
|
||||
Finally, solid programming skills in Python or R tie your analytical process together. From automating repetitive tasks and integrating APIs to building end-to-end **data analytics** pipelines, a programming mindset enables scalability, reproducibility, and integration of advanced tools, positioning you for roles across the industry.
|
||||
|
||||
### Soft Skills:
|
||||
|
||||
In the realm of data analytics, technical prowess must be complemented by strong interpersonal abilities (i.e, soft skills). Analytical thinking and structured problem-solving are at the heart of your daily workflow. When you encounter complex datasets, you must decide which analysis techniques best uncover the story hidden in the numbers.
|
||||
|
||||
This thoughtful approach ensures you derive accurate, actionable insights from unprocessed data.
|
||||
|
||||
Equally vital is the capacity to interpret data and translate it into meaningful recommendations. Effective communication means crafting a narrative around your findings that resonates with diverse audiences, from C-suite executives to frontline team members.
|
||||
|
||||
By designing clear visualizations and presenting data insights through compelling dashboards or concise slide decks, you empower stakeholders to make informed decisions.
|
||||
|
||||
Documenting every phase of your analysis process (data collection, cleaning, transformation, modeling, and reporting) creates a transparent audit trail. This meticulous record-keeping not only bolsters confidence in your results but also sets the foundation for reproducibility and continuous improvement.
|
||||
|
||||
Collaboration and adaptability define success in dynamic business environments. As a business intelligence analyst, sales data analyst, or healthcare data analyst, you'll partner with professionals across marketing, finance, operations, and IT.
|
||||
|
||||
Learning to navigate different communication styles, incorporating feedback, and swiftly adopting new tools or programming skills are essential to deliver timely, value-driven analyses.
|
||||
|
||||
Finally, incorporate a growth mindset by viewing every project as an opportunity to refine your soft skills. Seek constructive feedback from mentors and peers, participate in cross-functional workshops, and mentor aspiring professionals. Cultivating empathy, resilience, and lifelong learning habits ensures you evolve into a well-rounded data analyst capable of driving organizational success.
|
||||
|
||||
Starting with these essential skills will give you the confidence to tackle **data-projects**, close the **data skills gap**, and stand out among **aspiring analysts** in a competitive **job market.** After the foundation is done, you're free to specialize and focus in the areas that you feel are more appealing to you.
|
||||
|
||||
## Step 2: Follow a Structured Learning Path
|
||||
|
||||
Getting started on your journey as a new data analyst without formal experience can feel a bit overwhelming, so it's very important to follow a **structured learning path**. This way, you'll ensure you acquire the right **data analysis skills** in a way that makes sense according to your progression during your journey.
|
||||
|
||||
Here's how to follow a proven roadmap:
|
||||
|
||||
1. **Explore the [Data Analyst Roadmap](https://roadmap.sh/data-analyst)**: Start with the roadmap to grasp the full analysis life cycle.
|
||||
2. **Master SQL Early**: As a key technology for the field, the sooner you start tackling SQL, the better it will be. So, enroll in a [SQL course](https://roadmap.sh/courses/sql) to build a strong foundation in SQL (Structured Query Language). Practice querying, filtering, aggregations, and manipulation on realistic datasets.
|
||||
3. **Earn Recognized Certifications**: Boost your resume with entry-level certifications that validate your expertise. Consider doing any of the following:
|
||||
* **Google Data Analytics Professional Certificate** (Coursera)
|
||||
* **IBM Data Analyst Professional Certificate**
|
||||
* **Microsoft Certified: Data Analyst Associate**. These programs cover essential **data science** concepts, **data cleansing**, **visualization**, and real-world **data projects**.
|
||||
4. **Take Complementary Courses**: Figure out what your **data analysis skills gaps** are and fill them up by learning:
|
||||
* **Programming languages** (Python, R)
|
||||
* **Statistical analysis** and hypothesis testing
|
||||
* **Business intelligence** tools (Tableau, Power BI). Platforms like DataCamp, Udacity, and LinkedIn Learning offer targeted modules.
|
||||
5. **Apply Knowledge Through Projects**: Especially at the beginning, when you don't have any experience, try to reinforce your learning by tackling guided analysis projects on platforms like [Kaggle](https://www.kaggle.com/) or GitHub. Focus on end-to-end workflows (data collection, data cleaning, analyzing data, visualizing data, and presenting insights).
|
||||
|
||||
This structured learning path will help you in several ways:
|
||||
|
||||
* You'll be able to systematically build basic data analysis skills.
|
||||
* You'll end up developing a compelling and very complete portfolio showcasing your skills.
|
||||
* And you'll also be able to demonstrate to potential hiring managers your commitment to becoming a great junior data analyst.
|
||||
|
||||
## Step 3: Build a Data Analytics Portfolio
|
||||
|
||||
Building a robust data analyst portfolio will help you demonstrate your ability to tackle end-to-end **projects**, making you a standout candidate in a competitive **job market**. Here's why it matters and how to craft compelling portfolio pieces:
|
||||
|
||||
### Why a Strong Portfolio Matters
|
||||
|
||||
Building a strong portfolio helps you validate your own **analysis process**, from **data collection** and cleaning to visualization and interpretation, you'll be working on the entire thing.
|
||||
|
||||
It also helps you showcase your proficiency in **data manipulation & cleaning**, and extracting **actionable insights** from unprocessed data.
|
||||
|
||||
As part of the analysis life cycle, your **data visualization** and storytelling skills will have to shine in your portfolio. They're critical for roles like **BI analyst** or **data analyst**, so make sure you use them on every project in your portfolio.
|
||||
|
||||
Overall, the portfolio will help you highlight every single skill that is needed for the job, and if you build one with varied projects, different types of visualizations, and business goals, by the end, you'll be broadcasting to every hiring manager that you know what you're doing.
|
||||
|
||||
### Portfolio Project Ideas
|
||||
|
||||
But what project can you put into your portfolio? Let's go over some ideas that might highlight just the right set of skills:
|
||||
|
||||
* **Public Dataset Analysis**: Pick datasets (e.g., healthcare metrics, sales transactions, fraud detection) and perform a full workflow—ingestion, cleaning, exploratory analysis, statistical modeling, and reporting.
|
||||
* **Data Cleaning & QA Showcase**: Use a messy real-world dataset to demonstrate handling missing values, outliers, normalization, and quality checks—include before/after snapshots and code snippets.
|
||||
* **Interactive Dashboards**: Build dashboards with Tableau, Power BI, or Plotly to **visualize data** trends and present insights; add filters, annotations, and user controls.
|
||||
* **Domain-Specific Projects**: Create analyses for niche roles—e.g., evaluate patient outcomes as a **healthcare data analyst**.
|
||||
* **Data Storytelling**: Craft a narrative-driven project (e.g., COVID-19 trends, climate data) combining charts, maps, and written insights to tell a compelling story.
|
||||
|
||||
And if you don't really know how to begin working on them, you can simply ask one of the many LLMs available online to give you a detailed project plan, and start working on it. You'll be closing projects right and left in no time.
|
||||
|
||||
### Best Practices
|
||||
|
||||
Where should you create your portfolio? What tech stack should you use? How often should you update it? When should you publish it?
|
||||
These are all valid questions that don't have a single answer, however, I can show you some of the best practices I've seen around throughout my career when it comes to building data analyst portfolios:
|
||||
|
||||
* Host projects on GitHub with clear READMEs, organized code, and visual previews.
|
||||
* Document your **analysis life cycle** in Jupyter notebooks or blog posts, explaining each step and decision.
|
||||
* Use authentic tools and workflows: query public APIs with **SQL**, automate tasks with Python or R, and integrate BI tools.
|
||||
* Continuously update your portfolio as you learn new **data analysis techniques** and **programming skills**.
|
||||
|
||||
## Step 4: Gain Practical Experience
|
||||
|
||||
Securing practical experience allows you to apply theoretical knowledge, bridge the skills gap, and prove to hiring managers that you can deliver on real-world data analysis projects. Here are several pathways to get your foot in the door:
|
||||
|
||||
* **Internships & Volunteer Projects:**
|
||||
Look for data internships (even unpaid if you can) or volunteer to help non‑profits, student organizations, or local businesses with their **data collection**, **data cleaning**, and **data visualization** needs. These roles not only strengthen your **technical skills** but also give you concrete examples for your **data analytics portfolio**.
|
||||
* **Freelance & Gig Work:**
|
||||
Platforms like Upwork, Fiverr, or even LinkedIn can connect you with short‑term gigs, everything from database queries to dashboard creation. Freelance tasks force you to **manipulate data**, produce **actionable insights**, and **present data-driven insights** under real-world deadlines, building both technical chops and business communication skills.
|
||||
* **Entry‑Level & Support Roles:**
|
||||
Apply for roles labeled **data technician**, **data entry**, or **junior data analyst**. These positions often focus on **data quality**, routine reports, and simple analyses; they're perfect stepping stones that let you collaborate with senior analysts and refine your **analysis** and **manipulation** techniques.
|
||||
* **Kaggle Competitions & Public Challenges:**
|
||||
I've mentioned this platform before, but consider participating in Kaggle or similar platforms to demonstrate your ability to tackle problems like a **fraud detection** challenge or sales forecasting. Even if you don't win, documenting your approach, code, and learnings shows resilience and a methodical **analysis process**.
|
||||
* **Capstone & Guided Projects:**
|
||||
Many certification programs include capstone projects. Treat these as mini‑portfolio pieces: choose datasets relevant to your target roles, and clearly outline your **data analysis life cycle**, from **raw data** ingestion through **data visualization** and storytelling.
|
||||
|
||||
Build experience in as many diverse **practical experiences as you can**. That way, you'll not only close any **data skills gap** you might have, but also amass a collection of tangible accomplishments, making it far easier to articulate your value as an **aspiring data analyst** during interviews.
|
||||
|
||||
## Step 5: Network and Engage with the Data Community
|
||||
|
||||
Spending time in the right communities accelerates your growth as an **aspiring data analyst** by helping you stay current with industry trends, learn from seasoned **professionals**, and uncover hidden **data analytics job** opportunities. After all, a big part of growing in any technology role is about networking (shocking, I know\!) with other professionals who've gone through what you're going through now and can provide advice, help, or even a boost when least expected.
|
||||
|
||||
Networking is not easy, and there are many ways to do it. Here's just one example of how to build and leverage your own network:
|
||||
|
||||
* **Leverage Professional Platforms:** Connect with **qualified data analysts** and **data scientists** on LinkedIn, GitHub, and specialized forums like Stack Overflow or Reddit's r/datascience. Engage by asking thoughtful questions, sharing your **data analysis projects**, and commenting on discussions.
|
||||
* **Attend Industry Events:** Participate in local meetups, virtual conferences, webinars, and workshops hosted by organizations such as Data Science Saudi, Meetup groups, or platform-specific events (e.g., Tableau User Groups). These gatherings expose you to emerging **analysis techniques**, **data visualization** best practices, and evolving industry standards.
|
||||
* **Join Online Communities:** Become active in Slack channels, Discord servers, or professional associations where **data analysts** share resources, job leads, and **actionable insights**. Regularly review community channels for project feedback, collaboration opportunities, and announcements about **entry-level data analyst** roles.
|
||||
* **Find a Mentor or Buddy:** Seek out mentorship programs through bootcamps or university-alumni networks. A mentor, someone like a **senior data analyst** or BI (**business intelligence) analyst**, can provide personalized advice on your **data analysis life cycle**, resume reviews, and mock interviews.
|
||||
* **Share Your Knowledge:** Contribute to blogs, record tutorials, or present lightning talks at virtual events. While you might just be starting, chances are someone else is going through the same process, and learning how you solved it can help them. Also, creating content like this will force you to truly understand the topic you're covering before being able to explain it. So even while you're teaching others, you're also cementing that understanding within you.
|
||||
|
||||
Networking is not easy, and when you're just getting started, it might seem even harder than getting an actual data analyst job. The above list is just a set of options, you don't have to go through all of them (or any, to be honest), just find a way that works for you and follow that path.
|
||||
|
||||
## Step 6: Continuous Learning and Career Development
|
||||
|
||||
The analytics industry is constantly evolving, and your professional growth must keep up accordingly. Continuous learning is probably one of the only ways to ensure you stay ahead of emerging trends, refine your existing skills, and prepare for more advanced roles.
|
||||
|
||||
### Lifelong Learning and Advanced Skills
|
||||
|
||||
You should embrace a mindset of lifelong learning by deepening your technical expertise over time. Accept that you'll never be done learning and revisit fundamental tools like SQL and master advanced features such as window functions and recursive queries.
|
||||
|
||||
Expand your proficiency in Python by exploring libraries like pandas for data manipulation and scikit-learn for machine learning workflows. If you prefer R, dive into packages like tidyverse for efficient data processing and ggplot2 for sophisticated visualizations.
|
||||
|
||||
Additionally, enroll in specialized courses on machine learning algorithms, cloud-based analytics platforms (e.g., AWS Redshift, Google BigQuery), and emerging open-source tools. Staying informed through industry blogs, podcasts, and research publications will help you hone your skills in both data science and data mining.
|
||||
|
||||
### Charting Your Career Path
|
||||
|
||||
Once you have a solid foundation in data analysis techniques, the next step is to start mapping out your career trajectory. In other words: where do you want to go?
|
||||
|
||||
Initially, you might specialize as a BI analyst, crafting interactive dashboards and KPI reports that inform strategic decisions.
|
||||
|
||||
Next, consider roles such as sales data analyst, where you'll focus on revenue analytics and customer behavior modeling, or healthcare analyst, tasked with evaluating patient outcomes and ensuring regulatory compliance.
|
||||
|
||||
As you gain experience, you might want to pivot toward senior data analyst or data scientist positions, taking on end-to-end projects that incorporate predictive modeling, anomaly detection, and advanced statistical analysis.
|
||||
|
||||
### Setting Goals and Measuring Progress
|
||||
|
||||
You can't know if you're moving in the right direction if you don't measure your progress. It's a very common mistake many new analysts make, and one you should try to avoid.
|
||||
|
||||
Define clear, measurable objectives to guide your learning journey. Set milestones—such as completing a certification, publishing a portfolio project, or mastering a new visualization tool (and celebrate each achievement once you get it).
|
||||
|
||||
Keep a learning journal or log within your portfolio to document projects, record the techniques applied, and reflect on lessons learned.
|
||||
|
||||
Regularly try to get feedback from peers and mentors through code reviews, presentations, or mock interviews to identify areas for improvement and validate your progress.
|
||||
|
||||
### Mentorship and Community Involvement
|
||||
|
||||
Long-term success in data analysis relies on strong professional relationships and community engagement. Continue participating in forums, meetups, and virtual conferences to exchange insights with both aspiring analysts and seasoned professionals.
|
||||
|
||||
Seek opportunities to mentor newcomers, contribute to open-source or community-driven data projects, and share your expertise through blog posts or lightning talks.
|
||||
|
||||
Teaching concepts such as data cleansing, analysis workflows, and visualization best practices not only reinforces your own knowledge but also establishes your reputation as a qualified data professional in the broader data analyst job market.
|
||||
|
||||
Try to incorporate these strategies into your routine; that way, you'll enhance your data analyst skills dynamically, showcase your commitment to growth, and position yourself for roles with greater responsibility and impact.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Embarking on the path of how to become a data analyst with no experience may seem challenging, yes, but by leveraging structured learning pathways like the [Data Analyst Roadmap](https://roadmap.sh/data-analyst) and our [Mastering SQL course](https://roadmap.sh/courses/sql), you'll build the core technical foundation.
|
||||
|
||||
Complementing these tools with thoughtfully chosen data analysis projects in your portfolio will validate your practical skills and demonstrate your ability to extract actionable insights from complex datasets (which is the end goal of a good data analyst).
|
||||
|
||||
Beyond technical proficiency, remember that confidence and communication are equally critical. Whether you're preparing for your first entry-level data analyst interview or collaborating as a junior data analyst on real-world projects, articulating your data analysis process will set you apart.
|
||||
|
||||
Practical experiences, such as internships or community-driven challenges, will further reinforce your résumé and show your commitment to continuous growth in the analytics industry.
|
||||
|
||||
Every day, countless developers and analysts successfully transition into data roles by following these strategies.
|
||||
|
||||
Now it's your turn: take the first step, mapping out your learning journey, and launching your own data analytics projects. Your journey from aspiring analyst to qualified data professional starts today!
|
||||
|
||||